 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-DG: A Multi-Source Domain Generalization Framework for Motor Imagery EEG Classification
Nov 09, 2023



Motor imagery EEG classification plays a crucial role in non-invasive Brain-Computer Interface (BCI) research. However, the classification is affected by the non-stationarity and individual variations of EEG signals. Simply pooling EEG data with different statistical distributions to train a classification model can severely degrade the generalization performance. To address this issue, the existing methods primarily focus on domain adaptation, which requires access to the target data during training. This is unrealistic in many EEG application scenarios. In this paper, we propose a novel multi-source domain generalization framework called EEG-DG, which leverages multiple source domains with different statistical distributions to build generalizable models on unseen target EEG data. We optimize both the marginal and conditional distributions to ensure the stability of the joint distribution across source domains and extend it to a multi-source domain generalization framework to achieve domain-invariant feature representation, thereby alleviating calibration efforts. Systematic experiments on a simulative dataset and BCI competition datasets IV-2a and IV-2b demonstrate the superiority of our proposed EEG-DG over state-of-the-art methods. Specifically, EEG-DG achieves an average classification accuracy/kappa value of 81.79%/0.7572 and 87.12%/0.7424 on datasets IV-2a and IV-2b, respectively, which even outperforms some domain adaptation methods. Our code is available at https://github.com/XC-ZhongHIT/EEG-DG for free download and evaluation.
Teacher-Student Architecture for Knowledge Distillation: A Survey
Aug 08, 2023



Although Deep neural networks (DNNs) have shown a strong capacity to solve large-scale problems in many areas, such DNNs are hard to be deployed in real-world systems due to their voluminous parameters. To tackle this issue, Teacher-Student architectures were proposed, where simple student networks with a few parameters can achieve comparable performance to deep teacher networks with many parameters. Recently, Teacher-Student architectures have been effectively and widely embraced on various knowledge distillation (KD) objectives, including knowledge compression, knowledge expansion, knowledge adaptation, and knowledge enhancement. With the help of Teacher-Student architectures, current studies are able to achieve multiple distillation objectives through lightweight and generalized student networks. Different from existing KD surveys that primarily focus on knowledge compression, this survey first explores Teacher-Student architectures across multiple distillation objectives. This survey presents an introduction to various knowledge representations and their corresponding optimization objectives. Additionally, we provide a systematic overview of Teacher-Student architectures with representative learning algorithms and effective distillation schemes. This survey also summarizes recent applications of Teacher-Student architectures across multiple purposes, including classification, recognition, generation, ranking, and regression. Lastly, potential research directions in KD are investigated, focusing on architecture design, knowledge quality, and theoretical studies of regression-based learning, respectively. Through this comprehensive survey, industry practitioners and the academic community can gain valuable insights and guidelines for effectively designing, learning, and applying Teacher-Student architectures on various distillation objectives.
Reducing the gap between streaming and non-streaming Transducer-based ASR by adaptive two-stage knowledge distillation
Jun 27, 2023Transducer is one of the mainstream frameworks for streaming speech recognition. There is a performance gap between the streaming and non-streaming transducer models due to limited context. To reduce this gap, an effective way is to ensure that their hidden and output distributions are consistent, which can be achieved by hierarchical knowledge distillation. However, it is difficult to ensure the distribution consistency simultaneously because the learning of the output distribution depends on the hidden one. In this paper, we propose an adaptive two-stage knowledge distillation method consisting of hidden layer learning and output layer learning. In the former stage, we learn hidden representation with full context by applying mean square error loss function. In the latter stage, we design a power transformation based adaptive smoothness method to learn stable output distribution. It achieved 19\% relative reduction in word error rate, and a faster response for the first token compared with the original streaming model in LibriSpeech corpus.
