 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Region-Based Active Learning
Feb 18, 2020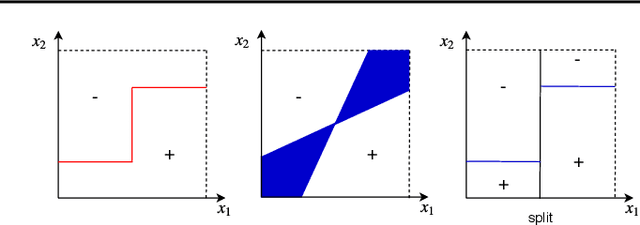
We present a new active learning algorithm that adaptively partitions the input space into a finite number of regions, and subsequently seeks a distinct predictor for each region, both phases actively requesting labels. We prove theoretical guarantees for both the generalization error and the label complexity of our algorithm, and analyze the number of regions defined by the algorithm under some mild assumptions. We also report the results of an extensive suite of experiments on several real-world datasets demonstrating substantial empirical benefits over existing single-region and non-adaptive region-based active learning baselines.
Flattening a Hierarchical Clustering through Active Learning
Jun 22, 2019
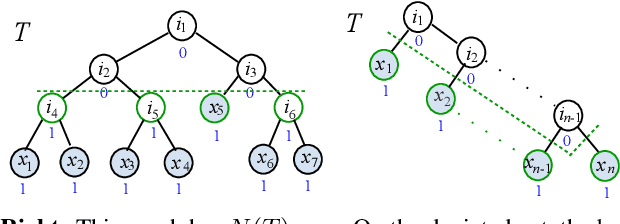
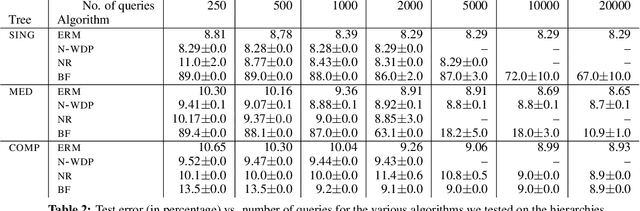
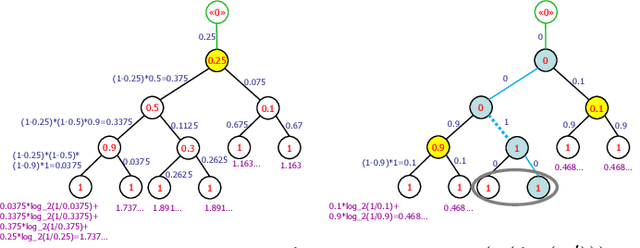
We investigate active learning by pairwise similarity over the leaves of trees originating from hierarchical clustering procedures. In the realizable setting, we provide a full characterization of the number of queries needed to achieve perfect reconstruction of the tree cut. In the non-realizable setting, we rely on known important-sampling procedures to obtain regret and query complexity bounds. Our algorithms come with theoretical guarantees on the statistical error and, more importantly, lend themselves to linear-time implementations in the relevant parameters of the problem. We discuss such implementations, prove running time guarantees for them, and present preliminary experiments on real-world datasets showing the compelling practical performance of our algorithms as compared to both passive learning and simple active learning baselines.
Online Reciprocal Recommendation with Theoretical Performance Guarantees
Jun 04, 2018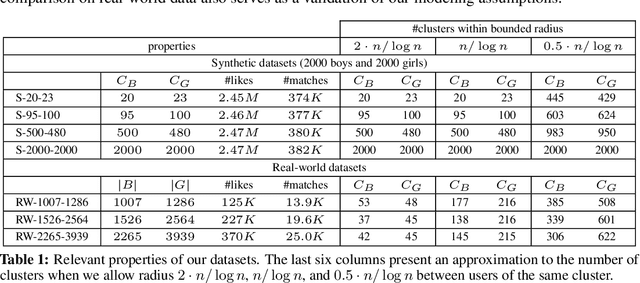
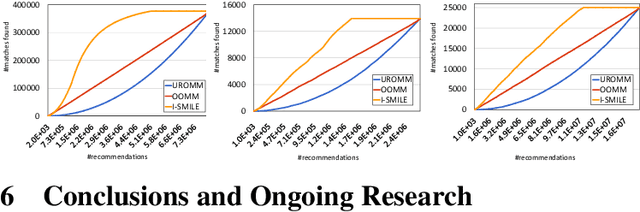
A reciprocal recommendation problem is one where the goal of learning is not just to predict a user's preference towards a passive item (e.g., a book), but to recommend the targeted user on one side another user from the other side such that a mutual interest between the two exists. The problem thus is sharply different from the more traditional items-to-users recommendation, since a good match requires meeting the preferences of both users. We initiate a rigorous theoretical investigation of the reciprocal recommendation task in a specific framework of sequential learning. We point out general limitations, formulate reasonable assumptions enabling effective learning and, under these assumptions, we design and analyze a computationally efficient algorithm that uncovers mutual likes at a pace comparable to those achieved by a clearvoyant algorithm knowing all user preferences in advance. Finally, we validate our algorithm against synthetic and real-world datasets, showing improved empirical performance over simple baselines.
