 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Examining System-Level Correlations of Automatic Summarization Evaluation Metrics
Apr 21, 2022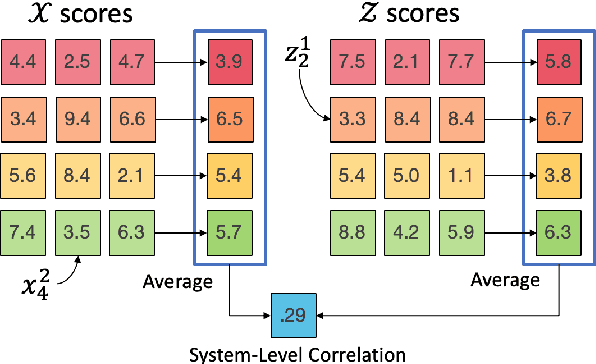
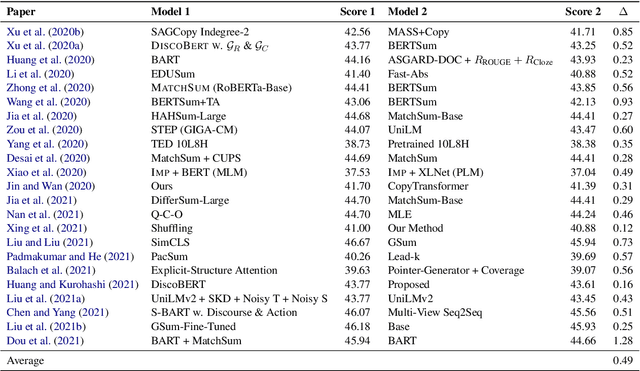
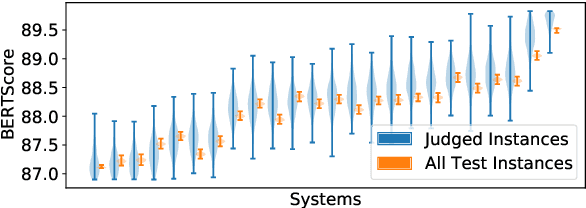
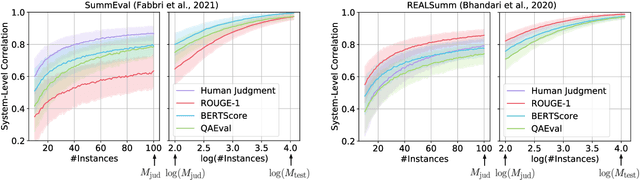
How reliably an automatic summarization evaluation metric replicates human judgments of summary quality is quantified by system-level correlations. We identify two ways in which the definition of the system-level correlation is inconsistent with how metrics are used to evaluate systems in practice and propose changes to rectify this disconnect. First, we calculate the system score for an automatic metric using the full test set instead of the subset of summaries judged by humans, which is currently standard practice. We demonstrate how this small change leads to more precise estimates of system-level correlations. Second, we propose to calculate correlations only on pairs of systems that are separated by small differences in automatic scores which are commonly observed in practice. This allows us to demonstrate that our best estimate of the correlation of ROUGE to human judgments is near 0 in realistic scenarios. The results from the analyses point to the need to collect more high-quality human judgments and to improve automatic metrics when differences in system scores are small.
