 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Dropout: Feature Map Distortion to Regularize Deep Neural Networks
Feb 23, 2020
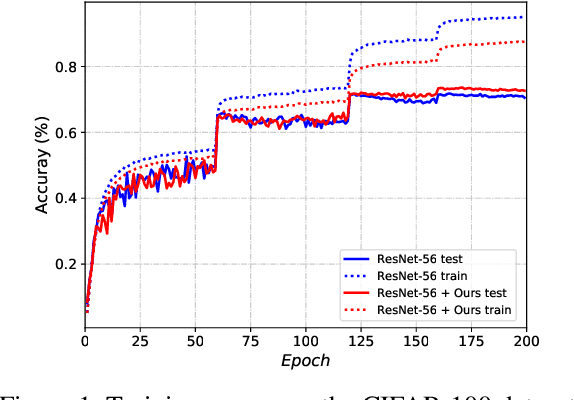

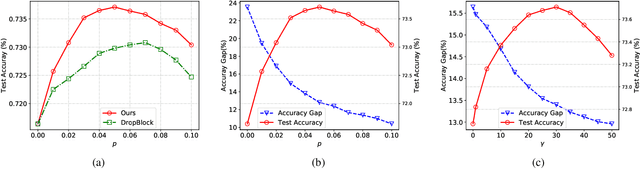
Deep neural networks often consist of a great number of trainable parameters for extracting powerful features from given datasets. On one hand, massive trainable parameters significantly enhance the performance of these deep networks. On the other hand, they bring the problem of over-fitting. To this end, dropout based methods disable some elements in the output feature maps during the training phase for reducing the co-adaptation of neurons. Although the generalization ability of the resulting models can be enhanced by these approaches, the conventional binary dropout is not the optimal solution. Therefore, we investigate the empirical Rademacher complexity related to intermediate layers of deep neural networks and propose a feature distortion method (Disout) for addressing the aforementioned problem. In the training period, randomly selected elements in the feature maps will be replaced with specific values by exploiting the generalization error bound. The superiority of the proposed feature map distortion for producing deep neural network with higher testing performance is analyzed and demonstrated on several benchmark image datasets.
Widening and Squeezing: Towards Accurate and Efficient QNNs
Feb 12, 2020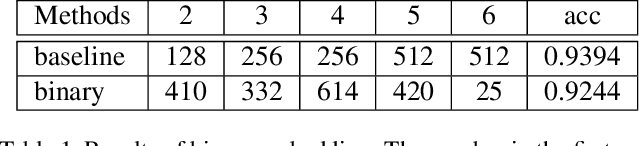
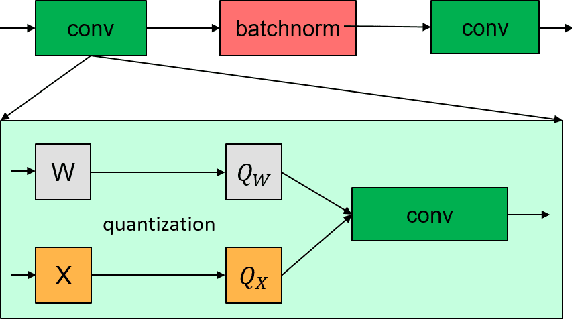
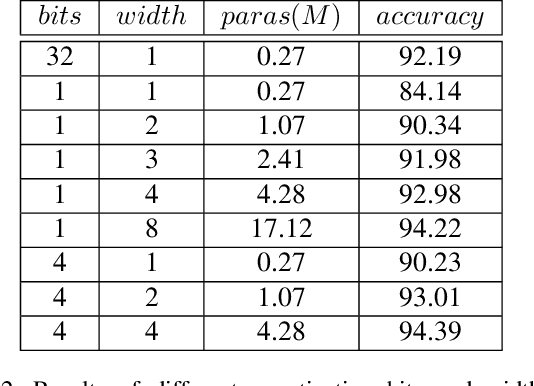
Quantization neural networks (QNNs) are very attractive to the industry because their extremely cheap calculation and storage overhead, but their performance is still worse than that of networks with full-precision parameters. Most of existing methods aim to enhance performance of QNNs especially binary neural networks by exploiting more effective training techniques. However, we find the representation capability of quantization features is far weaker than full-precision features by experiments. We address this problem by projecting features in original full-precision networks to high-dimensional quantization features. Simultaneously, redundant quantization features will be eliminated in order to avoid unrestricted growth of dimensions for some datasets. Then, a compact quantization neural network but with sufficient representation ability will be established. Experimental results on benchmark datasets demonstrate that the proposed method is able to establish QNNs with much less parameters and calculations but almost the same performance as that of full-precision baseline models, e.g. $29.9\%$ top-1 error of binary ResNet-18 on the ImageNet ILSVRC 2012 dataset.
