 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Label-Free High-Precision Residual Moveout Picking Method for Travel Time Tomography based on Deep Learning
Mar 08, 2025Residual moveout (RMO) provides critical information for travel time tomography. The current industry-standard method for fitting RMO involves scanning high-order polynomial equations. However, this analytical approach does not accurately capture local saltation, leading to low iteration efficiency in tomographic inversion. Supervised learning-based image segmentation methods for picking can effectively capture local variations; however, they encounter challenges such as a scarcity of reliable training samples and the high complexity of post-processing. To address these issues, this study proposes a deep learning-based cascade picking method. It distinguishes accurate and robust RMOs using a segmentation network and a post-processing technique based on trend regression. Additionally, a data synthesis method is introduced, enabling the segmentation network to be trained on synthetic datasets for effective picking in field data. Furthermore, a set of metrics is proposed to quantify the quality of automatically picked RMOs. Experimental results based on both model and real data demonstrate that, compared to semblance-based methods, our approach achieves greater picking density and accuracy.
Deep Unfolding Multi-modal Image Fusion Network via Attribution Analysis
Feb 03, 2025



Multi-modal image fusion synthesizes information from multiple sources into a single image, facilitating downstream tasks such as semantic segmentation. Current approaches primarily focus on acquiring informative fusion images at the visual display stratum through intricate mappings. Although some approaches attempt to jointly optimize image fusion and downstream tasks, these efforts often lack direct guidance or interaction, serving only to assist with a predefined fusion loss. To address this, we propose an ``Unfolding Attribution Analysis Fusion network'' (UAAFusion), using attribution analysis to tailor fused images more effectively for semantic segmentation, enhancing the interaction between the fusion and segmentation. Specifically, we utilize attribution analysis techniques to explore the contributions of semantic regions in the source images to task discrimination. At the same time, our fusion algorithm incorporates more beneficial features from the source images, thereby allowing the segmentation to guide the fusion process. Our method constructs a model-driven unfolding network that uses optimization objectives derived from attribution analysis, with an attribution fusion loss calculated from the current state of the segmentation network. We also develop a new pathway function for attribution analysis, specifically tailored to the fusion tasks in our unfolding network. An attribution attention mechanism is integrated at each network stage, allowing the fusion network to prioritize areas and pixels crucial for high-level recognition tasks. Additionally, to mitigate the information loss in traditional unfolding networks, a memory augmentation module is incorporated into our network to improve the information flow across various network layers. Extensive experiments demonstrate our method's superiority in image fusion and applicability to semantic segmentation.
Simultaneous Automatic Picking and Manual Picking Refinement for First-Break
Feb 03, 2025



First-break picking is a pivotal procedure in processing microseismic data for geophysics and resource exploration. Recent advancements in deep learning have catalyzed the evolution of automated methods for identifying first-break. Nevertheless, the complexity of seismic data acquisition and the requirement for detailed, expert-driven labeling often result in outliers and potential mislabeling within manually labeled datasets. These issues can negatively affect the training of neural networks, necessitating algorithms that handle outliers or mislabeled data effectively. We introduce the Simultaneous Picking and Refinement (SPR) algorithm, designed to handle datasets plagued by outlier samples or even noisy labels. Unlike conventional approaches that regard manual picks as ground truth, our method treats the true first-break as a latent variable within a probabilistic model that includes a first-break labeling prior. SPR aims to uncover this variable, enabling dynamic adjustments and improved accuracy across the dataset. This strategy mitigates the impact of outliers or inaccuracies in manual labels. Intra-site picking experiments and cross-site generalization experiments on publicly available data confirm our method's performance in identifying first-break and its generalization across different sites. Additionally, our investigations into noisy signals and labels underscore SPR's resilience to both types of noise and its capability to refine misaligned manual annotations. Moreover, the flexibility of SPR, not being limited to any single network architecture, enhances its adaptability across various deep learning-based picking methods. Focusing on learning from data that may contain outliers or partial inaccuracies, SPR provides a robust solution to some of the principal obstacles in automatic first-break picking.
Training-Free Robust Interactive Video Object Segmentation
Jun 08, 2024