Online Learning with Abstention
Feb 27, 2018



We present an extensive study of the key problem of online learning where algorithms are allowed to abstain from making predictions. In the adversarial setting, we show how existing online algorithms and guarantees can be adapted to this problem. In the stochastic setting, we first point out a bias problem that limits the straightforward extension of algorithms such as UCB-N to time-varying feedback graphs, as needed in this context. Next, we give a new algorithm, UCB-GT, that exploits historical data and is adapted to time-varying feedback graphs. We show that this algorithm benefits from more favorable regret guarantees than a possible, but limited, extension of UCB-N. We further report the results of a series of experiments demonstrating that UCB-GT largely outperforms that extension of UCB-N, as well as more standard baselines.
Boltzmann Exploration Done Right
Nov 07, 2017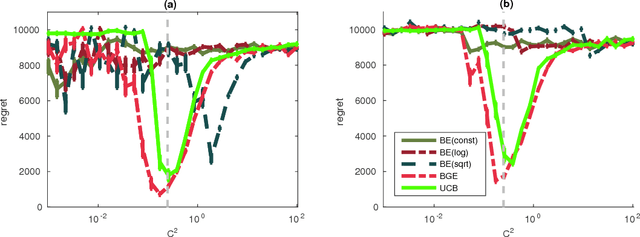
Boltzmann exploration is a classic strategy for sequential decision-making under uncertainty, and is one of the most standard tools in Reinforcement Learning (RL). Despite its widespread use, there is virtually no theoretical understanding about the limitations or the actual benefits of this exploration scheme. Does it drive exploration in a meaningful way? Is it prone to misidentifying the optimal actions or spending too much time exploring the suboptimal ones? What is the right tuning for the learning rate? In this paper, we address several of these questions in the classic setup of stochastic multi-armed bandits. One of our main results is showing that the Boltzmann exploration strategy with any monotone learning-rate sequence will induce suboptimal behavior. As a remedy, we offer a simple non-monotone schedule that guarantees near-optimal performance, albeit only when given prior access to key problem parameters that are typically not available in practical situations (like the time horizon $T$ and the suboptimality gap $\Delta$). More importantly, we propose a novel variant that uses different learning rates for different arms, and achieves a distribution-dependent regret bound of order $\frac{K\log^2 T}{\Delta}$ and a distribution-independent bound of order $\sqrt{KT}\log K$ without requiring such prior knowledge. To demonstrate the flexibility of our technique, we also propose a variant that guarantees the same performance bounds even if the rewards are heavy-tailed.
Algorithmic Chaining and the Role of Partial Feedback in Online Nonparametric Learning
Jun 30, 2017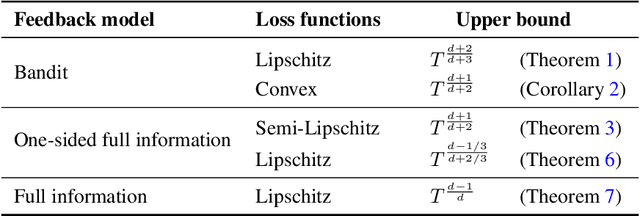
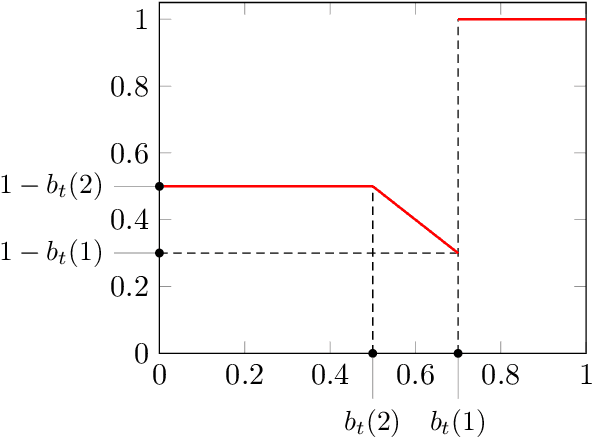
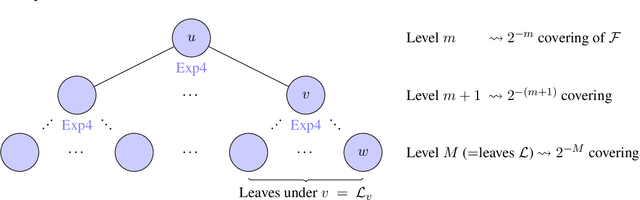
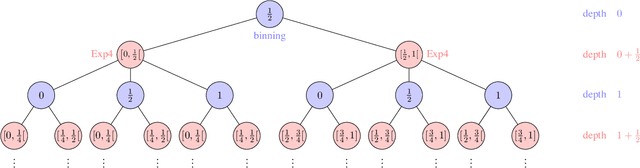
We investigate contextual online learning with nonparametric (Lipschitz) comparison classes under different assumptions on losses and feedback information. For full information feedback and Lipschitz losses, we design the first explicit algorithm achieving the minimax regret rate (up to log factors). In a partial feedback model motivated by second-price auctions, we obtain algorithms for Lipschitz and semi-Lipschitz losses with regret bounds improving on the known bounds for standard bandit feedback. Our analysis combines novel results for contextual second-price auctions with a novel algorithmic approach based on chaining. When the context space is Euclidean, our chaining approach is efficient and delivers an even better regret bound.
