 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlaMADRS: Prompting Large Language Models for Interview-Based Depression Assessment
Jan 07, 2025This study introduces LlaMADRS, a novel framework leveraging open-source Large Language Models (LLMs) to automate depression severity assessment using the Montgomery-Asberg Depression Rating Scale (MADRS). We employ a zero-shot prompting strategy with carefully designed cues to guide the model in interpreting and scoring transcribed clinical interviews. Our approach, tested on 236 real-world interviews from the Context-Adaptive Multimodal Informatics (CAMI) dataset, demonstrates strong correlations with clinician assessments. The Qwen 2.5--72b model achieves near-human level agreement across most MADRS items, with Intraclass Correlation Coefficients (ICC) closely approaching those between human raters. We provide a comprehensive analysis of model performance across different MADRS items, highlighting strengths and current limitations. Our findings suggest that LLMs, with appropriate prompting, can serve as efficient tools for mental health assessment, potentially increasing accessibility in resource-limited settings. However, challenges remain, particularly in assessing symptoms that rely on non-verbal cues, underscoring the need for multimodal approaches in future work.
Bridging the Gap: Using Deep Acoustic Representations to Learn Grounded Language from Percepts and Raw Speech
Dec 27, 2021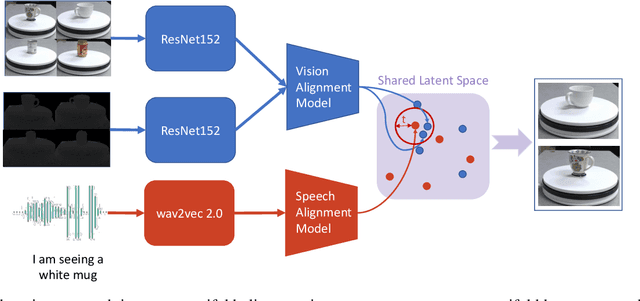
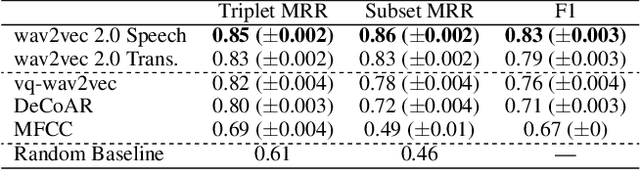
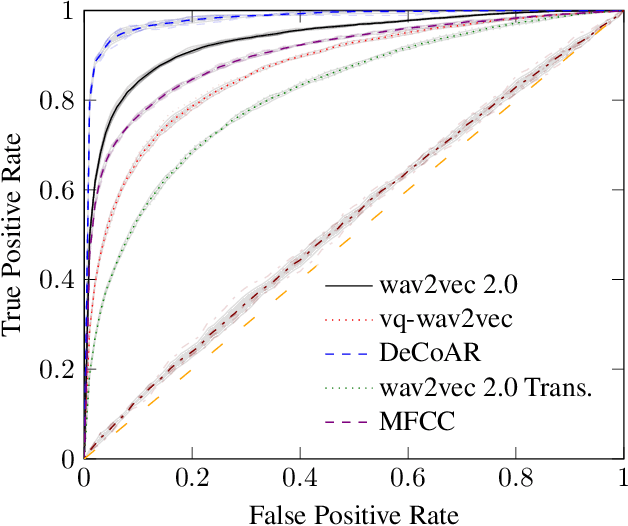
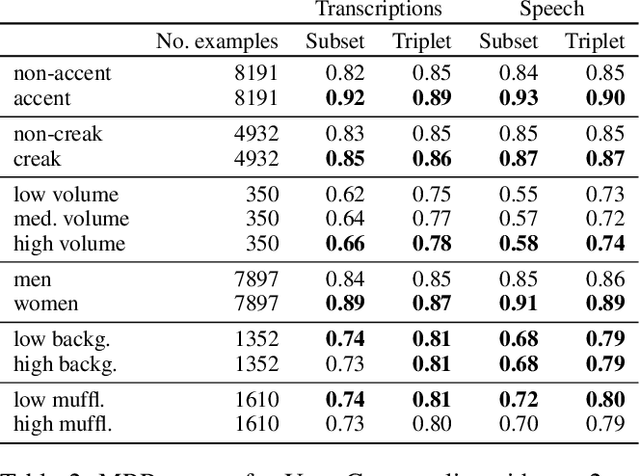
Learning to understand grounded language, which connects natural language to percepts, is a critical research area. Prior work in grounded language acquisition has focused primarily on textual inputs. In this work we demonstrate the feasibility of performing grounded language acquisition on paired visual percepts and raw speech inputs. This will allow interactions in which language about novel tasks and environments is learned from end users, reducing dependence on textual inputs and potentially mitigating the effects of demographic bias found in widely available speech recognition systems. We leverage recent work in self-supervised speech representation models and show that learned representations of speech can make language grounding systems more inclusive towards specific groups while maintaining or even increasing general performance.
