 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStationarity Exploration for Multivariate Time Series Forecasting
Aug 12, 2025Deep learning-based time series forecasting has found widespread applications. Recently, converting time series data into the frequency domain for forecasting has become popular for accurately exploring periodic patterns. However, existing methods often cannot effectively explore stationary information from complex intertwined frequency components. In this paper, we propose a simple yet effective Amplitude-Phase Reconstruct Network (APRNet) that models the inter-relationships of amplitude and phase, which prevents the amplitude and phase from being constrained by different physical quantities, thereby decoupling the distinct characteristics of signals for capturing stationary information. Specifically, we represent the multivariate time series input across sequence and channel dimensions, highlighting the correlation between amplitude and phase at multiple interaction frequencies. We propose a novel Kolmogorov-Arnold-Network-based Local Correlation (KLC) module to adaptively fit local functions using univariate functions, enabling more flexible characterization of stationary features across different amplitudes and phases. This significantly enhances the model's capability to capture time-varying patterns. Extensive experiments demonstrate the superiority of our APRNet against the state-of-the-arts (SOTAs).
Semantic-Enhanced Time-Series Forecasting via Large Language Models
Aug 11, 2025Time series forecasting plays a significant role in finance, energy, meteorology, and IoT applications. Recent studies have leveraged the generalization capabilities of large language models (LLMs) to adapt to time series forecasting, achieving promising performance. However, existing studies focus on token-level modal alignment, instead of bridging the intrinsic modality gap between linguistic knowledge structures and time series data patterns, greatly limiting the semantic representation. To address this issue, we propose a novel Semantic-Enhanced LLM (SE-LLM) that explores the inherent periodicity and anomalous characteristics of time series to embed into the semantic space to enhance the token embedding. This process enhances the interpretability of tokens for LLMs, thereby activating the potential of LLMs for temporal sequence analysis. Moreover, existing Transformer-based LLMs excel at capturing long-range dependencies but are weak at modeling short-term anomalies in time-series data. Hence, we propose a plugin module embedded within self-attention that models long-term and short-term dependencies to effectively adapt LLMs to time-series analysis. Our approach freezes the LLM and reduces the sequence dimensionality of tokens, greatly reducing computational consumption. Experiments demonstrate the superiority performance of our SE-LLM against the state-of-the-art (SOTA) methods.
SAN: Structure-Aware Network for Complex and Long-tailed Chinese Text Recognition
Nov 10, 2024In text recognition, complex glyphs and tail classes have always been factors affecting model performance. Specifically for Chinese text recognition, the lack of shape-awareness can lead to confusion among close complex characters. Since such characters are often tail classes that appear less frequently in the training-set, making it harder for the model to capture its shape information. Hence in this work, we propose a structure-aware network utilizing the hierarchical composition information to improve the recognition performance of complex characters. Implementation-wise, we first propose an auxiliary radical branch and integrate it into the base recognition network as a regularization term, which distills hierarchical composition information into the feature extractor. A Tree-Similarity-based weighting mechanism is then proposed to further utilize the depth information in the hierarchical representation. Experiments demonstrate that the proposed approach can significantly improve the performances of complex characters and tail characters, yielding a better overall performance. Code is available at https://github.com/Levi-ZJY/SAN.
Video-Language Alignment Pre-training via Spatio-Temporal Graph Transformer
Jul 16, 2024



Video-language alignment is a crucial multi-modal task that benefits various downstream applications, e.g., video-text retrieval and video question answering. Existing methods either utilize multi-modal information in video-text pairs or apply global and local alignment techniques to promote alignment precision. However, these methods often fail to fully explore the spatio-temporal relationships among vision tokens within video and across different video-text pairs. In this paper, we propose a novel Spatio-Temporal Graph Transformer module to uniformly learn spatial and temporal contexts for video-language alignment pre-training (dubbed STGT). Specifically, our STGT combines spatio-temporal graph structure information with attention in transformer block, effectively utilizing the spatio-temporal contexts. In this way, we can model the relationships between vision tokens, promoting video-text alignment precision for benefiting downstream tasks. In addition, we propose a self-similarity alignment loss to explore the inherent self-similarity in the video and text. With the initial optimization achieved by contrastive learning, it can further promote the alignment accuracy between video and text. Experimental results on challenging downstream tasks, including video-text retrieval and video question answering, verify the superior performance of our method.