On Pairwise Clustering with Side Information
Jun 19, 2017
Pairwise clustering, in general, partitions a set of items via a known similarity function. In our treatment, clustering is modeled as a transductive prediction problem. Thus rather than beginning with a known similarity function, the function instead is hidden and the learner only receives a random sample consisting of a subset of the pairwise similarities. An additional set of pairwise side-information may be given to the learner, which then determines the inductive bias of our algorithms. We measure performance not based on the recovery of the hidden similarity function, but instead on how well we classify each item. We give tight bounds on the number of misclassifications. We provide two algorithms. The first algorithm SACA is a simple agglomerative clustering algorithm which runs in near linear time, and which serves as a baseline for our analyses. Whereas the second algorithm, RGCA, enables the incorporation of side-information which may lead to improved bounds at the cost of a longer running time.
On the Troll-Trust Model for Edge Sign Prediction in Social Networks
Feb 28, 2017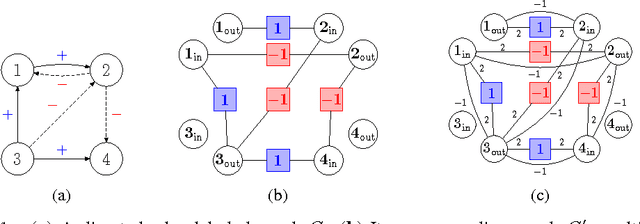
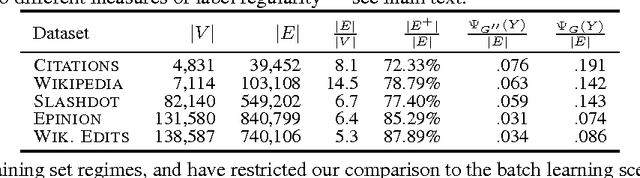
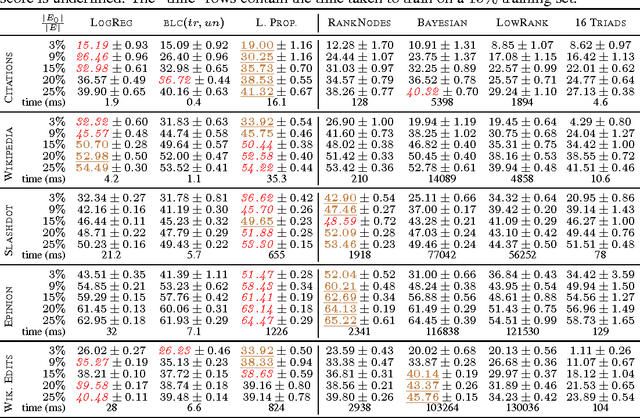
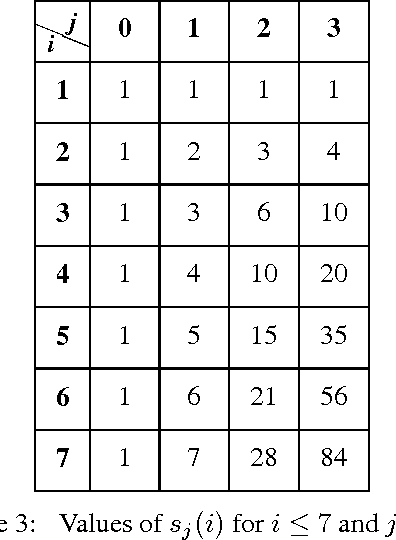
In the problem of edge sign prediction, we are given a directed graph (representing a social network), and our task is to predict the binary labels of the edges (i.e., the positive or negative nature of the social relationships). Many successful heuristics for this problem are based on the troll-trust features, estimating at each node the fraction of outgoing and incoming positive/negative edges. We show that these heuristics can be understood, and rigorously analyzed, as approximators to the Bayes optimal classifier for a simple probabilistic model of the edge labels. We then show that the maximum likelihood estimator for this model approximately corresponds to the predictions of a Label Propagation algorithm run on a transformed version of the original social graph. Extensive experiments on a number of real-world datasets show that this algorithm is competitive against state-of-the-art classifiers in terms of both accuracy and scalability. Finally, we show that troll-trust features can also be used to derive online learning algorithms which have theoretical guarantees even when edges are adversarially labeled.