AdderNet: Do We Really Need Multiplications in Deep Learning?
Jan 09, 2020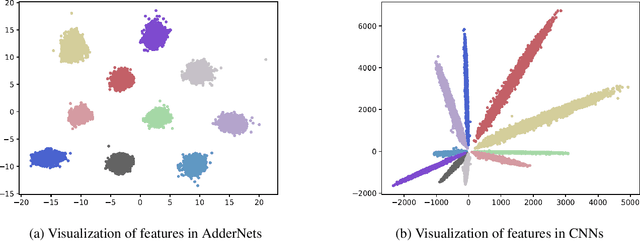
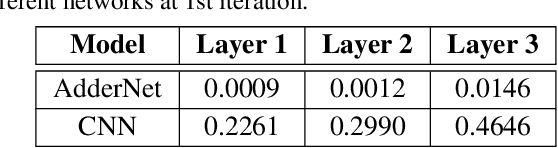
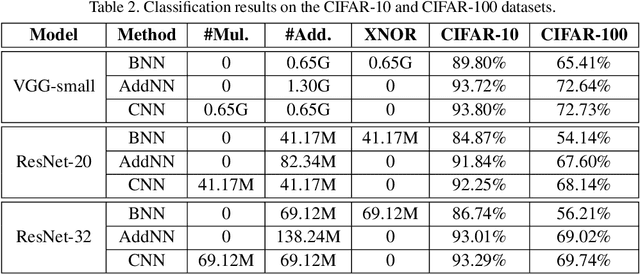
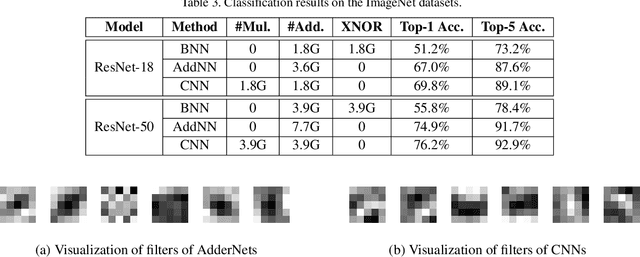
Compared with cheap addition operation, multiplication operation is of much higher computation complexity. The widely-used convolutions in deep neural networks are exactly cross-correlation to measure the similarity between input feature and convolution filters, which involves massive multiplications between float values. In this paper, we present adder networks (AdderNets) to trade these massive multiplications in deep neural networks, especially convolutional neural networks (CNNs), for much cheaper additions to reduce computation costs. In AdderNets, we take the $\ell_1$-norm distance between filters and input feature as the output response. The influence of this new similarity measure on the optimization of neural network have been thoroughly analyzed. To achieve a better performance, we develop a special back-propagation approach for AdderNets by investigating the full-precision gradient. We then propose an adaptive learning rate strategy to enhance the training procedure of AdderNets according to the magnitude of each neuron's gradient. As a result, the proposed AdderNets can achieve 74.9% Top-1 accuracy 91.7% Top-5 accuracy using ResNet-50 on the ImageNet dataset without any multiplication in convolution layer.