Benchmarking Answer Verification Methods for Question Answering-Based Summarization Evaluation Metrics
Apr 21, 2022
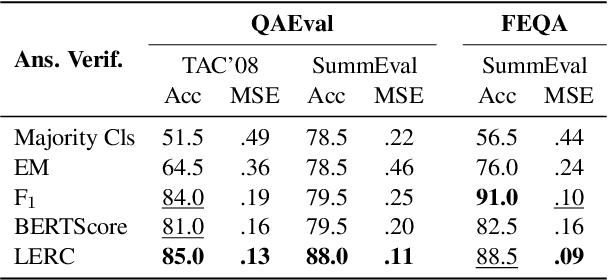
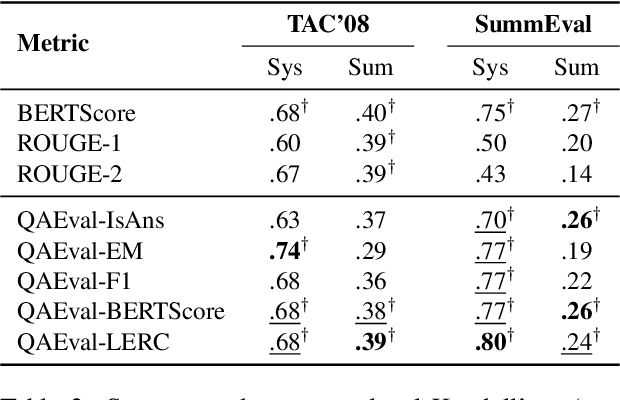
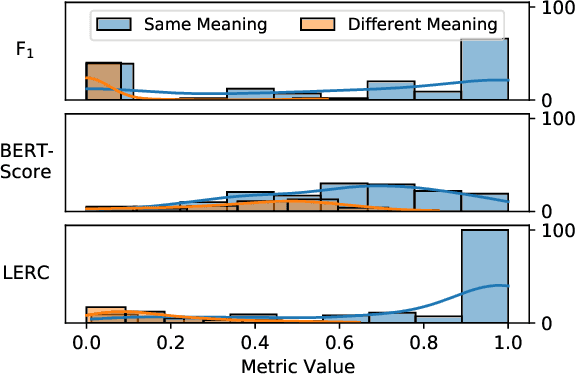
Question answering-based summarization evaluation metrics must automatically determine whether the QA model's prediction is correct or not, a task known as answer verification. In this work, we benchmark the lexical answer verification methods which have been used by current QA-based metrics as well as two more sophisticated text comparison methods, BERTScore and LERC. We find that LERC out-performs the other methods in some settings while remaining statistically indistinguishable from lexical overlap in others. However, our experiments reveal that improved verification performance does not necessarily translate to overall QA-based metric quality: In some scenarios, using a worse verification method -- or using none at all -- has comparable performance to using the best verification method, a result that we attribute to properties of the datasets.
Label Semantic Aware Pre-training for Few-shot Text Classification
Apr 14, 2022
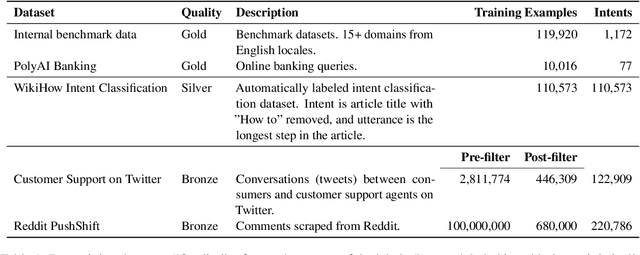
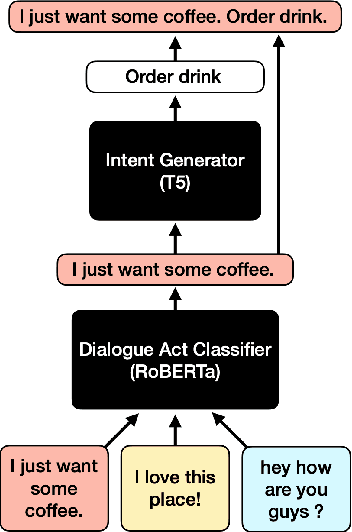
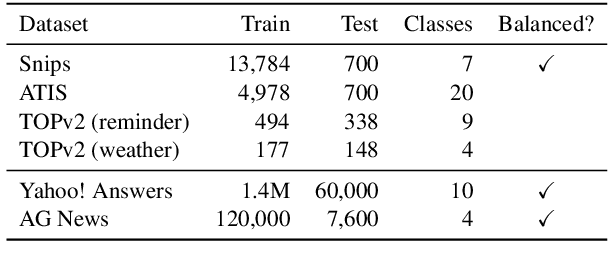
In text classification tasks, useful information is encoded in the label names. Label semantic aware systems have leveraged this information for improved text classification performance during fine-tuning and prediction. However, use of label-semantics during pre-training has not been extensively explored. We therefore propose Label Semantic Aware Pre-training (LSAP) to improve the generalization and data efficiency of text classification systems. LSAP incorporates label semantics into pre-trained generative models (T5 in our case) by performing secondary pre-training on labeled sentences from a variety of domains. As domain-general pre-training requires large amounts of data, we develop a filtering and labeling pipeline to automatically create sentence-label pairs from unlabeled text. We perform experiments on intent (ATIS, Snips, TOPv2) and topic classification (AG News, Yahoo! Answers). LSAP obtains significant accuracy improvements over state-of-the-art models for few-shot text classification while maintaining performance comparable to state of the art in high-resource settings.
