 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEVerA: Verified Synthesis of Self-Evolving Agents
Mar 26, 2026Recent advances have shown the effectiveness of self-evolving LLM agents on tasks such as program repair and scientific discovery. In this paradigm, a planner LLM synthesizes an agent program that invokes parametric models, including LLMs, which are then tuned per task to improve performance. However, existing self-evolving agent frameworks provide no formal guarantees of safety or correctness. Because such programs are often executed autonomously on unseen inputs, this lack of guarantees raises reliability and security concerns. We formulate agentic code generation as a constrained learning problem, combining hard formal specifications with soft objectives capturing task utility. We introduce Formally Guarded Generative Models (FGGM), which allow the planner LLM to specify a formal output contract for each generative model call using first-order logic. Each FGGM call wraps the underlying model in a rejection sampler with a verified fallback, ensuring every returned output satisfies the contract for any input and parameter setting. Building on FGGM, we present SEVerA (Self-Evolving Verified Agents), a three-stage framework: Search synthesizes candidate parametric programs containing FGGM calls; Verification proves correctness with respect to hard constraints for all parameter values, reducing the problem to unconstrained learning; and Learning applies scalable gradient-based optimization, including GRPO-style fine-tuning, to improve the soft objective while preserving correctness. We evaluate SEVerA on Dafny program verification, symbolic math synthesis, and policy-compliant agentic tool use ($τ^2$-bench). Across tasks, SEVerA achieves zero constraint violations while improving performance over unconstrained and SOTA baselines, showing that formal behavioral constraints not only guarantee correctness but also steer synthesis toward higher-quality agents.
Compression Aware Certified Training
Jun 13, 2025



Deep neural networks deployed in safety-critical, resource-constrained environments must balance efficiency and robustness. Existing methods treat compression and certified robustness as separate goals, compromising either efficiency or safety. We propose CACTUS (Compression Aware Certified Training Using network Sets), a general framework for unifying these objectives during training. CACTUS models maintain high certified accuracy even when compressed. We apply CACTUS for both pruning and quantization and show that it effectively trains models which can be efficiently compressed while maintaining high accuracy and certifiable robustness. CACTUS achieves state-of-the-art accuracy and certified performance for both pruning and quantization on a variety of datasets and input specifications.
Misaligning Reasoning with Answers -- A Framework for Assessing LLM CoT Robustness
May 23, 2025



LLMs' decision-making process is opaque, prompting the need for explanation techniques like Chain-of-Thought. To investigate the relationship between answer and reasoning, we design a novel evaluation framework, MATCHA. In domains like education and healthcare, reasoning is key for model trustworthiness. MATCHA reveals that LLMs under input perturbations can give inconsistent or nonsensical reasoning. Additionally, we use LLM judges to assess reasoning robustness across models. Our results show that LLMs exhibit greater vulnerability to input perturbations for multi-step and commonsense tasks than compared to logical tasks. Also, we show non-trivial transfer rates of our successful examples to black-box models. Our evaluation framework helps to better understand LLM reasoning mechanisms and guides future models toward more robust and reasoning-driven architectures, enforcing answer-reasoning consistency.
Support is All You Need for Certified VAE Training
Apr 16, 2025Variational Autoencoders (VAEs) have become increasingly popular and deployed in safety-critical applications. In such applications, we want to give certified probabilistic guarantees on performance under adversarial attacks. We propose a novel method, CIVET, for certified training of VAEs. CIVET depends on the key insight that we can bound worst-case VAE error by bounding the error on carefully chosen support sets at the latent layer. We show this point mathematically and present a novel training algorithm utilizing this insight. We show in an extensive evaluation across different datasets (in both the wireless and vision application areas), architectures, and perturbation magnitudes that our method outperforms SOTA methods achieving good standard performance with strong robustness guarantees.
Cross-Input Certified Training for Universal Perturbations
May 15, 2024Existing work in trustworthy machine learning primarily focuses on single-input adversarial perturbations. In many real-world attack scenarios, input-agnostic adversarial attacks, e.g. universal adversarial perturbations (UAPs), are much more feasible. Current certified training methods train models robust to single-input perturbations but achieve suboptimal clean and UAP accuracy, thereby limiting their applicability in practical applications. We propose a novel method, CITRUS, for certified training of networks robust against UAP attackers. We show in an extensive evaluation across different datasets, architectures, and perturbation magnitudes that our method outperforms traditional certified training methods on standard accuracy (up to 10.3\%) and achieves SOTA performance on the more practical certified UAP accuracy metric.