GhostNet: More Features from Cheap Operations
Nov 27, 2019
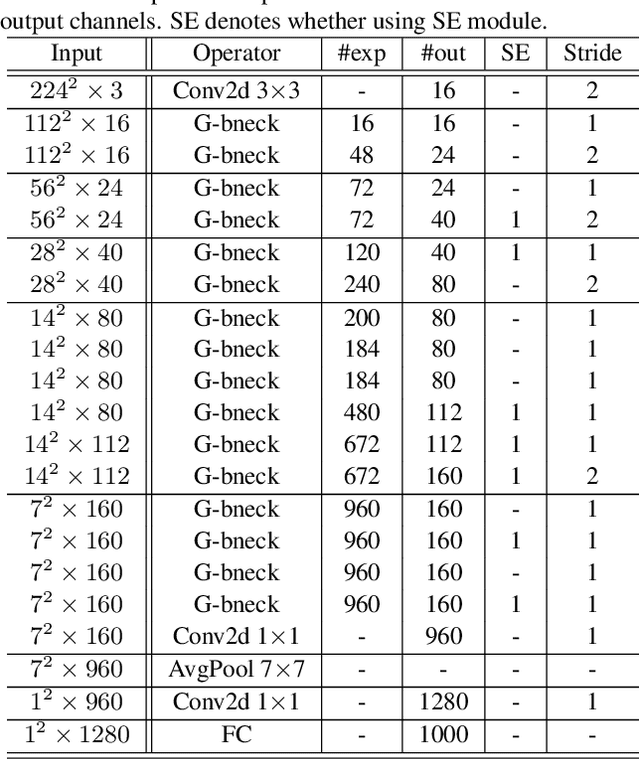
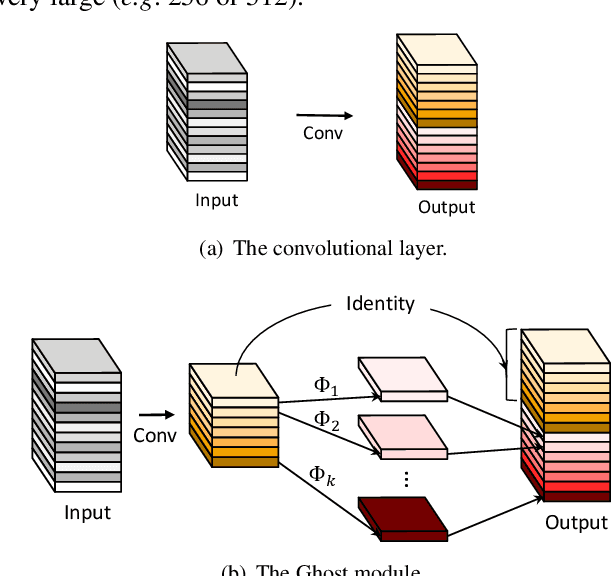
Deploying convolutional neural networks (CNNs) on embedded devices is difficult due to the limited memory and computation resources. The redundancy in feature maps is an important characteristic of those successful CNNs, but has rarely been investigated in neural architecture design. This paper proposes a novel Ghost module to generate more feature maps from cheap operations. Based on a set of intrinsic feature maps, we apply a series of linear transformations with cheap cost to generate many ghost feature maps that could fully reveal information underlying intrinsic features. The proposed Ghost module can be taken as a plug-and-play component to upgrade existing convolutional neural networks. Ghost bottlenecks are designed to stack Ghost modules, and then the lightweight GhostNet can be easily established. Experiments conducted on benchmarks demonstrate that the proposed Ghost module is an impressive alternative of convolution layers in baseline models, and our GhostNet can achieve higher recognition performance (\eg $75.7\%$ top-1 accuracy) than MobileNetV3 with similar computational cost on the ImageNet ILSVRC-2012 classification dataset. Code is available at https://github.com/iamhankai/ghostnet.
Unsupervised Image Super-Resolution with an Indirect Supervised Path
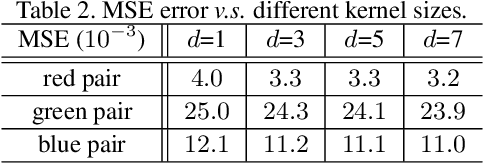
Oct 13, 2019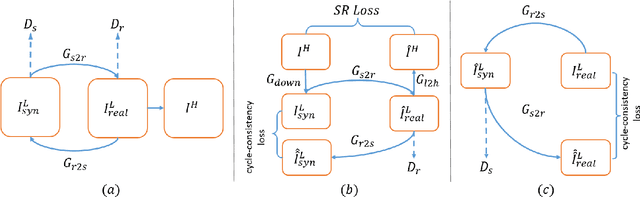



The task of single image super-resolution (SISR) aims at reconstructing a high-resolution (HR) image from a low-resolution (LR) image. Although significant progress has been made by deep learning models, they are trained on synthetic paired data in a supervised way and do not perform well on real data. There are several attempts that directly apply unsupervised image translation models to address such a problem. However, unsupervised low-level vision problem poses more challenge on the accuracy of translation. In this work,we propose a novel framework which is composed of two stages: 1) unsupervised image translation between real LR images and synthetic LR images; 2) supervised super-resolution from approximated real LR images to HR images. It takes the synthetic LR images as a bridge and creates an indirect supervised path from real LR images to HR images. Any existed deep learning based image super-resolution model can be integrated into the second stage of the proposed framework for further improvement. In addition it shows great flexibility in balancing between distortion and perceptual quality under unsupervised setting. The proposed method is evaluated on both NTIRE 2017 and 2018 challenge datasets and achieves favorable performance against supervised methods.