There is a Time and Place for Reasoning Beyond the Image
Mar 28, 2022
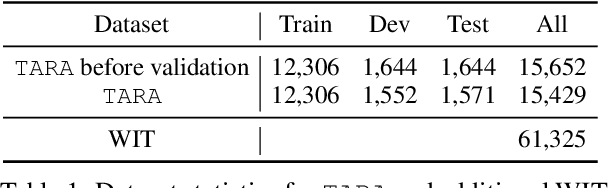

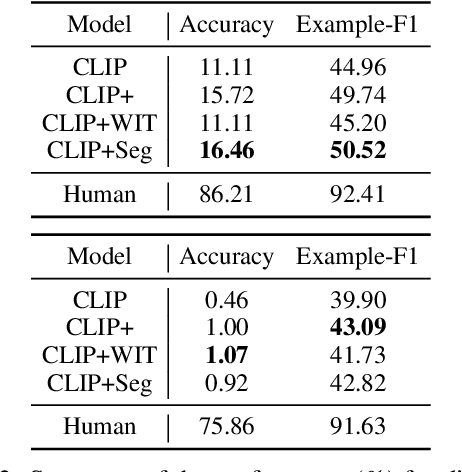
Images are often more significant than only the pixels to human eyes, as we can infer, associate, and reason with contextual information from other sources to establish a more complete picture. For example, in Figure 1, we can find a way to identify the news articles related to the picture through segment-wise understandings of the signs, the buildings, the crowds, and more. This reasoning could provide the time and place the image was taken, which will help us in subsequent tasks, such as automatic storyline construction, correction of image source in intended effect photographs, and upper-stream processing such as image clustering for certain location or time. In this work, we formulate this problem and introduce TARA: a dataset with 16k images with their associated news, time, and location, automatically extracted from New York Times, and an additional 61k examples as distant supervision from WIT. On top of the extractions, we present a crowdsourced subset in which we believe it is possible to find the images' spatio-temporal information for evaluation purpose. We show that there exists a $70\%$ gap between a state-of-the-art joint model and human performance, which is slightly filled by our proposed model that uses segment-wise reasoning, motivating higher-level vision-language joint models that can conduct open-ended reasoning with world knowledge. The data and code are publicly available at https://github.com/zeyofu/TARA.
