 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Specific Retrieval-Augmented Generation Using Vector Stores, Knowledge Graphs, and Tensor Factorization
Oct 03, 2024



Large Language Models (LLMs) are pre-trained on large-scale corpora and excel in numerous general natural language processing (NLP) tasks, such as question answering (QA). Despite their advanced language capabilities, when it comes to domain-specific and knowledge-intensive tasks, LLMs suffer from hallucinations, knowledge cut-offs, and lack of knowledge attributions. Additionally, fine tuning LLMs' intrinsic knowledge to highly specific domains is an expensive and time consuming process. The retrieval-augmented generation (RAG) process has recently emerged as a method capable of optimization of LLM responses, by referencing them to a predetermined ontology. It was shown that using a Knowledge Graph (KG) ontology for RAG improves the QA accuracy, by taking into account relevant sub-graphs that preserve the information in a structured manner. In this paper, we introduce SMART-SLIC, a highly domain-specific LLM framework, that integrates RAG with KG and a vector store (VS) that store factual domain specific information. Importantly, to avoid hallucinations in the KG, we build these highly domain-specific KGs and VSs without the use of LLMs, but via NLP, data mining, and nonnegative tensor factorization with automatic model selection. Pairing our RAG with a domain-specific: (i) KG (containing structured information), and (ii) VS (containing unstructured information) enables the development of domain-specific chat-bots that attribute the source of information, mitigate hallucinations, lessen the need for fine-tuning, and excel in highly domain-specific question answering tasks. We pair SMART-SLIC with chain-of-thought prompting agents. The framework is designed to be generalizable to adapt to any specific or specialized domain. In this paper, we demonstrate the question answering capabilities of our framework on a corpus of scientific publications on malware analysis and anomaly detection.
Binary Bleed: Fast Distributed and Parallel Method for Automatic Model Selection
Jul 26, 2024



In several Machine Learning (ML) clustering and dimensionality reduction approaches, such as non-negative matrix factorization (NMF), RESCAL, and K-Means clustering, users must select a hyper-parameter k to define the number of clusters or components that yield an ideal separation of samples or clean clusters. This selection, while difficult, is crucial to avoid overfitting or underfitting the data. Several ML applications use scoring methods (e.g., Silhouette and Davies Boulding scores) to evaluate the cluster pattern stability for a specific k. The score is calculated for different trials over a range of k, and the ideal k is heuristically selected as the value before the model starts overfitting, indicated by a drop or increase in the score resembling an elbow curve plot. While the grid-search method can be used to accurately find a good k value, visiting a range of k can become time-consuming and computationally resource-intensive. In this paper, we introduce the Binary Bleed method based on binary search, which significantly reduces the k search space for these grid-search ML algorithms by truncating the target k values from the search space using a heuristic with thresholding over the scores. Binary Bleed is designed to work with single-node serial, single-node multi-processing, and distributed computing resources. In our experiments, we demonstrate the reduced search space gain over a naive sequential search of the ideal k and the accuracy of the Binary Bleed in identifying the correct k for NMFk, K-Means pyDNMFk, and pyDRESCALk with Silhouette and Davies Boulding scores. We make our implementation of Binary Bleed for the NMF algorithm available on GitHub.
Dialogue with Robots: Proposals for Broadening Participation and Research in the SLIVAR Community
Apr 01, 2024


The ability to interact with machines using natural human language is becoming not just commonplace, but expected. The next step is not just text interfaces, but speech interfaces and not just with computers, but with all machines including robots. In this paper, we chronicle the recent history of this growing field of spoken dialogue with robots and offer the community three proposals, the first focused on education, the second on benchmarks, and the third on the modeling of language when it comes to spoken interaction with robots. The three proposals should act as white papers for any researcher to take and build upon.
Cyber-Security Knowledge Graph Generation by Hierarchical Nonnegative Matrix Factorization
Mar 26, 2024Much of human knowledge in cybersecurity is encapsulated within the ever-growing volume of scientific papers. As this textual data continues to expand, the importance of document organization methods becomes increasingly crucial for extracting actionable insights hidden within large text datasets. Knowledge Graphs (KGs) serve as a means to store factual information in a structured manner, providing explicit, interpretable knowledge that includes domain-specific information from the cybersecurity scientific literature. One of the challenges in constructing a KG from scientific literature is the extraction of ontology from unstructured text. In this paper, we address this topic and introduce a method for building a multi-modal KG by extracting structured ontology from scientific papers. We demonstrate this concept in the cybersecurity domain. One modality of the KG represents observable information from the papers, such as the categories in which they were published or the authors. The second modality uncovers latent (hidden) patterns of text extracted through hierarchical and semantic non-negative matrix factorization (NMF), such as named entities, topics or clusters, and keywords. We illustrate this concept by consolidating more than two million scientific papers uploaded to arXiv into the cyber-domain, using hierarchical and semantic NMF, and by building a cyber-domain-specific KG.