RNAS: Architecture Ranking for Powerful Networks
Oct 09, 2019
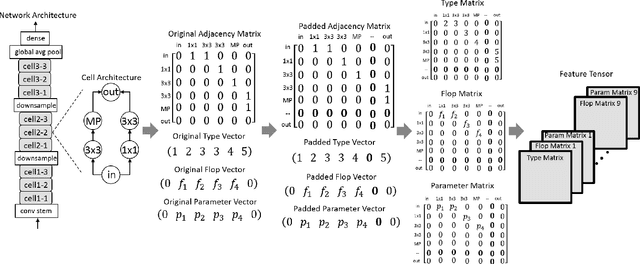
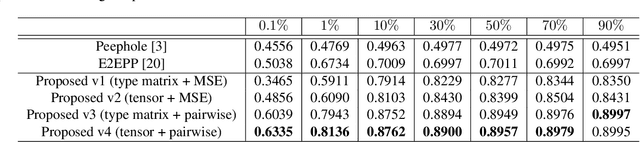
Neural Architecture Search (NAS) is attractive for automatically producing deep networks with excellent performance and acceptable computational costs. The performance of intermediate networks in most of existing NAS algorithms are usually represented by the results evaluated on a small proxy dataset with insufficient training in order to save computational resources and time. Although these representations could help us to distinct some searched architectures, they are still far away from the exact performance or ranking orders of all networks sampled from the given search space. Therefore, we propose to learn a performance predictor for ranking different models in the searching period using few networks pre-trained on the entire dataset. We represent each neural architecture as a feature tensor and use the predictor to further refining the representations of networks in the search space. The resulting performance predictor can be utilized for searching desired architectures without additional evaluation. Experimental results illustrate that, we can only use $0.1\%$ (424 models) of the entire NASBench dataset to construct an accurate predictor for efficiently finding the architecture with $93.90\%$ accuracy ($0.04\%$ top performance in the whole search space), which is about $0.5\%$ higher than that of the state-of-the-art methods.
Positive-Unlabeled Compression on the Cloud
Oct 08, 2019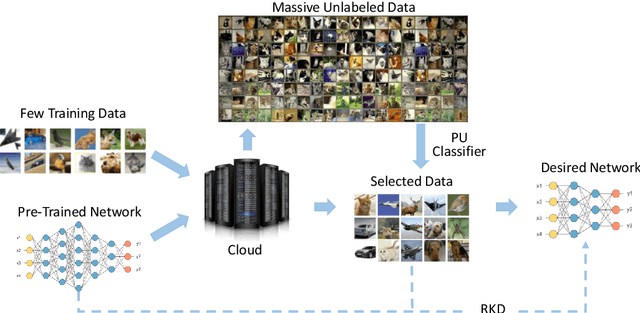
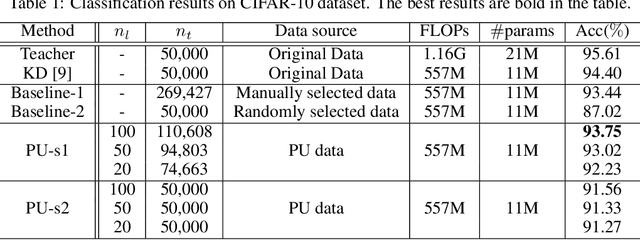
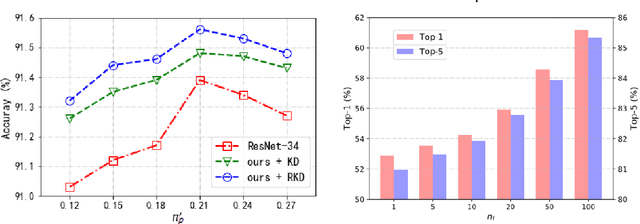
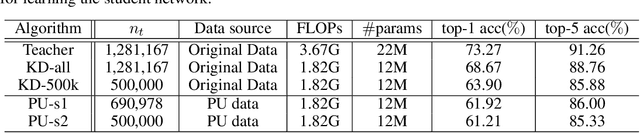
Many attempts have been done to extend the great success of convolutional neural networks (CNNs) achieved on high-end GPU servers to portable devices such as smart phones. Providing compression and acceleration service of deep learning models on the cloud is therefore of significance and is attractive for end users. However, existing network compression and acceleration approaches usually fine-tuning the svelte model by requesting the entire original training data (\eg ImageNet), which could be more cumbersome than the network itself and cannot be easily uploaded to the cloud. In this paper, we