Discriminative and Generative Transformer-based Models For Situation Entity Classification
Sep 15, 2021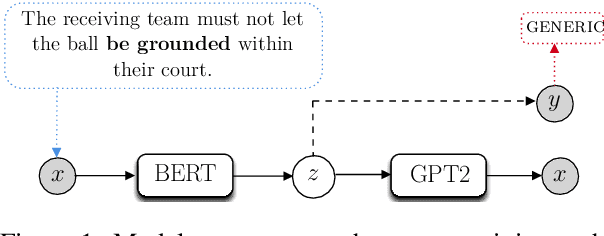
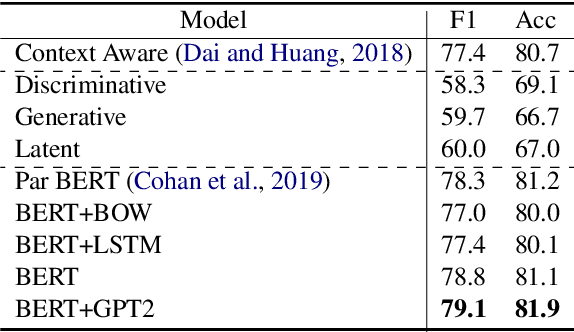
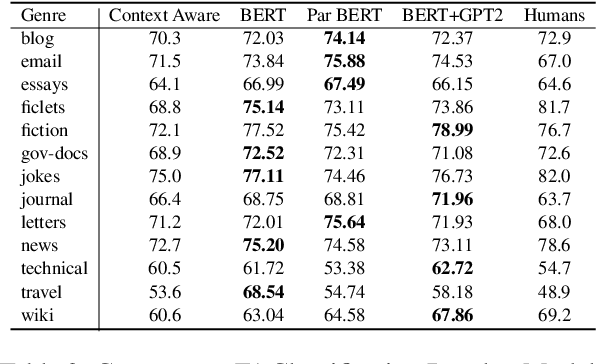
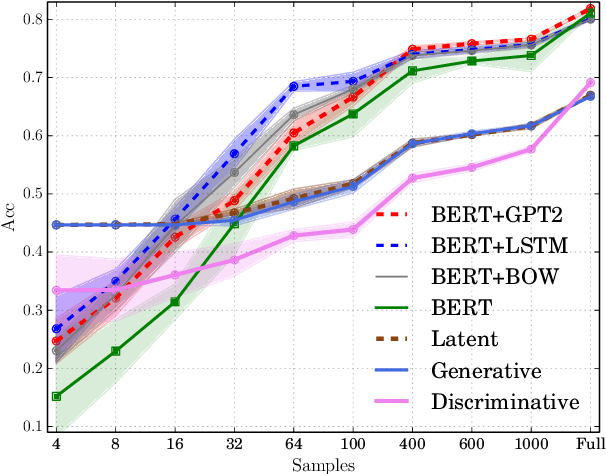
We re-examine the situation entity (SE) classification task with varying amounts of available training data. We exploit a Transformer-based variational autoencoder to encode sentences into a lower dimensional latent space, which is used to generate the text and learn a SE classifier. Test set and cross-genre evaluations show that when training data is plentiful, the proposed model can improve over the previous discriminative state-of-the-art models. Our approach performs disproportionately better with smaller amounts of training data, but when faced with extremely small sets (4 instances per label), generative RNN methods outperform transformers. Our work provides guidance for future efforts on SE and semantic prediction tasks, and low-label training regimes.