Interactive video object segmentation is a crucial video task, having various applications from video editing to data annotating. However, current approaches struggle to accurately segment objects across diverse domains. Recently, Segment Anything Model (SAM) introduces interactive visual prompts and demonstrates impressive performance across different domains. In this paper, we propose a training-free prompt tracking framework for interactive video object segmentation (I-PT), leveraging the powerful generalization of SAM. Although point tracking efficiently captures the pixel-wise information of objects in a video, points tend to be unstable when tracked over a long period, resulting in incorrect segmentation. Towards fast and robust interaction, we jointly adopt sparse points and boxes tracking, filtering out unstable points and capturing object-wise information. To better integrate reference information from multiple interactions, we introduce a cross-round space-time module (CRSTM), which adaptively aggregates mask features from previous rounds and frames, enhancing the segmentation stability. Our framework has demonstrated robust zero-shot video segmentation results on popular VOS datasets with interaction types, including DAVIS 2017, YouTube-VOS 2018, and MOSE 2023, maintaining a good tradeoff between performance and interaction time.
DSU-Net: Dynamic Snake U-Net for 2-D Seismic First Break Picking
May 27, 2024In seismic exploration, identifying the first break (FB) is a critical component in establishing subsurface velocity models. Various automatic picking techniques based on deep neural networks have been developed to expedite this procedure. The most popular class is using semantic segmentation networks to pick on a shot gather called 2-dimensional (2-D) picking. Generally, 2-D segmentation-based picking methods input an image of a shot gather, and output a binary segmentation map, in which the maximum of each column is the location of FB. However, current designed segmentation networks is difficult to ensure the horizontal continuity of the segmentation. Additionally, FB jumps also exist in some areas, and it is not easy for current networks to detect such jumps. Therefore, it is important to pick as much as possible and ensure horizontal continuity. To alleviate this problem, we propose a novel semantic segmentation network for the 2-D seismic FB picking task, where we introduce the dynamic snake convolution into U-Net and call the new segmentation network dynamic-snake U-Net (DSU-Net). Specifically, we develop original dynamic-snake convolution (DSConv) in CV and propose a novel DSConv module, which can extract the horizontal continuous feature in the shallow feature of the shot gather. Many experiments have shown that DSU-Net demonstrates higher accuracy and robustness than the other 2-D segmentation-based models, achieving state-of-the-art (SOTA) performance in 2-D seismic field surveys. Particularly, it can effectively detect FB jumps and better ensure the horizontal continuity of FB. In addition, the ablation experiment and the anti-noise experiment, respectively, verify the optimal structure of the DSConv module and the robustness of the picking.
Seismic First Break Picking in a Higher Dimension Using Deep Graph Learning
Apr 12, 2024


Contemporary automatic first break (FB) picking methods typically analyze 1D signals, 2D source gathers, or 3D source-receiver gathers. Utilizing higher-dimensional data, such as 2D or 3D, incorporates global features, improving the stability of local picking. Despite the benefits, high-dimensional data requires structured input and increases computational demands. Addressing this, we propose a novel approach using deep graph learning called DGL-FB, constructing a large graph to efficiently extract information. In this graph, each seismic trace is represented as a node, connected by edges that reflect similarities. To manage the size of the graph, we develop a subgraph sampling technique to streamline model training and inference. Our proposed framework, DGL-FB, leverages deep graph learning for FB picking. It encodes subgraphs into global features using a deep graph encoder. Subsequently, the encoded global features are combined with local node signals and fed into a ResUNet-based 1D segmentation network for FB detection. Field survey evaluations of DGL-FB show superior accuracy and stability compared to a 2D U-Net-based benchmark method.
Robust Few-Shot Named Entity Recognition with Boundary Discrimination and Correlation Purification
Dec 13, 2023



Few-shot named entity recognition (NER) aims to recognize novel named entities in low-resource domains utilizing existing knowledge. However, the present few-shot NER models assume that the labeled data are all clean without noise or outliers, and there are few works focusing on the robustness of the cross-domain transfer learning ability to textual adversarial attacks in Few-shot NER. In this work, we comprehensively explore and assess the robustness of few-shot NER models under textual adversarial attack scenario, and found the vulnerability of existing few-shot NER models. Furthermore, we propose a robust two-stage few-shot NER method with Boundary Discrimination and Correlation Purification (BDCP). Specifically, in the span detection stage, the entity boundary discriminative module is introduced to provide a highly distinguishing boundary representation space to detect entity spans. In the entity typing stage, the correlations between entities and contexts are purified by minimizing the interference information and facilitating correlation generalization to alleviate the perturbations caused by textual adversarial attacks. In addition, we construct adversarial examples for few-shot NER based on public datasets Few-NERD and Cross-Dataset. Comprehensive evaluations on those two groups of few-shot NER datasets containing adversarial examples demonstrate the robustness and superiority of the proposed method.
Seismic Data Interpolation based on Denoising Diffusion Implicit Models with Resampling
Jul 13, 2023The incompleteness of the seismic data caused by missing traces along the spatial extension is a common issue in seismic acquisition due to the existence of obstacles and economic constraints, which severely impairs the imaging quality of subsurface geological structures. Recently, deep learningbased seismic interpolation methods have attained promising progress, while achieving stable training of generative adversarial networks is not easy, and performance degradation is usually notable if the missing patterns in the testing and training do not match. In this paper, we propose a novel seismic denoising diffusion implicit model with resampling. The model training is established on the denoising diffusion probabilistic model, where U-Net is equipped with the multi-head self-attention to match the noise in each step. The cosine noise schedule, serving as the global noise configuration, promotes the high utilization of known trace information by accelerating the passage of the excessive noise stages. The model inference utilizes the denoising diffusion implicit model, conditioning on the known traces, to enable high-quality interpolation with fewer diffusion steps. To enhance the coherency between the known traces and the missing traces within each reverse step, the inference process integrates a resampling strategy to achieve an information recap on the former interpolated traces. Extensive experiments conducted on synthetic and field seismic data validate the superiority of our model and its robustness to various missing patterns. In addition, uncertainty quantification and ablation studies are also investigated.
Leveraging Uncertainty Quantification for Picking Robust First Break Times
May 23, 2023