present a novel positive-unlabeled (PU) setting for addressing this problem. In practice, only a small portion of the original training set is required as positive examples and more useful training examples can be obtained from the massive unlabeled data on the cloud through a PU classifier with an attention based multi-scale feature extractor. We further introduce a robust knowledge distillation (RKD) scheme to deal with the class imbalance problem of these newly augmented training examples. The superiority of the proposed method is verified through experiments conducted on the benchmark models and datasets. We can use only $8\%$ of uniformly selected data from the ImageNet to obtain an efficient model with comparable performance to the baseline ResNet-34.
Efficient Residual Dense Block Search for Image Super-Resolution
Sep 27, 2019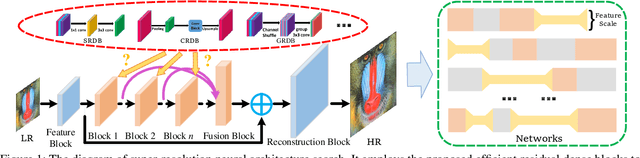
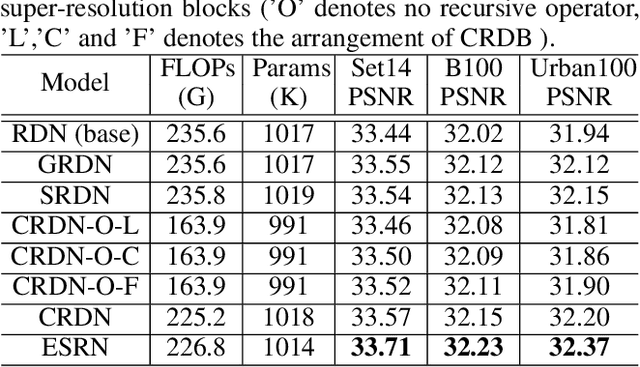
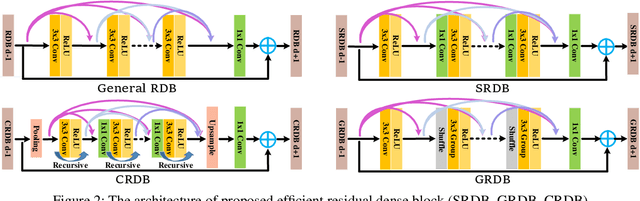
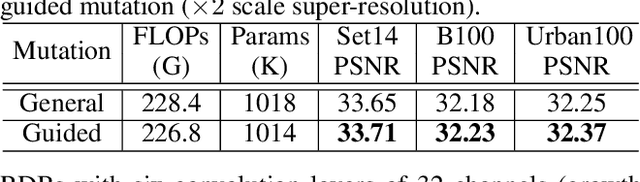
Although remarkable progress has been made on single image super-resolution due to the revival of deep convolutional neural networks, deep learning methods are confronted with the challenges of computation and memory consumption in practice, especially for mobile devices. Focusing on this issue, we propose an efficient residual dense block search algorithm with multiple objectives to hunt for fast, lightweight and accurate networks for image super-resolution. Firstly, to accelerate super-resolution network, we exploit the variation of feature scale adequately with the proposed efficient residual dense blocks. In the proposed evolutionary algorithm, the locations of pooling and upsampling operator are searched automatically. Secondly, network architecture is evolved with the guidance of block credits to acquire accurate super-resolution network. The block credit reflects the effect of current block and is earned during model evaluation process. It guides the evolution by weighing the sampling probability of mutation to favor admirable blocks. Extensive experimental results demonstrate the effectiveness of the proposed searching method and the found efficient super-resolution models achieve better performance than the state-of-the-art methods with limited number of parameters and FLOPs.