On Context-Dependent Clustering of Bandits
Feb 27, 2017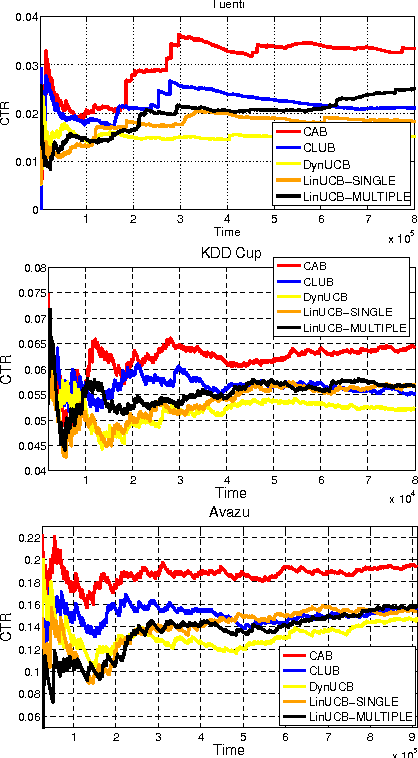
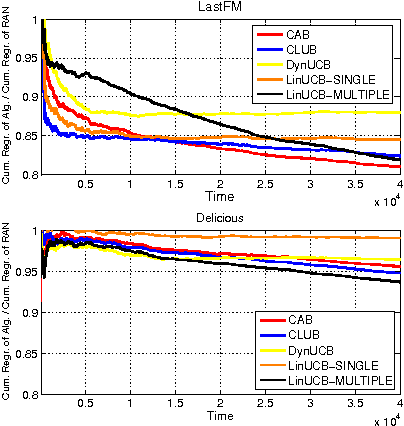
We investigate a novel cluster-of-bandit algorithm CAB for collaborative recommendation tasks that implements the underlying feedback sharing mechanism by estimating the neighborhood of users in a context-dependent manner. CAB makes sharp departures from the state of the art by incorporating collaborative effects into inference as well as learning processes in a manner that seamlessly interleaving explore-exploit tradeoffs and collaborative steps. We prove regret bounds under various assumptions on the data, which exhibit a crisp dependence on the expected number of clusters over the users, a natural measure of the statistical difficulty of the learning task. Experiments on production and real-world datasets show that CAB offers significantly increased prediction performance against a representative pool of state-of-the-art methods.
Delay and Cooperation in Nonstochastic Bandits
Jun 01, 2016


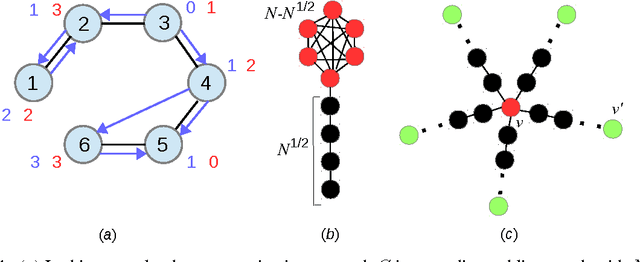
We study networks of communicating learning agents that cooperate to solve a common nonstochastic bandit problem. Agents use an underlying communication network to get messages about actions selected by other agents, and drop messages that took more than $d$ hops to arrive, where $d$ is a delay parameter. We introduce \textsc{Exp3-Coop}, a cooperative version of the {\sc Exp3} algorithm and prove that with $K$ actions and $N$ agents the average per-agent regret after $T$ rounds is at most of order $\sqrt{\bigl(d+1 + \tfrac{K}{N}\alpha_{\le d}\bigr)(T\ln K)}$, where $\alpha_{\le d}$ is the independence number of the $d$-th power of the connected communication graph $G$. We then show that for any connected graph, for $d=\sqrt{K}$ the regret bound is $K^{1/4}\sqrt{T}$, strictly better than the minimax regret $\sqrt{KT}$ for noncooperating agents. More informed choices of $d$ lead to bounds which are arbitrarily close to the full information minimax regret $\sqrt{T\ln K}$ when $G$ is dense. When $G$ has sparse components, we show that a variant of \textsc{Exp3-Coop}, allowing agents to choose their parameters according to their centrality in $G$, strictly improves the regret. Finally, as a by-product of our analysis, we provide the first characterization of the minimax regret for bandit learning with delay.