Ternary Quantization: A Survey
Mar 02, 2023
Inference time, model size, and accuracy are critical for deploying deep neural network models. Numerous research efforts have been made to compress neural network models with faster inference and higher accuracy. Pruning and quantization are mainstream methods to this end. During model quantization, converting individual float values of layer weights to low-precision ones can substantially reduce the computational overhead and improve the inference speed. Many quantization methods have been studied, for example, vector quantization, low-bit quantization, and binary/ternary quantization. This survey focuses on ternary quantization. We review the evolution of ternary quantization and investigate the relationships among existing ternary quantization methods from the perspective of projection function and optimization methods.
Pruning On-the-Fly: A Recoverable Pruning Method without Fine-tuning
Dec 24, 2022



Most existing pruning works are resource-intensive, requiring retraining or fine-tuning of the pruned models for accuracy. We propose a retraining-free pruning method based on hyperspherical learning and loss penalty terms. The proposed loss penalty term pushes some of the model weights far from zero, while the rest weight values are pushed near zero and can be safely pruned with no need for retraining and a negligible accuracy drop. In addition, our proposed method can instantly recover the accuracy of a pruned model by replacing the pruned values with their mean value. Our method obtains state-of-the-art results in retraining-free pruning and is evaluated on ResNet-18/50 and MobileNetV2 with ImageNet dataset. One can easily get a 50\% pruned ResNet18 model with a 0.47\% accuracy drop. With fine-tuning, the experiment results show that our method can significantly boost the accuracy of the pruned models compared with existing works. For example, the accuracy of a 70\% pruned (except the first convolutional layer) MobileNetV2 model only drops 3.5\%, much less than the 7\% $\sim$ 10\% accuracy drop with conventional methods.
Hyperspherical Quantization: Toward Smaller and More Accurate Models
Dec 24, 2022



Model quantization enables the deployment of deep neural networks under resource-constrained devices. Vector quantization aims at reducing the model size by indexing model weights with full-precision embeddings, i.e., codewords, while the index needs to be restored to 32-bit during computation. Binary and other low-precision quantization methods can reduce the model size up to 32$\times$, however, at the cost of a considerable accuracy drop. In this paper, we propose an efficient framework for ternary quantization to produce smaller and more accurate compressed models. By integrating hyperspherical learning, pruning and reinitialization, our proposed Hyperspherical Quantization (HQ) method reduces the cosine distance between the full-precision and ternary weights, thus reducing the bias of the straight-through gradient estimator during ternary quantization. Compared with existing work at similar compression levels ($\sim$30$\times$, $\sim$40$\times$), our method significantly improves the test accuracy and reduces the model size.
Hyperspherical Loss-Aware Ternary Quantization
Dec 24, 2022



Most of the existing works use projection functions for ternary quantization in discrete space. Scaling factors and thresholds are used in some cases to improve the model accuracy. However, the gradients used for optimization are inaccurate and result in a notable accuracy gap between the full precision and ternary models. To get more accurate gradients, some works gradually increase the discrete portion of the full precision weights in the forward propagation pass, e.g., using temperature-based Sigmoid function. Instead of directly performing ternary quantization in discrete space, we push full precision weights close to ternary ones through regularization term prior to ternary quantization. In addition, inspired by the temperature-based method, we introduce a re-scaling factor to obtain more accurate gradients by simulating the derivatives of Sigmoid function. The experimental results show that our method can significantly improve the accuracy of ternary quantization in both image classification and object detection tasks.
Teacher-Student Architecture for Knowledge Learning: A Survey
Oct 28, 2022



Although Deep Neural Networks (DNNs) have shown a strong capacity to solve large-scale problems in many areas, such DNNs with voluminous parameters are hard to be deployed in a real-time system. To tackle this issue, Teacher-Student architectures were first utilized in knowledge distillation, where simple student networks can achieve comparable performance to deep teacher networks. Recently, Teacher-Student architectures have been effectively and widely embraced on various knowledge learning objectives, including knowledge distillation, knowledge expansion, knowledge adaption, and multi-task learning. With the help of Teacher-Student architectures, current studies are able to achieve multiple knowledge-learning objectives through lightweight and effective student networks. Different from the existing knowledge distillation surveys, this survey detailedly discusses Teacher-Student architectures with multiple knowledge learning objectives. In addition, we systematically introduce the knowledge construction and optimization process during the knowledge learning and then analyze various Teacher-Student architectures and effective learning schemes that have been leveraged to learn representative and robust knowledge. This paper also summarizes the latest applications of Teacher-Student architectures based on different purposes (i.e., classification, recognition, and generation). Finally, the potential research directions of knowledge learning are investigated on the Teacher-Student architecture design, the quality of knowledge, and the theoretical studies of regression-based learning, respectively. With this comprehensive survey, both industry practitioners and the academic community can learn insightful guidelines about Teacher-Student architectures on multiple knowledge learning objectives.