CARS: Continuous Evolution for Efficient Neural Architecture Search
Sep 17, 2019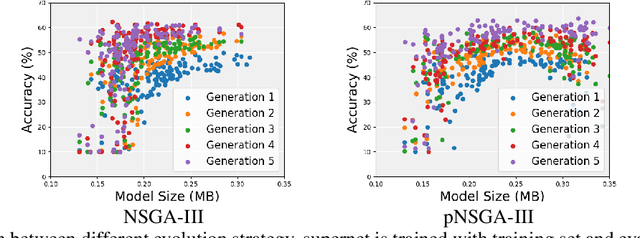
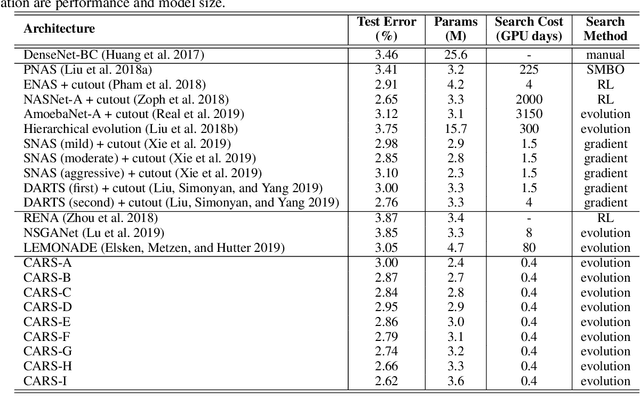
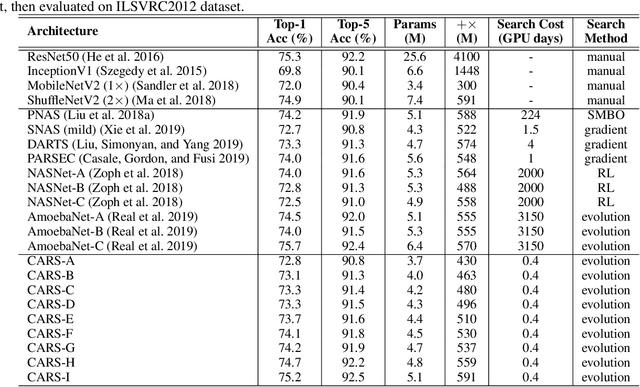
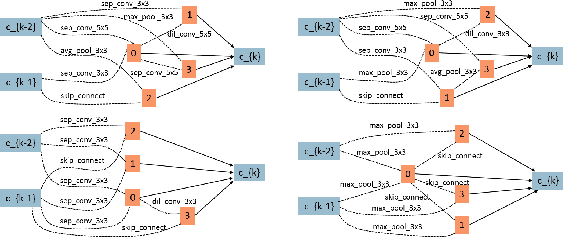
Searching techniques in most of existing neural architecture search (NAS) algorithms are mainly dominated by differentiable methods for the efficiency reason. In contrast, we develop an efficient continuous evolutionary approach for searching neural networks. Architectures in the population which share parameters within one supernet in the latest iteration will be tuned over the training dataset with a few epochs. The searching in the next evolution iteration will directly inherit both the supernet and the population, which accelerates the optimal network generation. The non-dominated sorting strategy is further applied to preserve only results on the Pareto front for accurately updating the supernet. Several neural networks with different model sizes and performance will be produced after the continuous search with only 0.4 GPU days. As a result, our framework provides a series of networks with the number of parameters ranging from 3.7M to 5.1M under mobile settings. These networks surpass those produced by the state-of-the-art methods on the benchmark ImageNet dataset.