Small Effect Sizes in Malware Detection? Make Harder Train/Test Splits!
Dec 25, 2023



Industry practitioners care about small improvements in malware detection accuracy because their models are deployed to hundreds of millions of machines, meaning a 0.1\% change can cause an overwhelming number of false positives. However, academic research is often restrained to public datasets on the order of ten thousand samples and is too small to detect improvements that may be relevant to industry. Working within these constraints, we devise an approach to generate a benchmark of configurable difficulty from a pool of available samples. This is done by leveraging malware family information from tools like AVClass to construct training/test splits that have different generalization rates, as measured by a secondary model. Our experiments will demonstrate that using a less accurate secondary model with disparate features is effective at producing benchmarks for a more sophisticated target model that is under evaluation. We also ablate against alternative designs to show the need for our approach.
DDxT: Deep Generative Transformer Models for Differential Diagnosis
Dec 02, 2023



Differential Diagnosis (DDx) is the process of identifying the most likely medical condition among the possible pathologies through the process of elimination based on evidence. An automated process that narrows a large set of pathologies down to the most likely pathologies will be of great importance. The primary prior works have relied on the Reinforcement Learning (RL) paradigm under the intuition that it aligns better with how physicians perform DDx. In this paper, we show that a generative approach trained with simpler supervised and self-supervised learning signals can achieve superior results on the current benchmark. The proposed Transformer-based generative network, named DDxT, autoregressively produces a set of possible pathologies, i.e., DDx, and predicts the actual pathology using a neural network. Experiments are performed using the DDXPlus dataset. In the case of DDx, the proposed network has achieved a mean accuracy of 99.82% and a mean F1 score of 0.9472. Additionally, mean accuracy reaches 99.98% with a mean F1 score of 0.9949 while predicting ground truth pathology. The proposed DDxT outperformed the previous RL-based approaches by a big margin. Overall, the automated Transformer-based DDx generative model has the potential to become a useful tool for a physician in times of urgency.
Measuring Equality in Machine Learning Security Defenses
Mar 01, 2023The machine learning security community has developed myriad defenses for evasion attacks over the past decade. An understudied question in that community is: for whom do these defenses defend? In this work, we consider some common approaches to defending learned systems and whether those approaches may offer unexpected performance inequities when used by different sub-populations. We outline simple parity metrics and a framework for analysis that can begin to answer this question through empirical results of the fairness implications of machine learning security methods. Many methods have been proposed that can cause direct harm, which we describe as biased vulnerability and biased rejection. Our framework and metric can be applied to robustly trained models, preprocessing-based methods, and rejection methods to capture behavior over security budgets. We identify a realistic dataset with a reasonable computational cost suitable for measuring the equality of defenses. Through a case study in speech command recognition, we show how such defenses do not offer equal protection for social subgroups and how to perform such analyses for robustness training, and we present a comparison of fairness between two rejection-based defenses: randomized smoothing and neural rejection. We offer further analysis of factors that correlate to equitable defenses to stimulate the future investigation of how to assist in building such defenses. To the best of our knowledge, this is the first work that examines the fairness disparity in the accuracy-robustness trade-off in speech data and addresses fairness evaluation for rejection-based defenses.
