 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEllSeg-Gen, towards Domain Generalization for head-mounted eyetracking
May 04, 2022
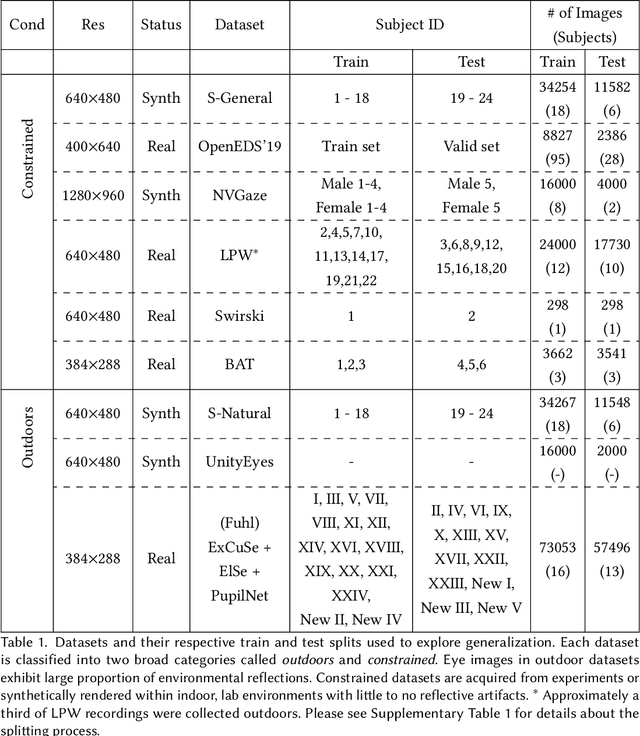
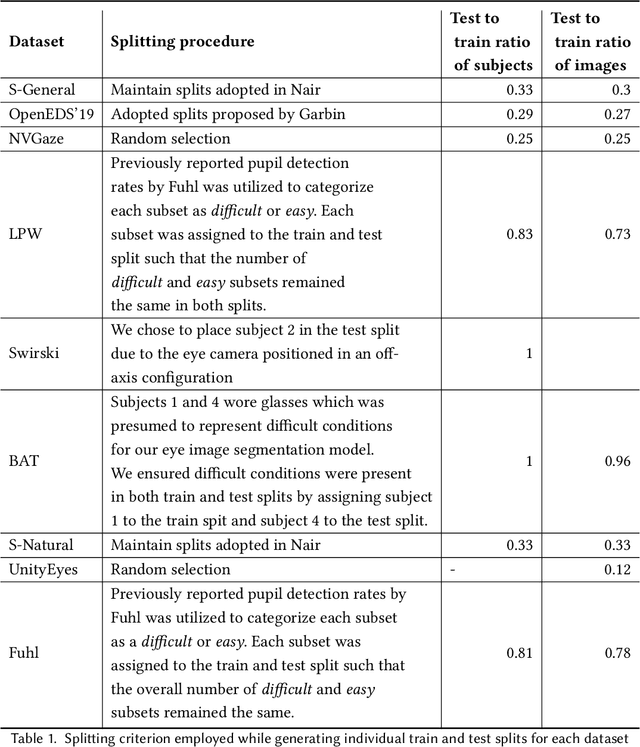
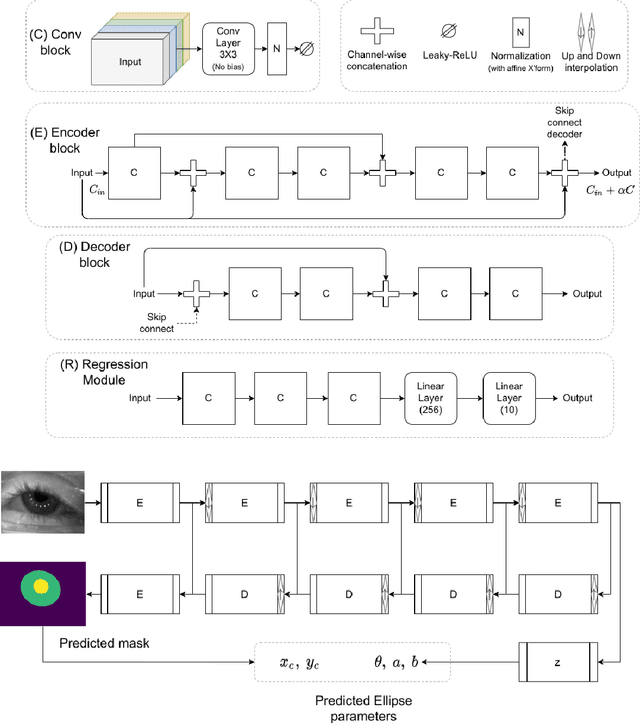
The study of human gaze behavior in natural contexts requires algorithms for gaze estimation that are robust to a wide range of imaging conditions. However, algorithms often fail to identify features such as the iris and pupil centroid in the presence of reflective artifacts and occlusions. Previous work has shown that convolutional networks excel at extracting gaze features despite the presence of such artifacts. However, these networks often perform poorly on data unseen during training. This work follows the intuition that jointly training a convolutional network with multiple datasets learns a generalized representation of eye parts. We compare the performance of a single model trained with multiple datasets against a pool of models trained on individual datasets. Results indicate that models tested on datasets in which eye images exhibit higher appearance variability benefit from multiset training. In contrast, dataset-specific models generalize better onto eye images with lower appearance variability.