Arbitrary Time Information Modeling via Polynomial Approximation for Temporal Knowledge Graph Embedding
May 01, 2024



Distinguished from traditional knowledge graphs (KGs), temporal knowledge graphs (TKGs) must explore and reason over temporally evolving facts adequately. However, existing TKG approaches still face two main challenges, i.e., the limited capability to model arbitrary timestamps continuously and the lack of rich inference patterns under temporal constraints. In this paper, we propose an innovative TKGE method (PTBox) via polynomial decomposition-based temporal representation and box embedding-based entity representation to tackle the above-mentioned problems. Specifically, we decompose time information by polynomials and then enhance the model's capability to represent arbitrary timestamps flexibly by incorporating the learnable temporal basis tensor. In addition, we model every entity as a hyperrectangle box and define each relation as a transformation on the head and tail entity boxes. The entity boxes can capture complex geometric structures and learn robust representations, improving the model's inductive capability for rich inference patterns. Theoretically, our PTBox can encode arbitrary time information or even unseen timestamps while capturing rich inference patterns and higher-arity relations of the knowledge base. Extensive experiments on real-world datasets demonstrate the effectiveness of our method.
Transformer-based Reasoning for Learning Evolutionary Chain of Events on Temporal Knowledge Graph
May 01, 2024Temporal Knowledge Graph (TKG) reasoning often involves completing missing factual elements along the timeline. Although existing methods can learn good embeddings for each factual element in quadruples by integrating temporal information, they often fail to infer the evolution of temporal facts. This is mainly because of (1) insufficiently exploring the internal structure and semantic relationships within individual quadruples and (2) inadequately learning a unified representation of the contextual and temporal correlations among different quadruples. To overcome these limitations, we propose a novel Transformer-based reasoning model (dubbed ECEformer) for TKG to learn the Evolutionary Chain of Events (ECE). Specifically, we unfold the neighborhood subgraph of an entity node in chronological order, forming an evolutionary chain of events as the input for our model. Subsequently, we utilize a Transformer encoder to learn the embeddings of intra-quadruples for ECE. We then craft a mixed-context reasoning module based on the multi-layer perceptron (MLP) to learn the unified representations of inter-quadruples for ECE while accomplishing temporal knowledge reasoning. In addition, to enhance the timeliness of the events, we devise an additional time prediction task to complete effective temporal information within the learned unified representation. Extensive experiments on six benchmark datasets verify the state-of-the-art performance and the effectiveness of our method.
Inverse-like Antagonistic Scene Text Spotting via Reading-Order Estimation and Dynamic Sampling
Jan 08, 2024Scene text spotting is a challenging task, especially for inverse-like scene text, which has complex layouts, e.g., mirrored, symmetrical, or retro-flexed. In this paper, we propose a unified end-to-end trainable inverse-like antagonistic text spotting framework dubbed IATS, which can effectively spot inverse-like scene texts without sacrificing general ones. Specifically, we propose an innovative reading-order estimation module (REM) that extracts reading-order information from the initial text boundary generated by an initial boundary module (IBM). To optimize and train REM, we propose a joint reading-order estimation loss consisting of a classification loss, an orthogonality loss, and a distribution loss. With the help of IBM, we can divide the initial text boundary into two symmetric control points and iteratively refine the new text boundary using a lightweight boundary refinement module (BRM) for adapting to various shapes and scales. To alleviate the incompatibility between text detection and recognition, we propose a dynamic sampling module (DSM) with a thin-plate spline that can dynamically sample appropriate features for recognition in the detected text region. Without extra supervision, the DSM can proactively learn to sample appropriate features for text recognition through the gradient returned by the recognition module. Extensive experiments on both challenging scene text and inverse-like scene text datasets demonstrate that our method achieves superior performance both on irregular and inverse-like text spotting.