Bypassing the Safety Training of Open-Source LLMs with Priming Attacks
Dec 19, 2023



With the recent surge in popularity of LLMs has come an ever-increasing need for LLM safety training. In this paper, we show that SOTA open-source LLMs are vulnerable to simple, optimization-free attacks we refer to as $\textit{priming attacks}$, which are easy to execute and effectively bypass alignment from safety training. Our proposed attack improves the Attack Success Rate on Harmful Behaviors, as measured by Llama Guard, by up to $3.3\times$ compared to baselines. Source code and data are available at https://github.com/uiuc-focal-lab/llm-priming-attacks .
Robust Universal Adversarial Perturbations
Jun 22, 2022

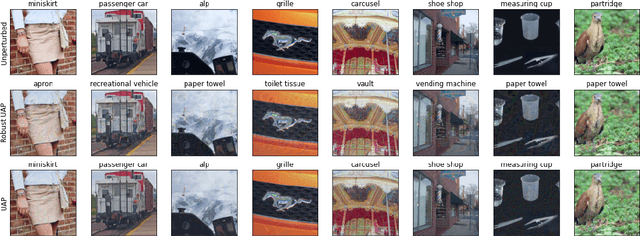
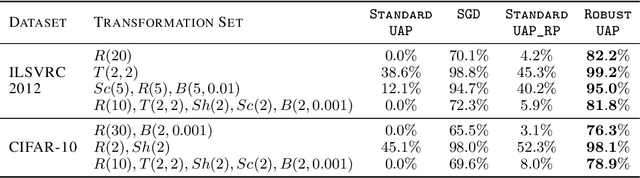
Universal Adversarial Perturbations (UAPs) are imperceptible, image-agnostic vectors that cause deep neural networks (DNNs) to misclassify inputs from a data distribution with high probability. Existing methods do not create UAPs robust to transformations, thereby limiting their applicability as a real-world attacks. In this work, we introduce a new concept and formulation of robust universal adversarial perturbations. Based on our formulation, we build a novel, iterative algorithm that leverages probabilistic robustness bounds for generating UAPs robust against transformations generated by composing arbitrary sub-differentiable transformation functions. We perform an extensive evaluation on the popular CIFAR-10 and ILSVRC 2012 datasets