OccamNets: Mitigating Dataset Bias by Favoring Simpler Hypotheses
Apr 11, 2022
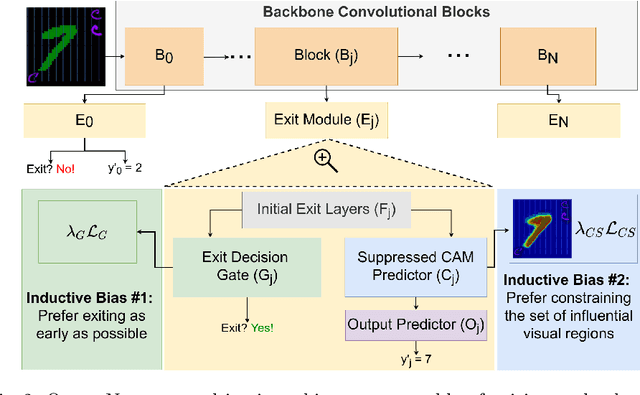


Dataset bias and spurious correlations can significantly impair generalization in deep neural networks. Many prior efforts have addressed this problem using either alternative loss functions or sampling strategies that focus on rare patterns. We propose a new direction: modifying the network architecture to impose inductive biases that make the network robust to dataset bias. Specifically, we propose OccamNets, which are biased to favor simpler solutions by design. OccamNets have two inductive biases. First, they are biased to use as little network depth as needed for an individual example. Second, they are biased toward using fewer image locations for prediction. While OccamNets are biased toward simpler hypotheses, they can learn more complex hypotheses if necessary. In experiments, OccamNets outperform or rival state-of-the-art methods run on architectures that do not incorporate these inductive biases. Furthermore, we demonstrate that when the state-of-the-art debiasing methods are combined with OccamNets results further improve.