Regression-Oriented Knowledge Distillation for Lightweight Ship Orientation Angle Prediction with Optical Remote Sensing Images
Jul 13, 2023



Ship orientation angle prediction (SOAP) with optical remote sensing images is an important image processing task, which often relies on deep convolutional neural networks (CNNs) to make accurate predictions. This paper proposes a novel framework to reduce the model sizes and computational costs of SOAP models without harming prediction accuracy. First, a new SOAP model called Mobile-SOAP is designed based on MobileNetV2, achieving state-of-the-art prediction accuracy. Four tiny SOAP models are also created by replacing the convolutional blocks in Mobile-SOAP with four small-scale networks, respectively. Then, to transfer knowledge from Mobile-SOAP to four lightweight models, we propose a novel knowledge distillation (KD) framework termed SOAP-KD consisting of a novel feature-based guidance loss and an optimized synthetic samples-based knowledge transfer mechanism. Lastly, extensive experiments on the FGSC-23 dataset confirm the superiority of Mobile-SOAP over existing models and also demonstrate the effectiveness of SOAP-KD in improving the prediction performance of four specially designed tiny models. Notably, by using SOAP-KD, the test mean absolute error of the ShuffleNetV2x1.0-based model is only 8% higher than that of Mobile-SOAP, but its number of parameters and multiply-accumulate operations (MACs) are respectively 61.6% and 60.8% less.
Scene Text Recognition with Single-Point Decoding Network
Sep 05, 2022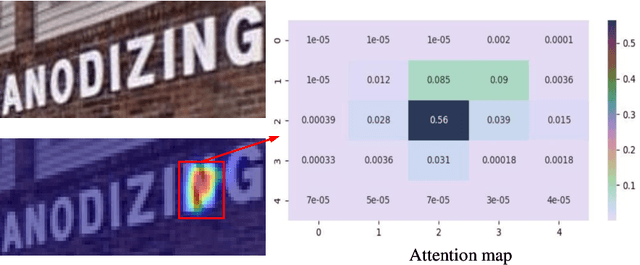
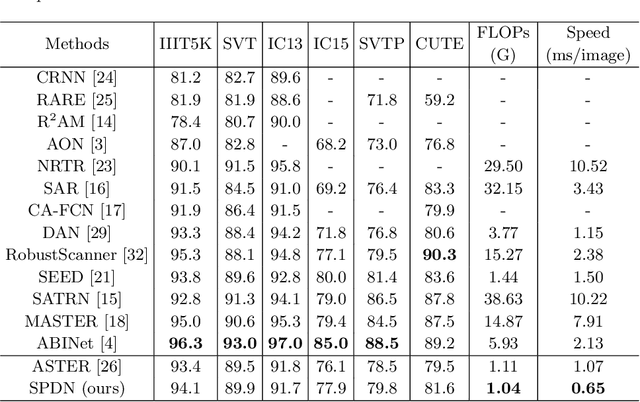
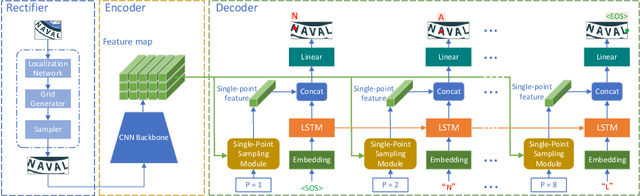
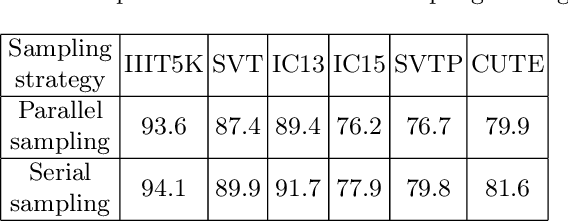
In recent years, attention-based scene text recognition methods have been very popular and attracted the interest of many researchers. Attention-based methods can adaptively focus attention on a small area or even single point during decoding, in which the attention matrix is nearly one-hot distribution. Furthermore, the whole feature maps will be weighted and summed by all attention matrices during inference, causing huge redundant computations. In this paper, we propose an efficient attention-free Single-Point Decoding Network (dubbed SPDN) for scene text recognition, which can replace the traditional attention-based decoding network. Specifically, we propose Single-Point Sampling Module (SPSM) to efficiently sample one key point on the feature map for decoding one character. In this way, our method can not only precisely locate the key point of each character but also remove redundant computations. Based on SPSM, we design an efficient and novel single-point decoding network to replace the attention-based decoding network. Extensive experiments on publicly available benchmarks verify that our SPDN can greatly improve decoding efficiency without sacrificing performance.