Flexible Alignment Super-Resolution Network for Multi-Contrast MRI
Oct 07, 2022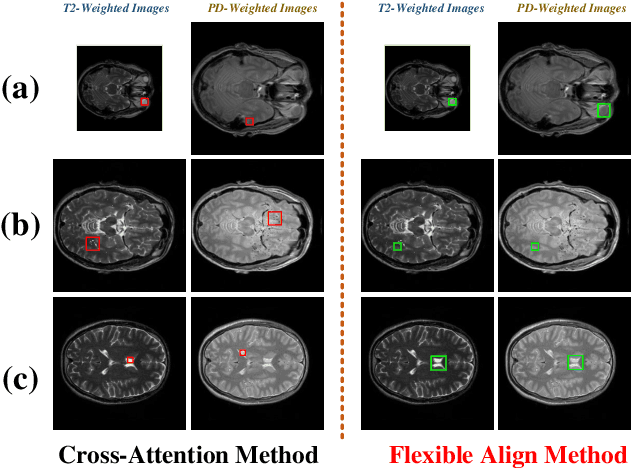
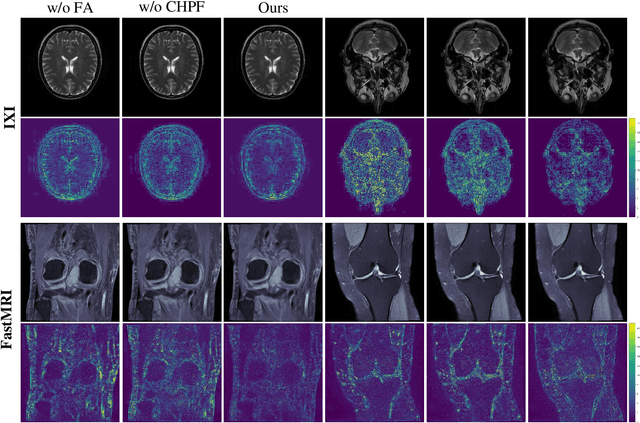
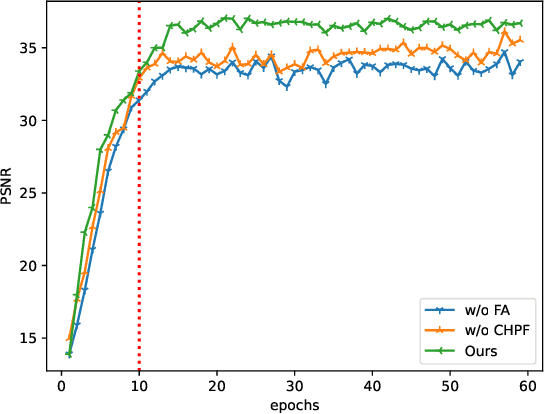
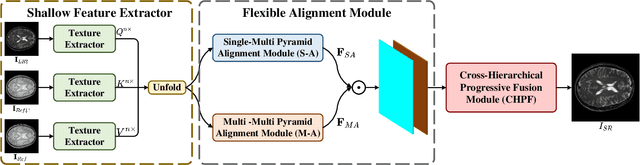
Magnetic resonance images play an essential role in clinical diagnosis by acquiring the structural information of biological tissue. However, during acquiring magnetic resonance images, patients have to endure physical and psychological discomfort, including irritating noise and acute anxiety. To make the patient feel cozier, technically, it will reduce the retention time that patients stay in the strong magnetic field at the expense of image quality. Therefore, Super-Resolution plays a crucial role in preprocessing the low-resolution images for more precise medical analysis. In this paper, we propose the Flexible Alignment Super-Resolution Network (FASR-Net) for multi-contrast magnetic resonance images Super-Resolution. The core of multi-contrast SR is to match the patches of low-resolution and reference images. However, the inappropriate foreground scale and patch size of multi-contrast MRI sometimes lead to the mismatch of patches. To tackle this problem, the Flexible Alignment module is proposed to endow receptive fields with flexibility. Flexible Alignment module contains two parts: (1) The Single-Multi Pyramid Alignmet module serves for low-resolution and reference image with different scale. (2) The Multi-Multi Pyramid Alignment module serves for low-resolution and reference image with the