DQ-BART: Efficient Sequence-to-Sequence Model via Joint Distillation and Quantization
Mar 21, 2022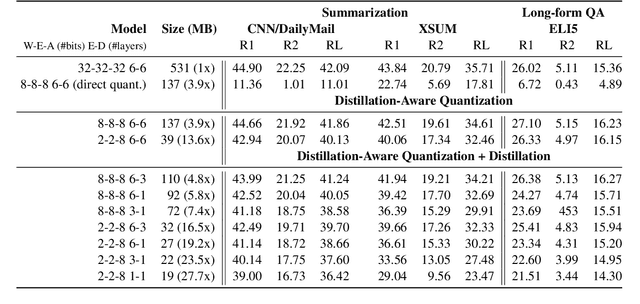
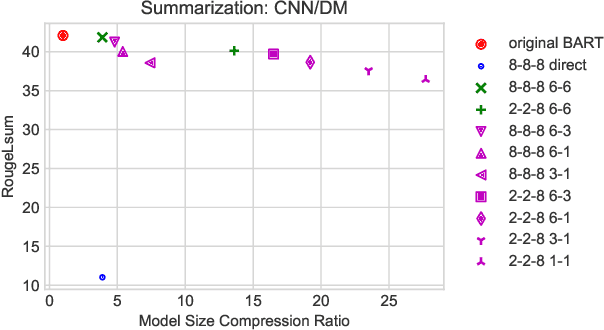
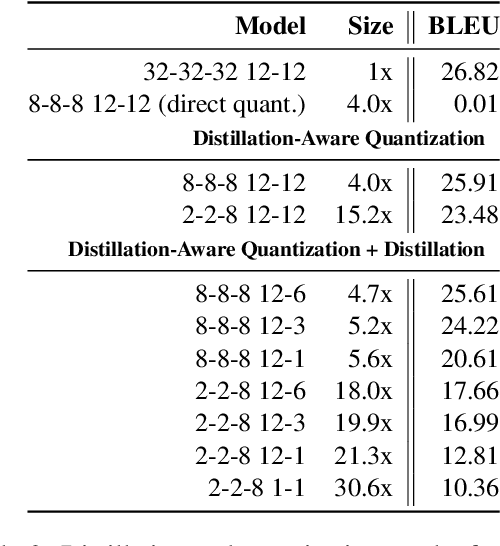
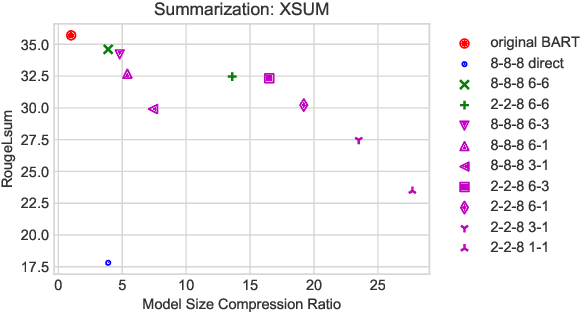
Large-scale pre-trained sequence-to-sequence models like BART and T5 achieve state-of-the-art performance on many generative NLP tasks. However, such models pose a great challenge in resource-constrained scenarios owing to their large memory requirements and high latency. To alleviate this issue, we propose to jointly distill and quantize the model, where knowledge is transferred from the full-precision teacher model to the quantized and distilled low-precision student model. Empirical analyses show that, despite the challenging nature of generative tasks, we were able to achieve a 16.5x model footprint compression ratio with little performance drop relative to the full-precision counterparts on multiple summarization and QA datasets. We further pushed the limit of compression ratio to 27.7x and presented the performance-efficiency trade-off for generative tasks using pre-trained models. To the best of our knowledge, this is the first work aiming to effectively distill and quantize sequence-to-sequence pre-trained models for language generation tasks.