Semantic Segmentation with Active Semi-Supervised Learning
Mar 21, 2022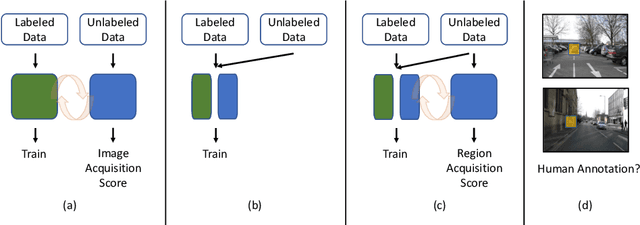

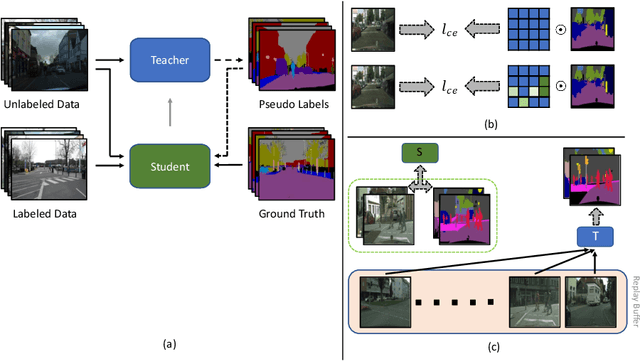
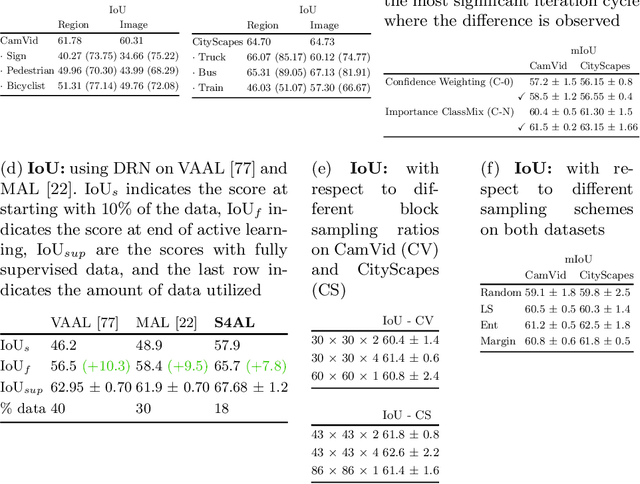
Using deep learning, we now have the ability to create exceptionally good semantic segmentation systems; however, collecting the prerequisite pixel-wise annotations for training images remains expensive and time-consuming. Therefore, it would be ideal to minimize the number of human annotations needed when creating a new dataset. Here, we address this problem by proposing a novel algorithm that combines active learning and semi-supervised learning. Active learning is an approach for identifying the best unlabeled samples to annotate. While there has been work on active learning for segmentation, most methods require annotating all pixel objects in each image, rather than only the most informative regions. We argue that this is inefficient. Instead, our active learning approach aims to minimize the number of annotations per-image. Our method is enriched with semi-supervised learning, where we use pseudo labels generated with a teacher-student framework to identify image regions that help disambiguate confused classes. We also integrate mechanisms that enable better performance on imbalanced label distributions, which have not been studied previously for active learning in semantic segmentation. In experiments on the CamVid and CityScapes datasets, our method obtains over 95% of the network's performance on the full-training set using less than 19% of the training data, whereas the previous state of the art required 40% of the training data.
Online Continual Learning for Embedded Devices
Mar 21, 2022
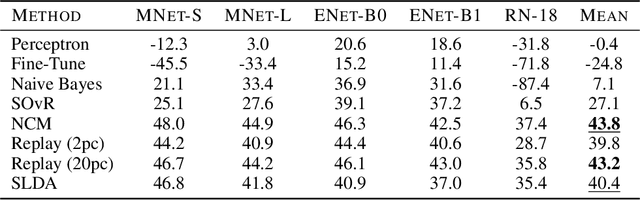

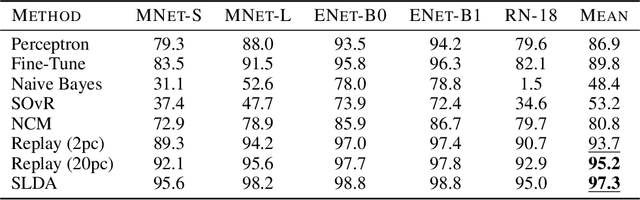
Real-time on-device continual learning is needed for new applications such as home robots, user personalization on smartphones, and augmented/virtual reality headsets. However, this setting poses unique challenges: embedded devices have limited memory and compute capacity and conventional machine learning models suffer from catastrophic forgetting when updated on non-stationary data streams. While several online continual learning models have been developed, their effectiveness for embedded applications has not been rigorously studied. In this paper, we first identify criteria that online continual learners must meet to effectively perform real-time, on-device learning. We then study the efficacy of several online continual learning methods when used with mobile neural networks. We measure their performance, memory usage, compute requirements, and ability to generalize to out-of-domain inputs.
