 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpochX: Building the Infrastructure for an Emergent Agent Civilization
Mar 28, 2026General-purpose technologies reshape economies less by improving individual tools than by enabling new ways to organize production and coordination. We believe AI agents are approaching a similar inflection point: as foundation models make broad task execution and tool use increasingly accessible, the binding constraint shifts from raw capability to how work is delegated, verified, and rewarded at scale. We introduce EpochX, a credits-native marketplace infrastructure for human-agent production networks. EpochX treats humans and agents as peer participants who can post tasks or claim them. Claimed tasks can be decomposed into subtasks and executed through an explicit delivery workflow with verification and acceptance. Crucially, EpochX is designed so that each completed transaction can produce reusable ecosystem assets, including skills, workflows, execution traces, and distilled experience. These assets are stored with explicit dependency structure, enabling retrieval, composition, and cumulative improvement over time. EpochX also introduces a native credit mechanism to make participation economically viable under real compute costs. Credits lock task bounties, budget delegation, settle rewards upon acceptance, and compensate creators when verified assets are reused. By formalizing the end-to-end transaction model together with its asset and incentive layers, EpochX reframes agentic AI as an organizational design problem: building infrastructures where verifiable work leaves persistent, reusable artifacts, and where value flows support durable human-agent collaboration.
Rethinking Token Pruning for Historical Screenshots in GUI Visual Agents: Semantic, Spatial, and Temporal Perspectives
Mar 27, 2026In recent years, GUI visual agents built upon Multimodal Large Language Models (MLLMs) have demonstrated strong potential in navigation tasks. However, high-resolution GUI screenshots produce a large number of visual tokens, making the direct preservation of complete historical information computationally expensive. In this paper, we conduct an empirical study on token pruning for historical screenshots in GUI scenarios and distill three practical insights that are crucial for designing effective pruning strategies. First, we observe that GUI screenshots exhibit a distinctive foreground-background semantic composition. To probe this property, we apply a simple edge-based separation to partition screenshots into foreground and background regions. Surprisingly, we find that, contrary to the common assumption that background areas have little semantic value, they effectively capture interface-state transitions, thereby providing auxiliary cues for GUI reasoning. Second, compared with carefully designed pruning strategies, random pruning possesses an inherent advantage in preserving spatial structure, enabling better performance under the same computational budget. Finally, we observe that GUI Agents exhibit a recency effect similar to human cognition: by allocating larger token budgets to more recent screenshots and heavily compressing distant ones, we can significantly reduce computational cost while maintaining nearly unchanged performance. These findings offer new insights and practical guidance for the design of efficient GUI visual agents.
Deep Learning Methods for Lung Cancer Segmentation in Whole-slide Histopathology Images -- the ACDC@LungHP Challenge 2019
Aug 21, 2020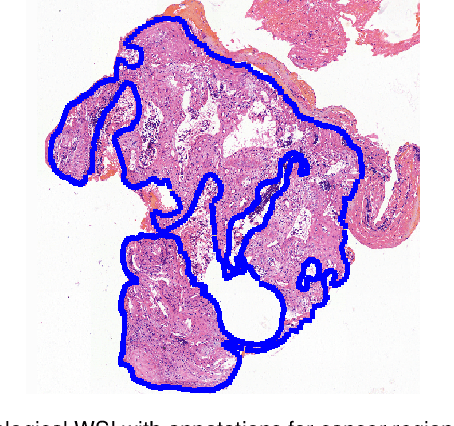
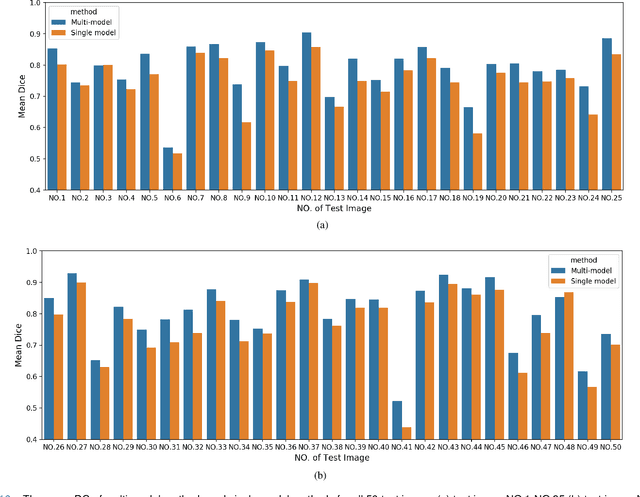
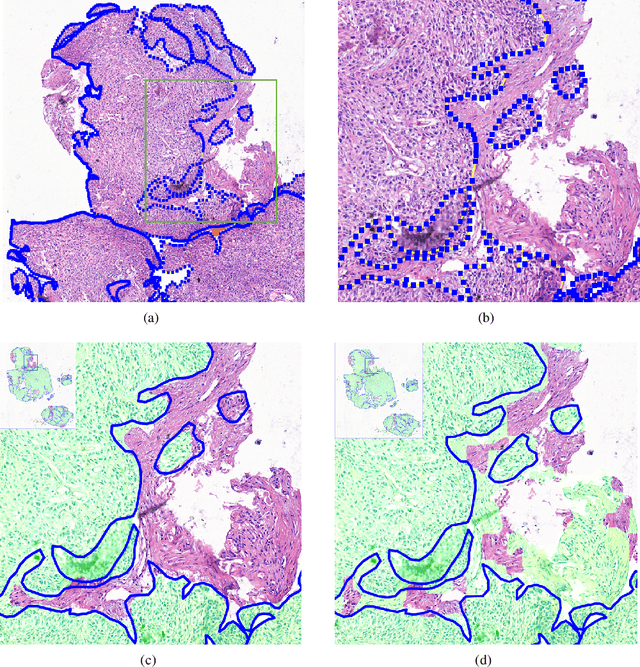

Accurate segmentation of lung cancer in pathology slides is a critical step in improving patient care. We proposed the ACDC@LungHP (Automatic Cancer Detection and Classification in Whole-slide Lung Histopathology) challenge for evaluating different computer-aided diagnosis (CADs) methods on the automatic diagnosis of lung cancer. The ACDC@LungHP 2019 focused on segmentation (pixel-wise detection) of cancer tissue in whole slide imaging (WSI), using an annotated dataset of 150 training images and 50 test images from 200 patients. This paper reviews this challenge and summarizes the top 10 submitted methods for lung cancer segmentation. All methods were evaluated using the false positive rate, false negative rate, and DICE coefficient (DC). The DC ranged from 0.7354$\pm$0.1149 to 0.8372$\pm$0.0858. The DC of the best method was close to the inter-observer agreement (0.8398$\pm$0.0890). All methods were based on deep learning and categorized into two groups: multi-model method and single model method. In general, multi-model methods were significantly better ($\textit{p}$<$0.01$) than single model methods, with mean DC of 0.7966 and 0.7544, respectively. Deep learning based methods could potentially help pathologists find suspicious regions for further analysis of lung cancer in WSI.