Cross-modal Map Learning for Vision and Language Navigation
Mar 21, 2022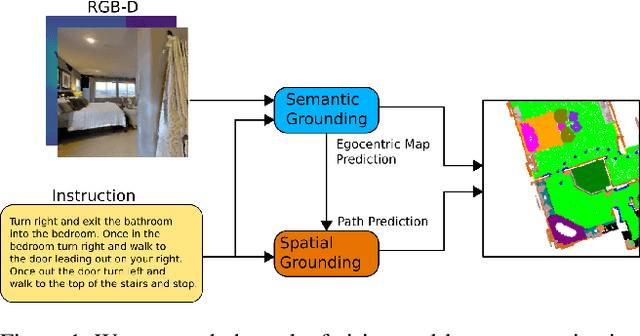
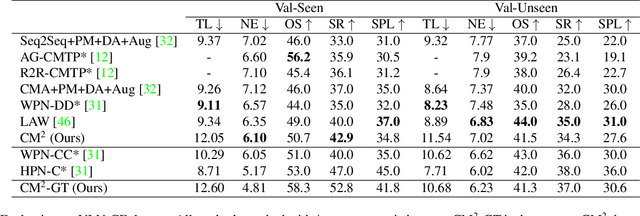
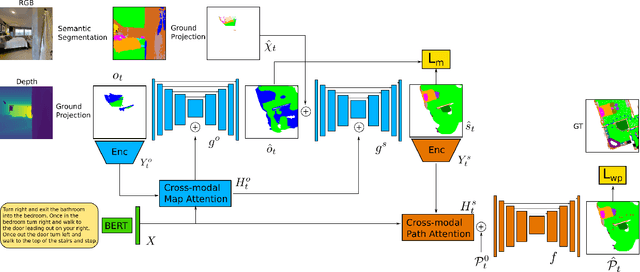
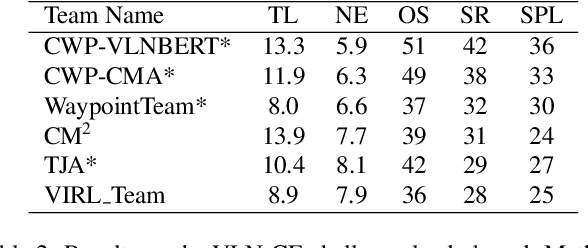
We consider the problem of Vision-and-Language Navigation (VLN). The majority of current methods for VLN are trained end-to-end using either unstructured memory such as LSTM, or using cross-modal attention over the egocentric observations of the agent. In contrast to other works, our key insight is that the association between language and vision is stronger when it occurs in explicit spatial representations. In this work, we propose a cross-modal map learning model for vision-and-language navigation that first learns to predict the top-down semantics on an egocentric map for both observed and unobserved regions, and then predicts a path towards the goal as a set of waypoints. In both cases, the prediction is informed by the language through cross-modal attention mechanisms. We experimentally test the basic hypothesis that language-driven navigation can be solved given a map, and then show competitive results on the full VLN-CE benchmark.