Can I see an Example? Active Learning the Long Tail of Attributes and Relations
Mar 11, 2022
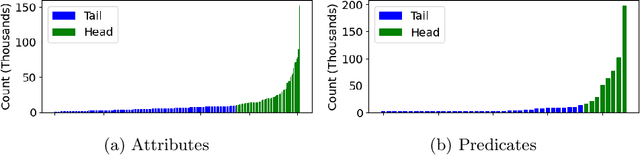
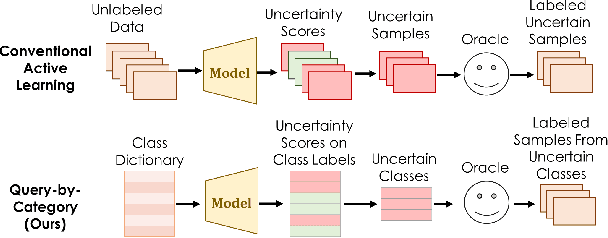
There has been significant progress in creating machine learning models that identify objects in scenes along with their associated attributes and relationships; however, there is a large gap between the best models and human capabilities. One of the major reasons for this gap is the difficulty in collecting sufficient amounts of annotated relations and attributes for training these systems. While some attributes and relations are abundant, the distribution in the natural world and existing datasets is long tailed. In this paper, we address this problem by introducing a novel incremental active learning framework that asks for attributes and relations in visual scenes. While conventional active learning methods ask for labels of specific examples, we flip this framing to allow agents to ask for examples from specific categories. Using this framing, we introduce an active sampling method that asks for examples from the tail of the data distribution and show that it outperforms classical active learning methods on Visual Genome.
Detecting out-of-context objects using contextual cues
Feb 11, 2022



This paper presents an approach to detect out-of-context (OOC) objects in an image. Given an image with a set of objects, our goal is to determine if an object is inconsistent with the scene context and detect the OOC object with a bounding box. In this work, we consider commonly explored contextual relations such as co-occurrence relations, the relative size of an object with respect to other objects, and the position of the object in the scene. We posit that contextual cues are useful to determine object labels for in-context objects and inconsistent context cues are detrimental to determining object labels for out-of-context objects. To realize this hypothesis, we propose a graph contextual reasoning network (GCRN) to detect OOC objects. GCRN consists of two separate graphs to predict object labels based on the contextual cues in the image: 1) a representation graph to learn object features based on the neighboring objects and 2) a context graph to explicitly capture contextual cues from the neighboring objects. GCRN explicitly captures the contextual cues to improve the detection of in-context objects and identify objects that violate contextual relations. In order to evaluate our approach, we create a large-scale dataset by adding OOC object instances to the COCO images. We also evaluate on recent OCD benchmark. Our results show that GCRN outperforms competitive baselines in detecting OOC objects and correctly detecting in-context objects.