Practical Cross-modal Manifold Alignment for Grounded Language
Sep 01, 2020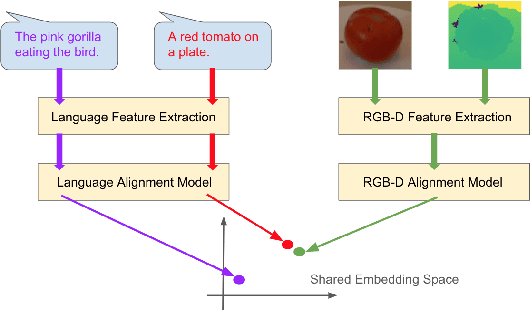
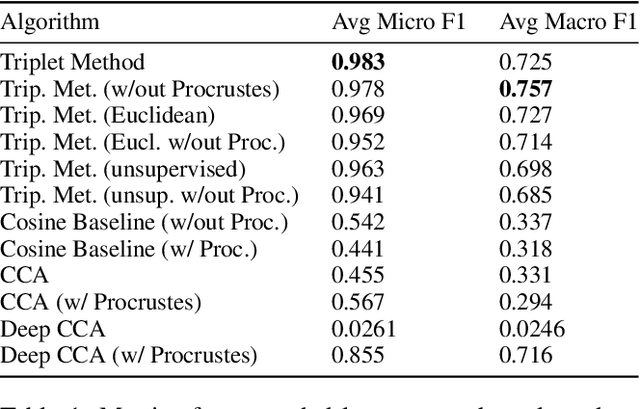

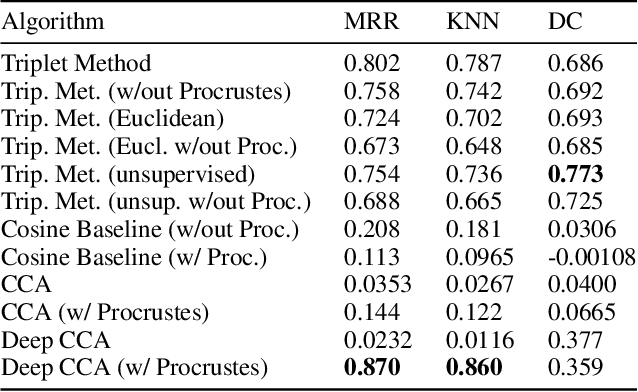
We propose a cross-modality manifold alignment procedure that leverages triplet loss to jointly learn consistent, multi-modal embeddings of language-based concepts of real-world items. Our approach learns these embeddings by sampling triples of anchor, positive, and negative data points from RGB-depth images and their natural language descriptions. We show that our approach can benefit from, but does not require, post-processing steps such as Procrustes analysis, in contrast to some of our baselines which require it for reasonable performance. We demonstrate the effectiveness of our approach on two datasets commonly used to develop robotic-based grounded language learning systems, where our approach outperforms four baselines, including a state-of-the-art approach, across five evaluation metrics.
Presentation and Analysis of a Multimodal Dataset for Grounded LanguageLearning
Jul 31, 2020
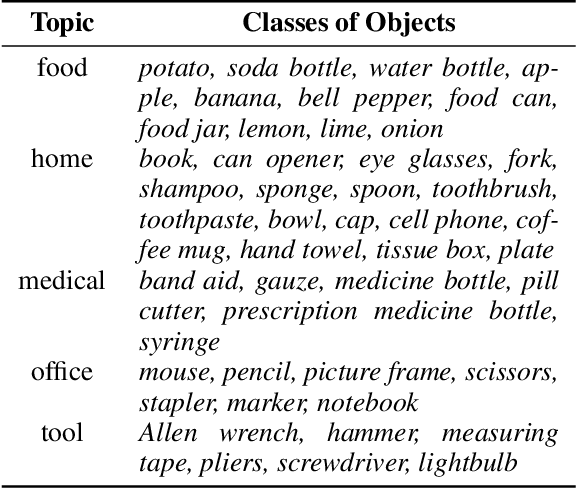


Grounded language acquisition -- learning how language-based interactions refer to the world around them -- is amajor area of research in robotics, NLP, and HCI. In practice the data used for learning consists almost entirely of textual descriptions, which tend to be cleaner, clearer, and more grammatical than actual human interactions. In this work, we present the Grounded Language Dataset (GoLD), a multimodal dataset of common household objects described by people using either spoken or written language. We analyze the differences and present an experiment showing how the different modalities affect language learning from human in-put. This will enable researchers studying the intersection of robotics, NLP, and HCI to better investigate how the multiple modalities of image, text, and speech interact, as well as show differences in the vernacular of these modalities impact results.