Label Semantics for Few Shot Named Entity Recognition
Mar 16, 2022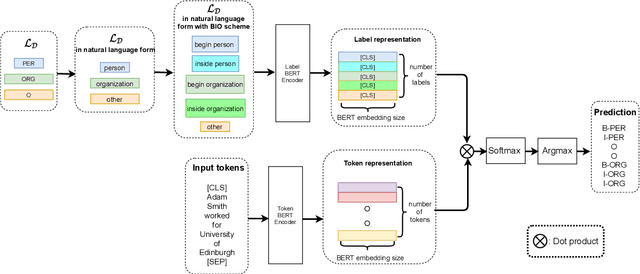
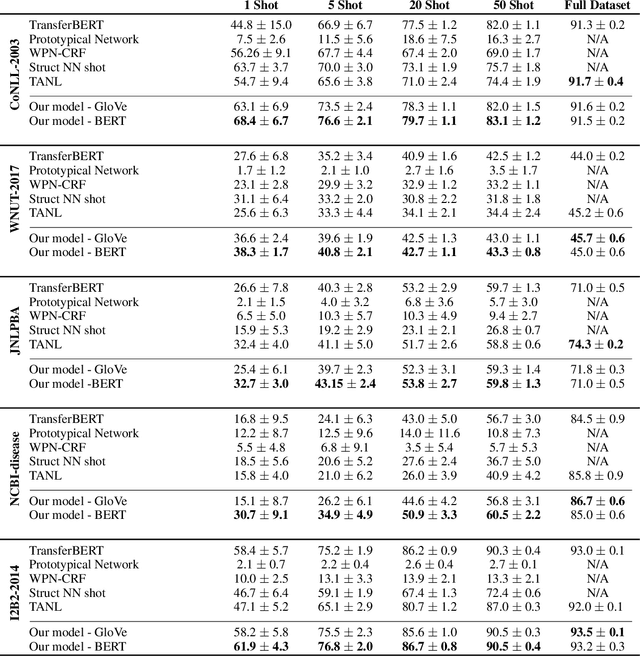
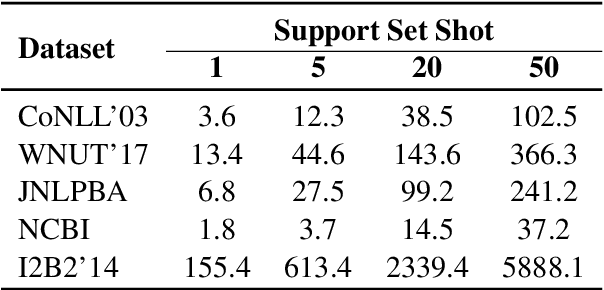
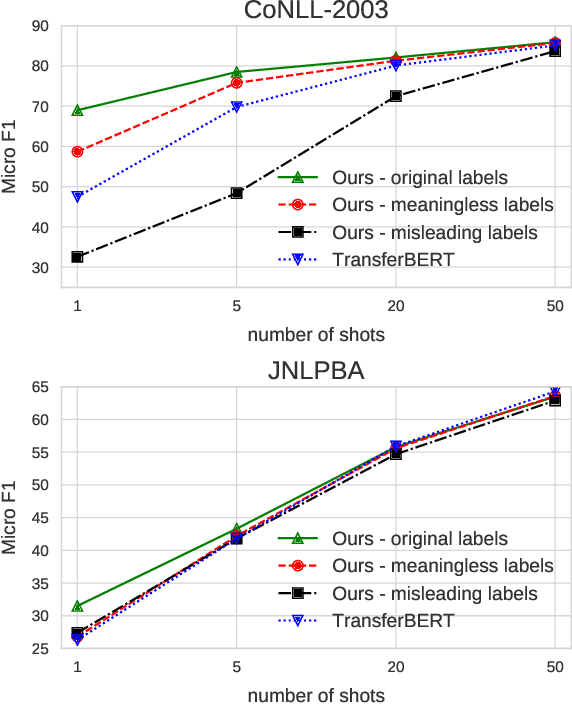
We study the problem of few shot learning for named entity recognition. Specifically, we leverage the semantic information in the names of the labels as a way of giving the model additional signal and enriched priors. We propose a neural architecture that consists of two BERT encoders, one to encode the document and its tokens and another one to encode each of the labels in natural language format. Our model learns to match the representations of named entities computed by the first encoder with label representations computed by the second encoder. The label semantics signal is shown to support improved state-of-the-art results in multiple few shot NER benchmarks and on-par performance in standard benchmarks. Our model is especially effective in low resource settings.