measuring robustness under human-interpretable semantic transformations, such as rotation, contrast changes, etc, that are common in the real-world. Our results show that our generated UAPs are significantly more robust than those from baselines.
A novel sentence embedding based topic detection method for micro-blog
Jun 10, 2020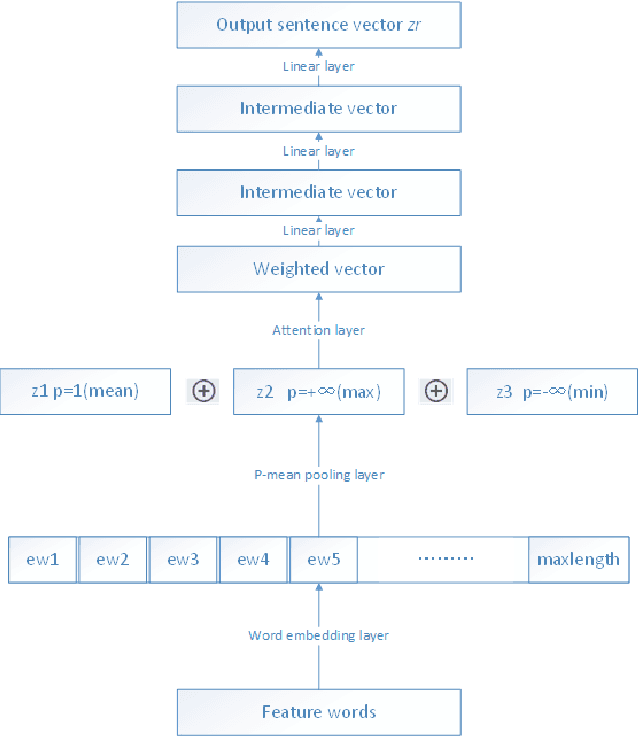
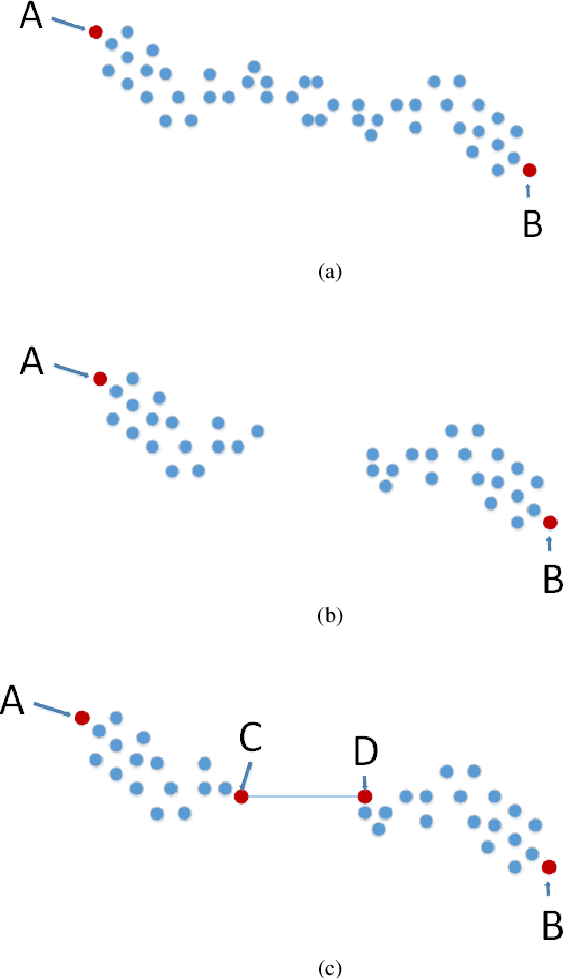
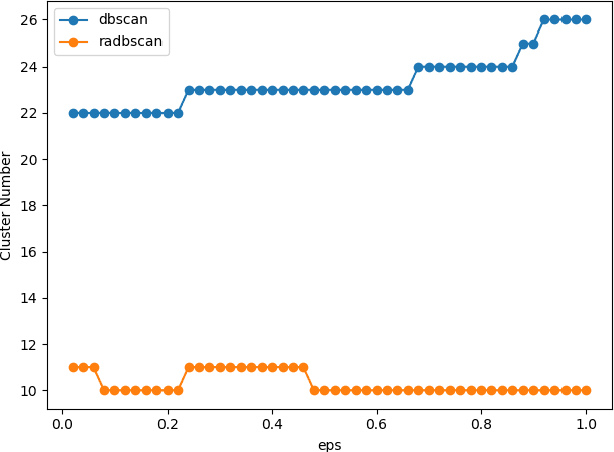
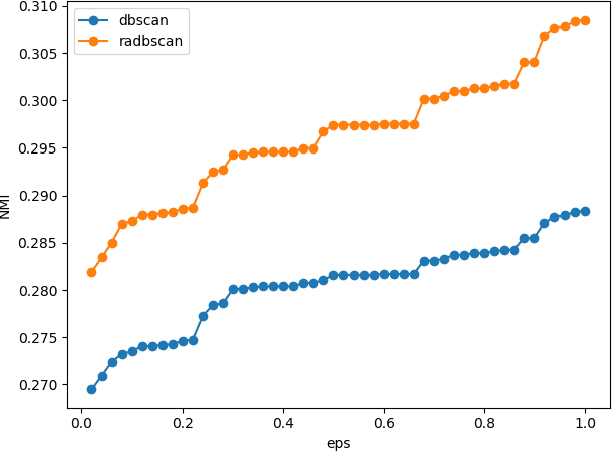
Topic detection is a challenging task, especially without knowing the exact number of topics. In this paper, we present a novel approach based on neural network to detect topics in the micro-blogging dataset. We use an unsupervised neural sentence embedding model to map the blogs to an embedding space. Our model is a weighted power mean word embedding model, and the weights are calculated by attention mechanism. Experimental result shows our embedding method performs better than baselines in sentence clustering. In addition, we propose an improved clustering algorithm referred as relationship-aware DBSCAN (RADBSCAN). It can discover topics from a micro-blogging dataset, and the topic number depends on dataset character itself. Moreover, in order to solve the problem of parameters sensitive, we take blog forwarding relationship as a bridge of two independent clusters. Finally, we validate our approach on a dataset from sina micro-blog. The result shows that we can detect all the topics successfully and extract keywords in each topic.