Bridging the Gap: Using Deep Acoustic Representations to Learn Grounded Language from Percepts and Raw Speech
Dec 27, 2021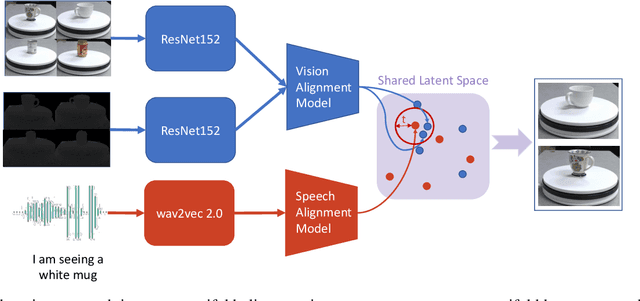
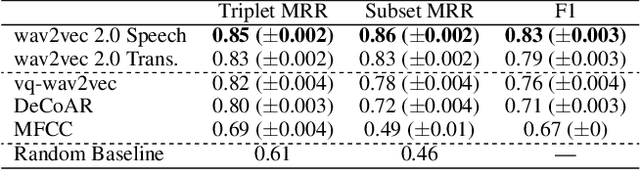
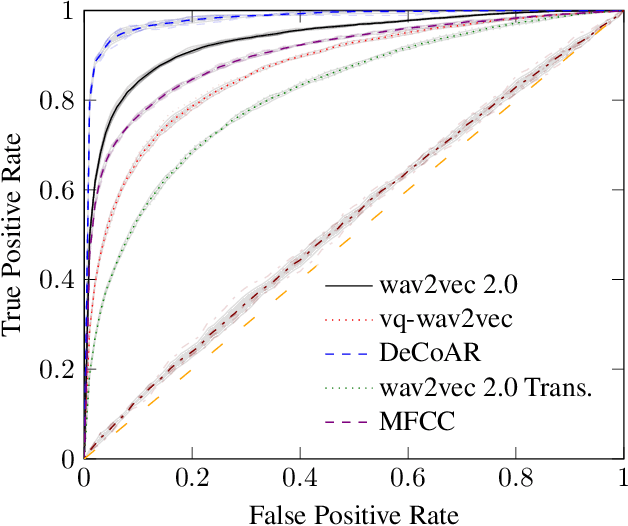
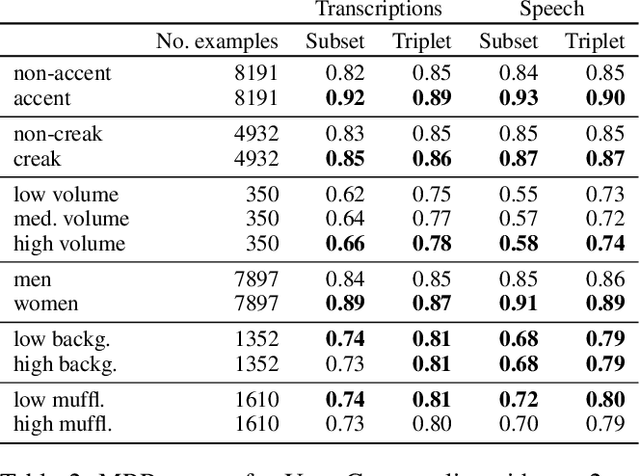
Learning to understand grounded language, which connects natural language to percepts, is a critical research area. Prior work in grounded language acquisition has focused primarily on textual inputs. In this work we demonstrate the feasibility of performing grounded language acquisition on paired visual percepts and raw speech inputs. This will allow interactions in which language about novel tasks and environments is learned from end users, reducing dependence on textual inputs and potentially mitigating the effects of demographic bias found in widely available speech recognition systems. We leverage recent work in self-supervised speech representation models and show that learned representations of speech can make language grounding systems more inclusive towards specific groups while maintaining or even increasing general performance.
Adversarial Transfer Attacks With Unknown Data and Class Overlap
Sep 24, 2021
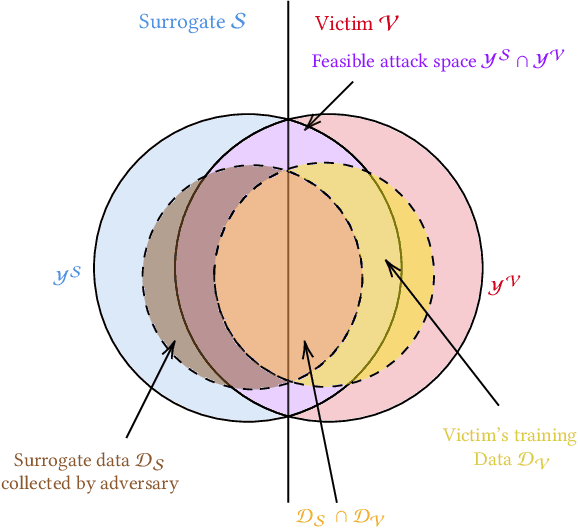
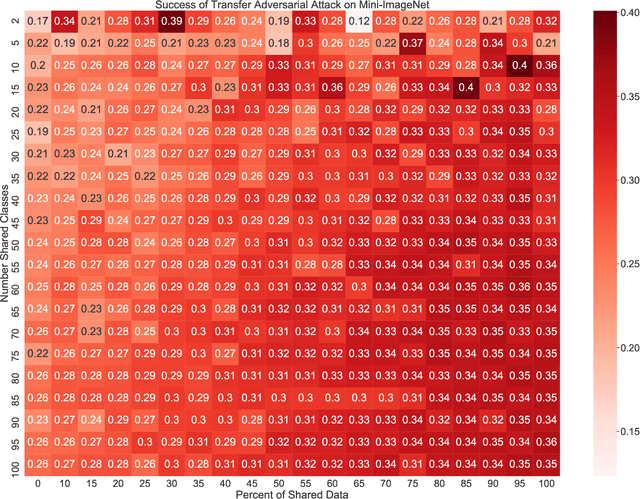
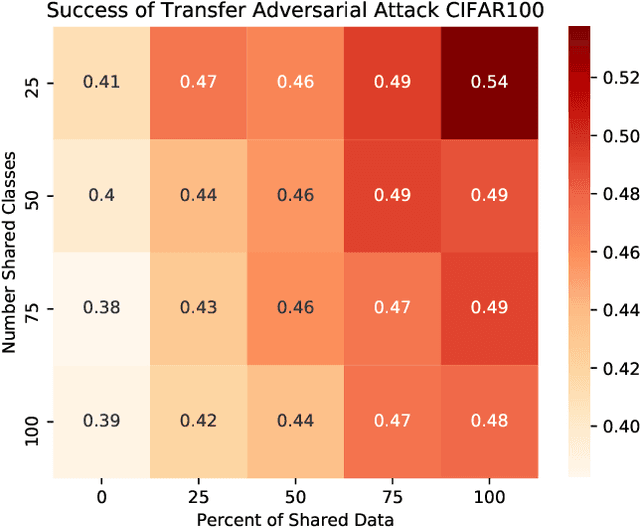
The ability to transfer adversarial attacks from one model (the surrogate) to another model (the victim) has been an issue of concern within the machine learning (ML) community. The ability to successfully evade unseen models represents an uncomfortable level of ease toward implementing attacks. In this work we note that as studied, current transfer attack research has an unrealistic advantage for the attacker: the attacker has the exact