2nd Place Solution for SODA10M Challenge 2021 -- Continual Detection Track
Oct 25, 2021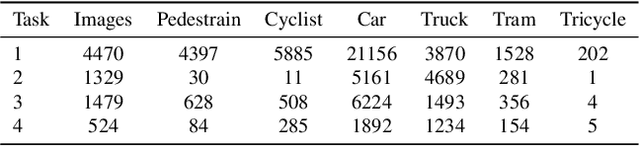
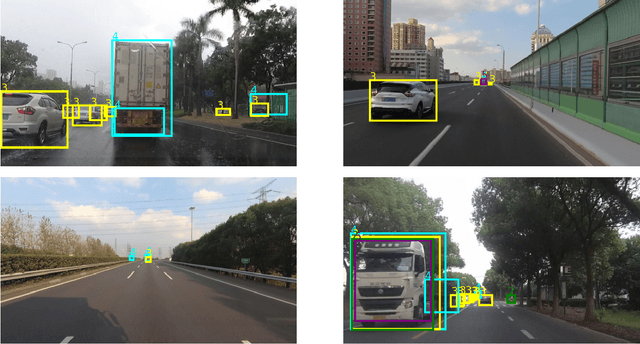
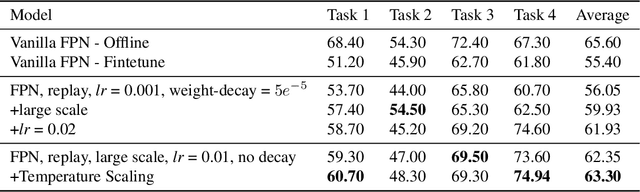

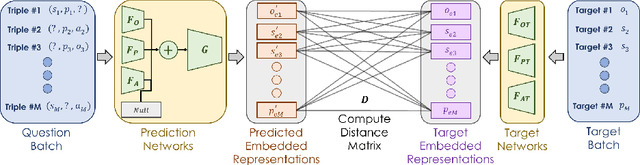
In this technical report, we present our approaches for the continual object detection track of the SODA10M challenge. We adapt ResNet50-FPN as the baseline and try several improvements for the final submission model. We find that task-specific replay scheme, learning rate scheduling, model calibration, and using original image scale helps to improve performance for both large and small objects in images. Our team `hypertune28' secured the second position among 52 participants in the challenge. This work will be presented at the ICCV 2021 Workshop on Self-supervised Learning for Next-Generation Industry-level Autonomous Driving (SSLAD).
Disentangling Transfer and Interference in Multi-Domain Learning
Jul 16, 2021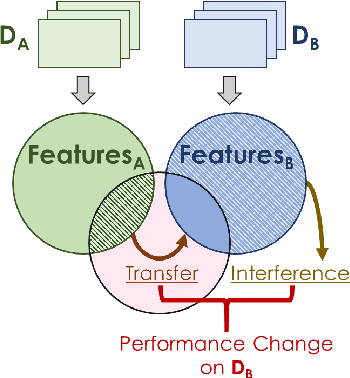
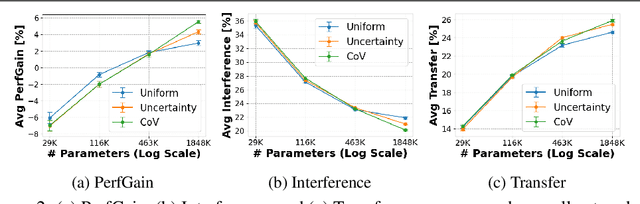
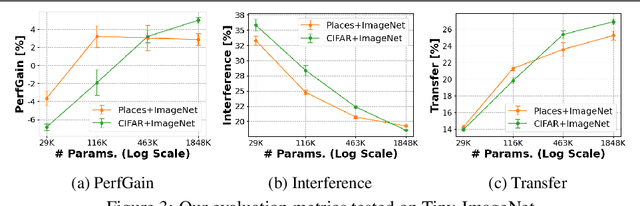
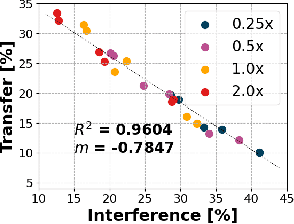
Humans are incredibly good at transferring knowledge from one domain to another, enabling rapid learning of new tasks. Likewise, transfer learning has enabled enormous success in many computer vision problems using pretraining. However, the benefits of transfer in multi-domain learning, where a network learns multiple tasks defined by different datasets, has not been adequately studied. Learning multiple domains could be beneficial or these domains could interfere with each other given limited network capacity. In this work, we decipher the conditions where interference and knowledge transfer occur in multi-domain learning. We propose new metrics disentangling interference and transfer and set up experimental protocols. We further examine the roles of network capacity, task grouping, and dynamic loss weighting in reducing interference and facilitating transfer. We demonstrate our findings on the CIFAR-100, MiniPlaces, and Tiny-ImageNet datasets.