same scale. Extensive experiments on the IXI and FastMRI datasets demonstrate that the FASR-Net outperforms the existing state-of-the-art approaches. In addition, by comparing the reconstructed images with the counterparts obtained by the existing algorithms, our method could retain more textural details by leveraging multi-contrast images.
A Matrix Decomposition Model Based on Feature Factors in Movie Recommendation System
Jun 12, 2022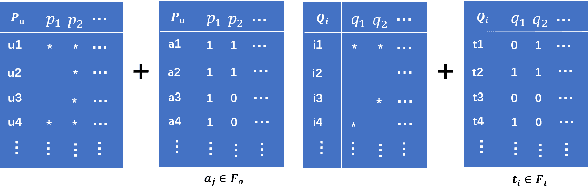
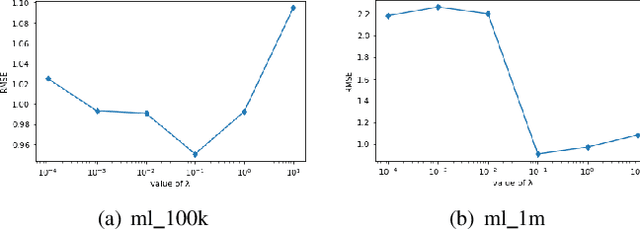
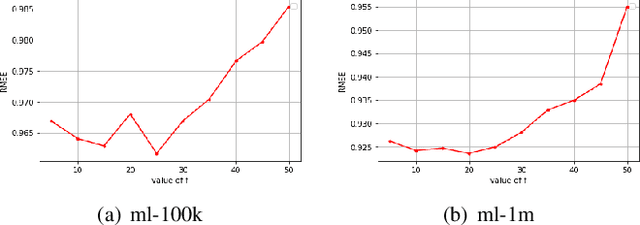
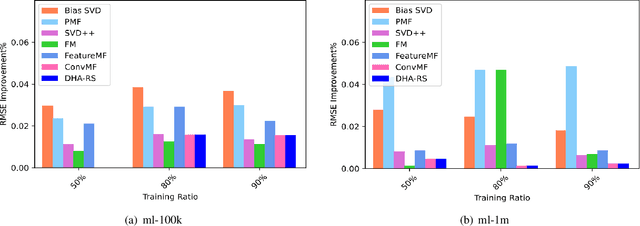
Matrix Factorization (MF) is one of the most successful Collaborative Filtering (CF) techniques used in recommender systems due to its effectiveness and ability to deal with very large user-item rating matrix. Among them, matrix decomposition method mainly uses the interactions records between users and items to predict ratings. Based on the characteristic attributes of items and users, this paper proposes a UISVD++ model that fuses the type attributes of movies and the age attributes of users into MF framework. Project and user representations in MF are enriched by projecting each user's age attribute and each movie's type attribute into the same potential factor space as users and items. Finally, the MovieLens-100K and MovieLens-1M datasets were used to compare with the traditional SVD++ and other models. The results show that the proposed model can achieve the best recommendation performance and better predict user ratings under all backgrounds.