SPR:Supervised Personalized Ranking Based on Prior Knowledge for Recommendation
Jul 07, 2022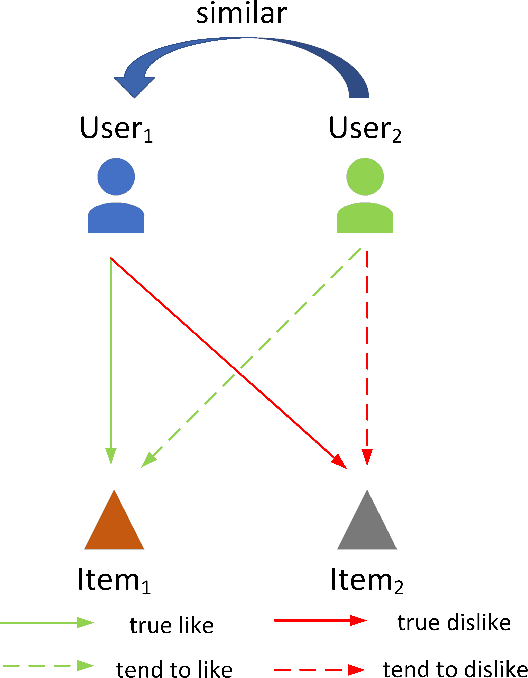

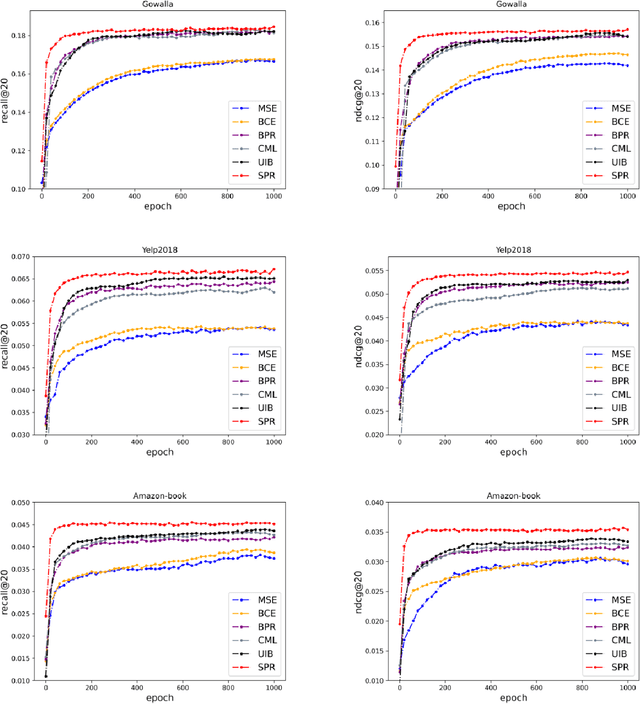
The goal of a recommendation system is to model the relevance between each user and each item through the user-item interaction history, so that maximize the positive samples score and minimize negative samples. Currently, two popular loss functions are widely used to optimize recommender systems: the pointwise and the pairwise. Although these loss functions are widely used, however, there are two problems. (1) These traditional loss functions do not fit the goals of recommendation systems adequately and utilize prior knowledge information sufficiently. (2) The slow convergence speed of these traditional loss functions makes the practical application of various recommendation models difficult. To address these issues, we propose a novel loss function named Supervised Personalized Ranking (SPR) Based on Prior Knowledge. The proposed method improves the BPR loss by exploiting the prior knowledge on the interaction history of each user or item in the raw data. Unlike BPR, instead of constructing <user, positive item, negative item> triples, the proposed SPR constructs <user, similar user, positive item, negative item> quadruples. Although SPR is very simple, it is very effective. Extensive experiments show that our proposed SPR not only achieves better recommendation performance, but also significantly accelerates the convergence speed, resulting in a significant reduction in the required training time.