 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInhibitory normalization of error signals improves learning in neural circuits
Mar 18, 2026Normalization is a critical operation in neural circuits. In the brain, there is evidence that normalization is implemented via inhibitory interneurons and allows neural populations to adjust to changes in the distribution of their inputs. In artificial neural networks (ANNs), normalization is used to improve learning in tasks that involve complex input distributions. However, it is unclear whether inhibition-mediated normalization in biological neural circuits also improves learning. Here, we explore this possibility using ANNs with separate excitatory and inhibitory populations trained on an image recognition task with variable luminosity. We find that inhibition-mediated normalization does not improve learning if normalization is applied only during inference. However, when this normalization is extended to include back-propagated errors, performance improves significantly. These results suggest that if inhibition-mediated normalization improves learning in the brain, it additionally requires the normalization of learning signals.
AUTOKD: Automatic Knowledge Distillation Into A Student Architecture Family
Nov 05, 2021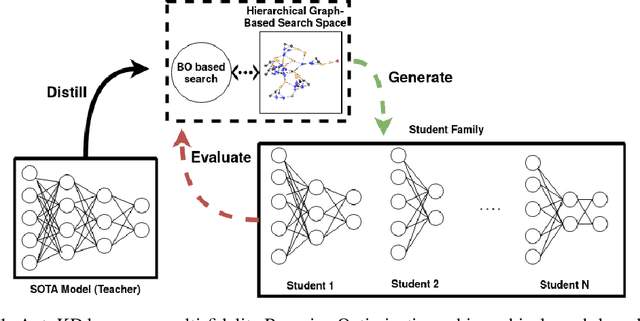
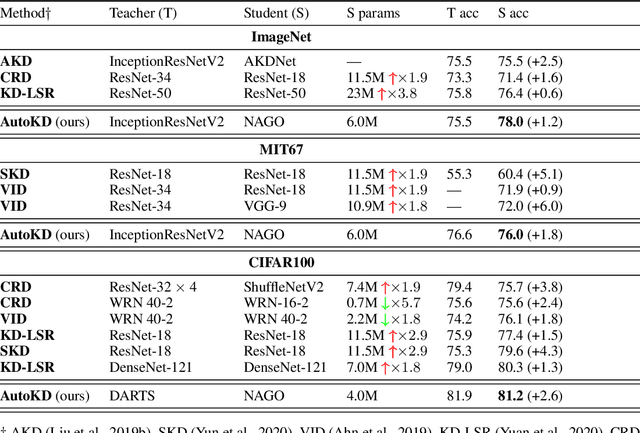
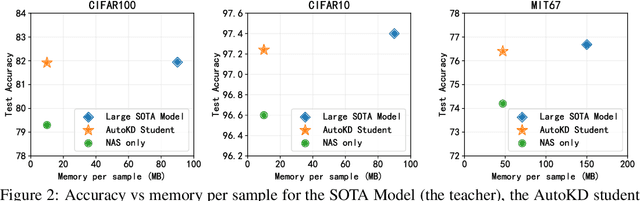
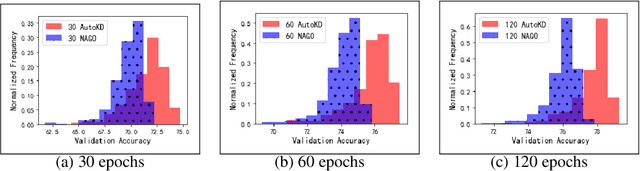
State-of-the-art results in deep learning have been improving steadily, in good part due to the use of larger models. However, widespread use is constrained by device hardware limitations, resulting in a substantial performance gap between state-of-the-art models and those that can be effectively deployed on small devices. While Knowledge Distillation (KD) theoretically enables small student models to emulate larger teacher models, in practice selecting a good student architecture requires considerable human expertise. Neural Architecture Search (NAS) appears as a natural solution to this problem but most approaches can be inefficient, as most of the computation is spent comparing architectures sampled from the same distribution, with negligible differences in performance. In this paper, we propose to instead search for a family of student architectures sharing the property of being good at learning from a given teacher. Our approach AutoKD, powered by Bayesian Optimization, explores a flexible graph-based search space, enabling us to automatically learn the optimal student architecture distribution and KD parameters, while being 20x more sample efficient compared to existing state-of-the-art. We evaluate our method on 3 datasets; on large images specifically, we reach the teacher performance while using 3x less memory and 10x less parameters. Finally, while AutoKD uses the traditional KD loss, it outperforms more advanced KD variants using hand-designed students.
CCN GAC Workshop: Issues with learning in biological recurrent neural networks
May 12, 2021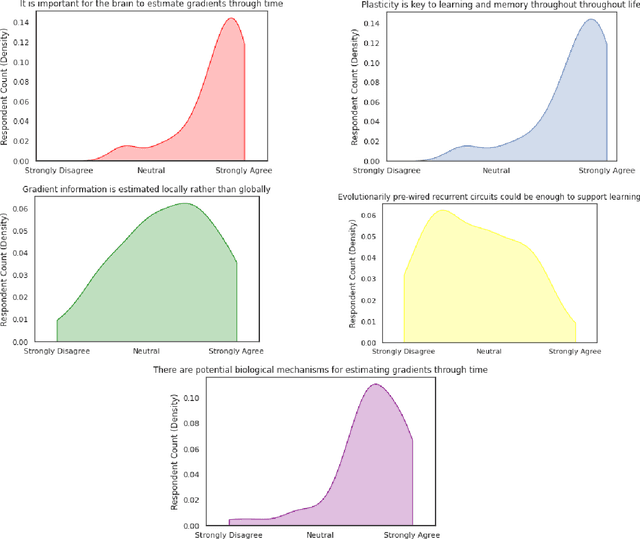
This perspective piece came about through the Generative Adversarial Collaboration (GAC) series of workshops organized by the Computational Cognitive Neuroscience (CCN) conference in 2020. We brought together a number of experts from the field of theoretical neuroscience to debate emerging issues in our understanding of how learning is implemented in biological recurrent neural networks. Here, we will give a brief review of the common assumptions about biological learning and the corresponding findings from experimental neuroscience and contrast them with the efficiency of gradient-based learning in recurrent neural networks commonly used in artificial intelligence. We will then outline the key issues discussed in the workshop: synaptic plasticity, neural circuits, theory-experiment divide, and objective functions. Finally, we conclude with recommendations for both theoretical and experimental neuroscientists when designing new studies that could help to bring clarity to these issues.