Understanding Robust Generalization in Learning Regular Languages
Feb 20, 2022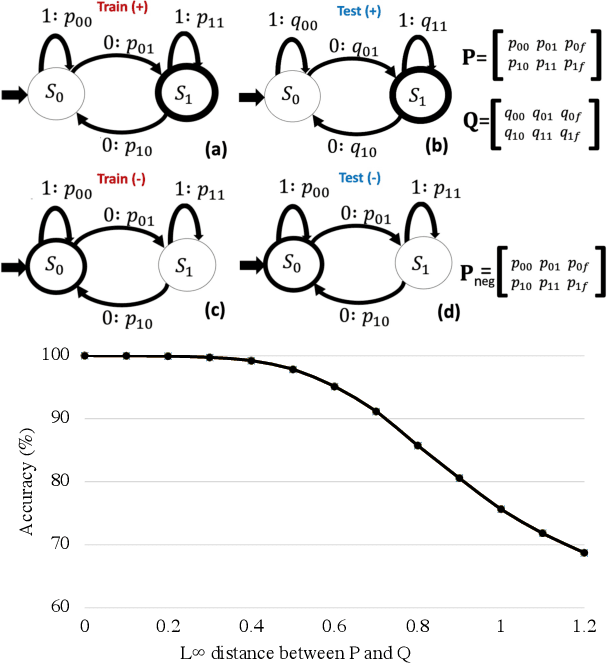
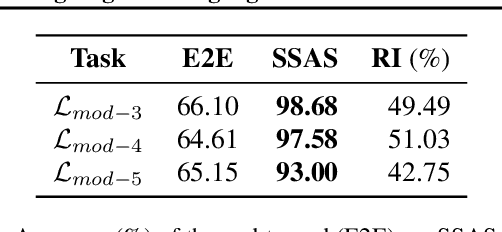
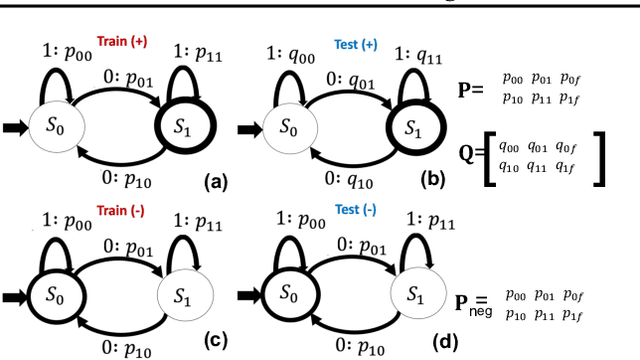
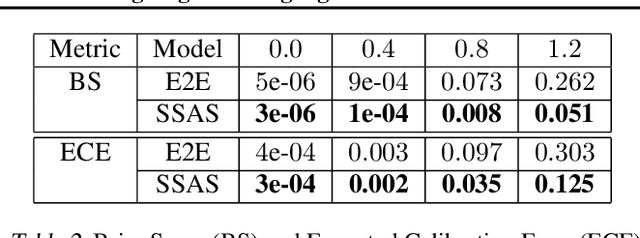
A key feature of human intelligence is the ability to generalize beyond the training distribution, for instance, parsing longer sentences than seen in the past. Currently, deep neural networks struggle to generalize robustly to such shifts in the data distribution. We study robust generalization in the context of using recurrent neural networks (RNNs) to learn regular languages. We hypothesize that standard end-to-end modeling strategies cannot generalize well to systematic distribution shifts and propose a compositional strategy to address this. We compare an end-to-end strategy that maps strings to labels with a compositional strategy that predicts the structure of the deterministic finite-state automaton (DFA) that accepts the regular language. We theoretically prove that the compositional strategy generalizes significantly better than the end-to-end strategy. In our experiments, we implement the compositional strategy via an auxiliary task where the goal is to predict the intermediate states visited by the DFA when parsing a string. Our empirical results support our hypothesis, showing that auxiliary tasks can enable robust generalization. Interestingly, the end-to-end RNN generalizes significantly better than the theoretical lower bound, suggesting that it is able to achieve at least some degree of robust generalization.