In seismic exploration, the selection of first break times is a crucial aspect in the determination of subsurface velocity models, which in turn significantly influences the placement of wells. Many deep neural network (DNN)-based automatic first break picking methods have been proposed to speed up this picking processing. However, there has been no work on the uncertainty of the first picking results of the output of DNN. In this paper, we propose a new framework for first break picking based on a Bayesian neural network to further explain the uncertainty of the output. In a large number of experiments, we evaluate that the proposed method has better accuracy and robustness than the deterministic DNN-based model. In addition, we also verify that the uncertainty of measurement is meaningful, which can provide a reference for human decision-making.
MSSPN: Automatic First Arrival Picking using Multi-Stage Segmentation Picking Network
Sep 07, 2022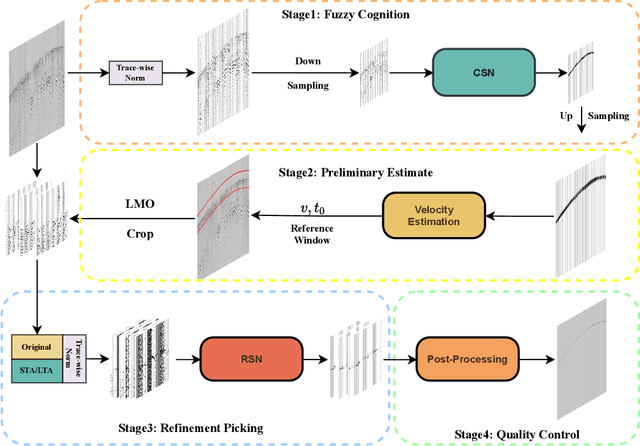

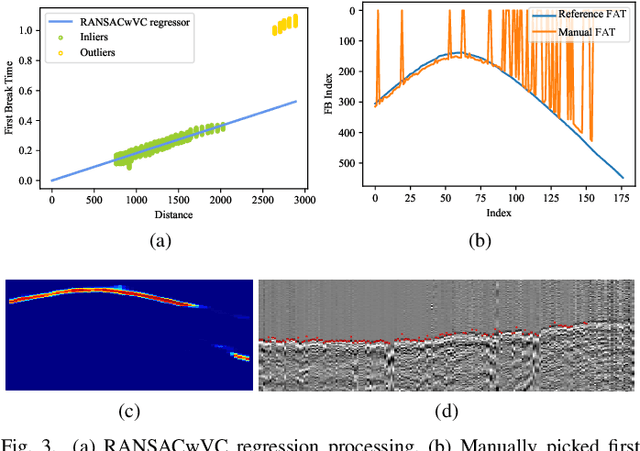
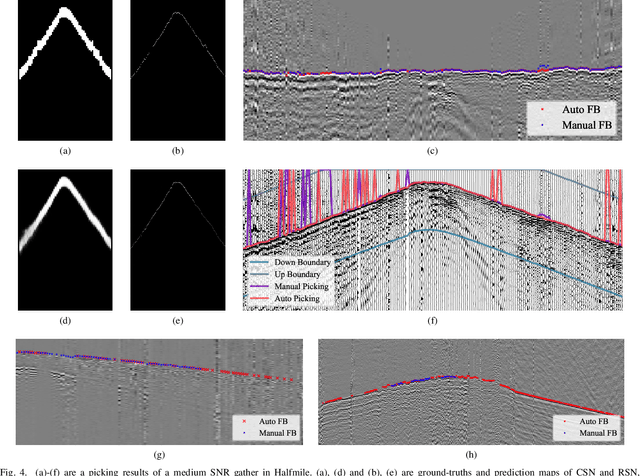
Picking the first arrival times of prestack gathers is called First Arrival Time (FAT) picking, which is an indispensable step in seismic data processing, and is mainly solved manually in the past. With the current increasing density of seismic data collection, the efficiency of manual picking has been unable to meet the actual needs. Therefore, automatic picking methods have been greatly developed in recent decades, especially those based on deep learning. However, few of the current supervised deep learning-based method can avoid the dependence on labeled samples. Besides, since the gather data is a set of signals which are greatly different from the natural images, it is difficult for the current method to solve the FAT picking problem in case of a low Signal to Noise Ratio (SNR). In this paper, for hard rock seismic gather data, we propose a Multi-Stage Segmentation Pickup Network (MSSPN), which solves the generalization problem across worksites and the picking problem in the case of low SNR. In MSSPN, there are four sub-models to simulate the manually picking processing, which is assumed to four stages from coarse to fine. Experiments on seven field datasets with different qualities show that our MSSPN outperforms benchmarks by a large margin.Particularly, our method can achieve more than 90\% accurate picking across worksites in the case of medium and high SNRs, and even fine-tuned model can achieve 88\% accurate picking of the dataset with low SNR.