Searching for Accurate Binary Neural Architectures
Sep 16, 2019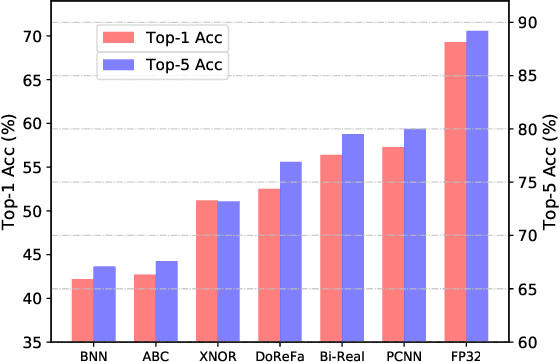
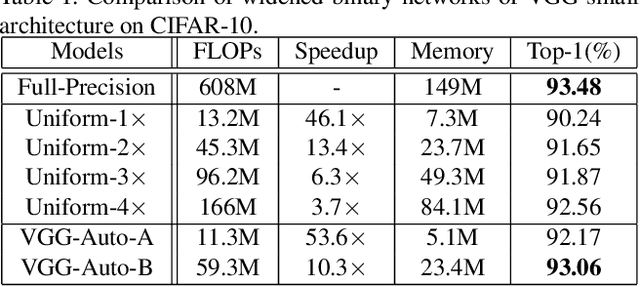
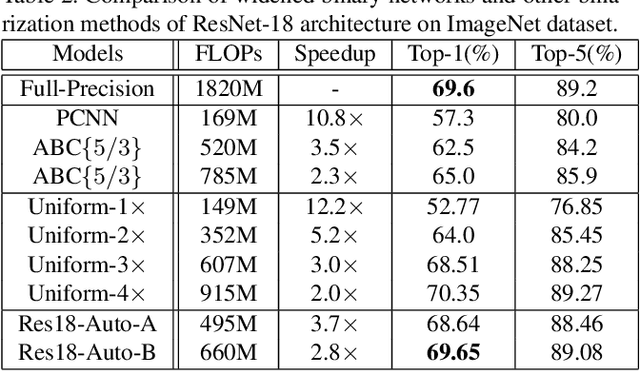
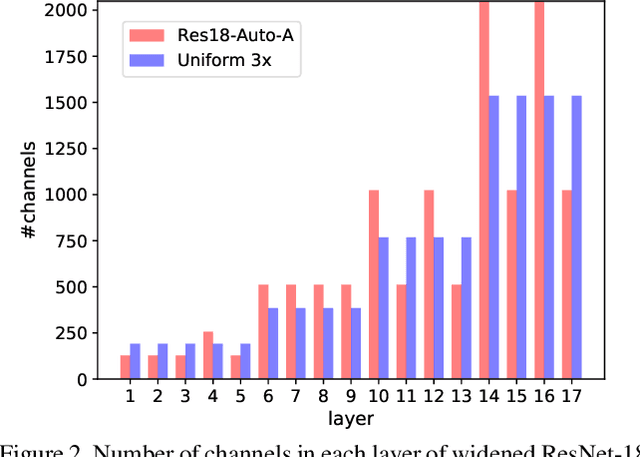
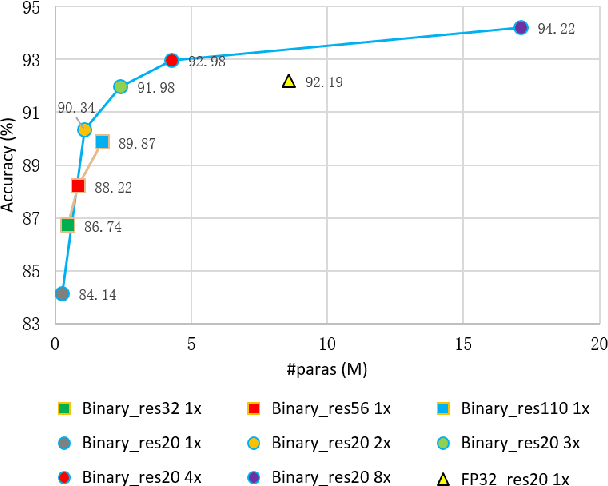
Binary neural networks have attracted tremendous attention due to the efficiency for deploying them on mobile devices. Since the weak expression ability of binary weights and features, their accuracy is usually much lower than that of full-precision (i.e. 32-bit) models. Here we present a new frame work for automatically searching for compact but accurate binary neural networks. In practice, number of channels in each layer will be encoded into the search space and optimized using the evolutionary algorithm. Experiments conducted on benchmark datasets and neural architectures demonstrate that our searched binary networks can achieve the performance of full-precision models with acceptable increments on model sizes and calculations.