Causal Inference Principles for Reasoning about Commonsense Causality
Jan 31, 2022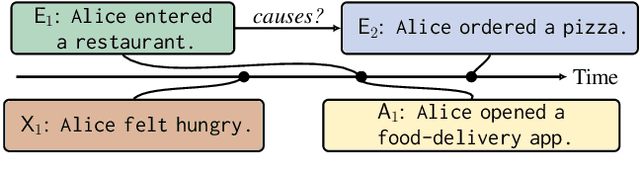
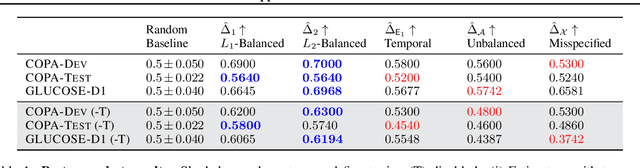
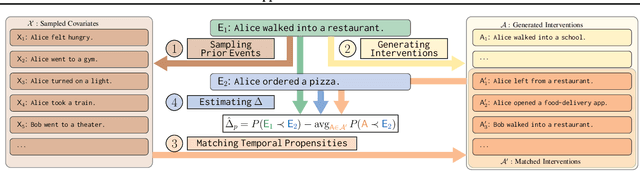
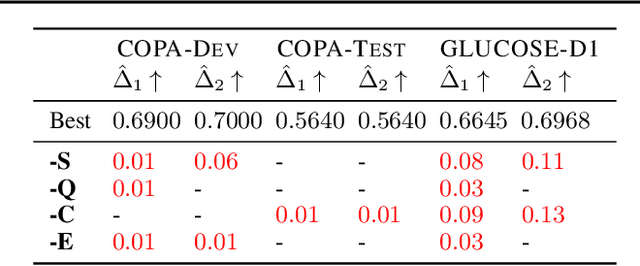
Commonsense causality reasoning (CCR) aims at identifying plausible causes and effects in natural language descriptions that are deemed reasonable by an average person. Although being of great academic and practical interest, this problem is still shadowed by the lack of a well-posed theoretical framework; existing work usually relies on deep language models wholeheartedly, and is potentially susceptible to confounding co-occurrences. Motivated by classical causal principles, we articulate the central question of CCR and draw parallels between human subjects in observational studies and natural languages to adopt CCR to the potential-outcomes framework, which is the first such attempt for commonsense tasks. We propose a novel framework, ROCK, to Reason O(A)bout Commonsense K(C)ausality, which utilizes temporal signals as incidental supervision, and balances confounding effects using temporal propensities that are analogous to propensity scores. The ROCK implementation is modular and zero-shot, and demonstrates good CCR capabilities on various datasets.
Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval
Jan 28, 2022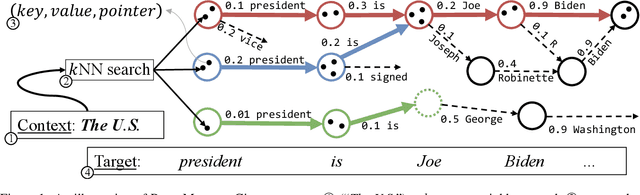
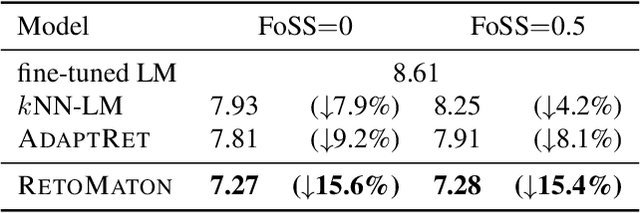
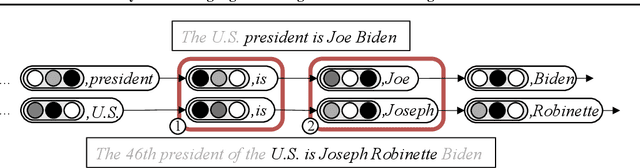

Retrieval-based language models (R-LM) model the probability of natural language text by combining a standard language model (LM) with examples retrieved from an external datastore at test time. While effective, a major bottleneck of using these models in practice is the computationally costly datastore search, which can be performed as frequently as every time step. In this paper, we present RetoMaton -- retrieval automaton -- which approximates the datastore search, based on (1) clustering of entries into "states", and (2) state transitions from previous entries. This effectively results in a weighted finite automaton built on top of the datastore, instead of representing the datastore as a flat list. The creation of the automaton is unsupervised, and a RetoMaton can be constructed from any text collection: either the original training corpus or from another domain. Traversing this automaton at inference time, in parallel to the LM inference, reduces its perplexity, or alternatively saves up to 83% of the nearest neighbor searches over kNN-LM (Khandelwal et al., 2020), without hurting perplexity.