same training data as the victim. We present the first study of transferring adversarial attacks focusing on the data available to attacker and victim under imperfect settings without querying the victim, where there is some variable level of overlap in the exact data used or in the classes learned by each model. This threat model is relevant to applications in medicine, malware, and others. Under this new threat model attack success rate is not correlated with data or class overlap in the way one would expect, and varies with dataset. This makes it difficult for attacker and defender to reason about each other and contributes to the broader study of model robustness and security. We remedy this by developing a masked version of Projected Gradient Descent that simulates class disparity, which enables the attacker to reliably estimate a lower-bound on their attack's success.
Neural Variational Learning for Grounded Language Acquisition
Jul 20, 2021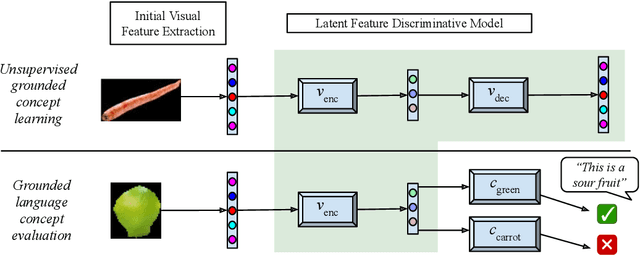

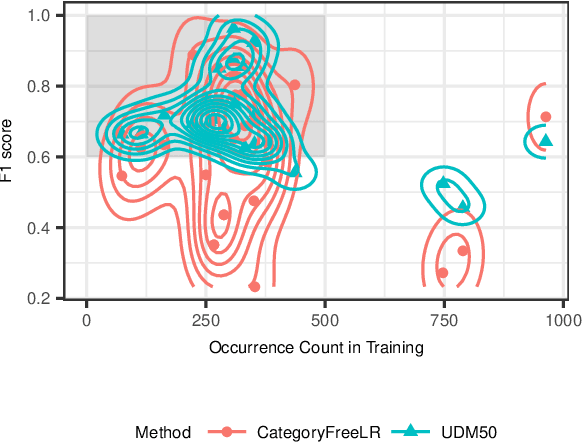
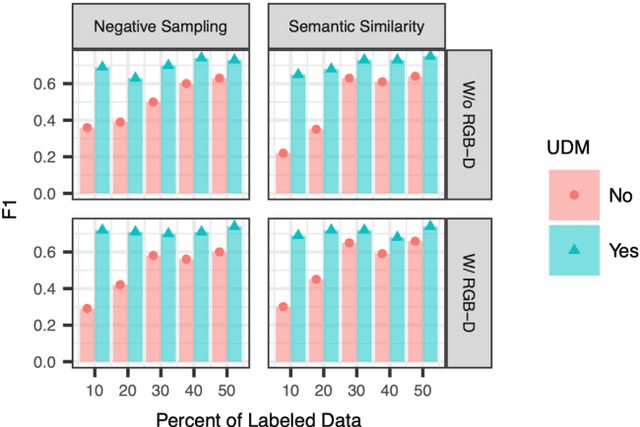
We propose a learning system in which language is grounded in visual percepts without specific pre-defined categories of terms. We present a unified generative method to acquire a shared semantic/visual embedding that enables the learning of language about a wide range of real-world objects. We evaluate the efficacy of this learning by predicting the semantics of objects and comparing the performance with neural and non-neural inputs. We show that this generative approach exhibits promising results in language grounding without pre-specifying visual categories under low resource settings. Our experiments demonstrate that this approach is generalizable to multilingual, highly varied datasets.