How Does Heterogeneous Label Noise Impact Generalization in Neural Nets?
Jun 29, 2021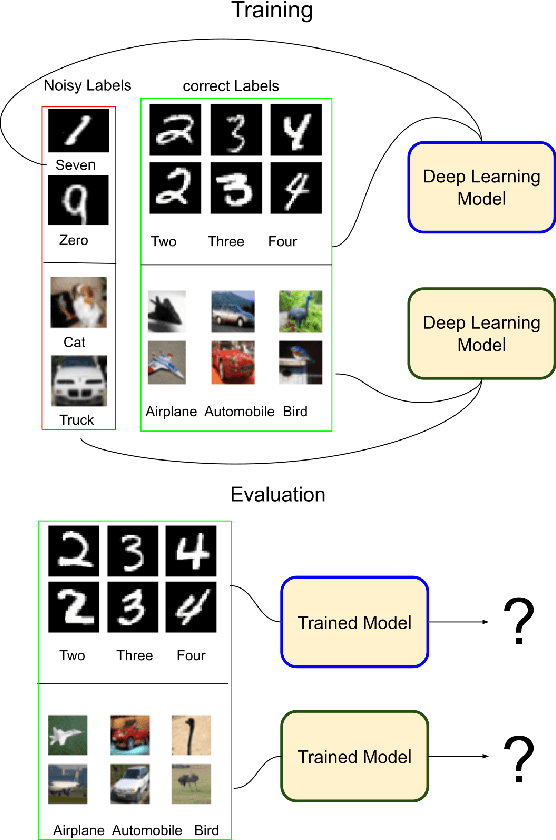
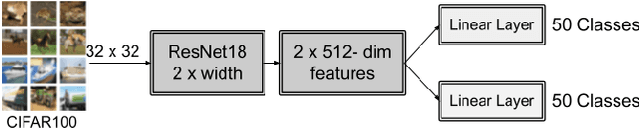
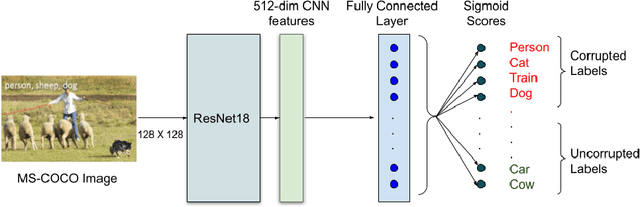

Incorrectly labeled examples, or label noise, is common in real-world computer vision datasets. While the impact of label noise on learning in deep neural networks has been studied in prior work, these studies have exclusively focused on homogeneous label noise, i.e., the degree of label noise is the same across all categories. However, in the real-world, label noise is often heterogeneous, with some categories being affected to a greater extent than others. Here, we address this gap in the literature. We hypothesized that heterogeneous label noise would only affect the classes that had label noise unless there was transfer from those classes to the classes without label noise. To test this hypothesis, we designed a series of computer vision studies using MNIST, CIFAR-10, CIFAR-100, and MS-COCO where we imposed heterogeneous label noise during the training of multi-class, multi-task, and multi-label systems. Our results provide evidence in support of our hypothesis: label noise only affects the class affected by it unless there is transfer.
Replay in Deep Learning: Current Approaches and Missing Biological Elements
Apr 01, 2021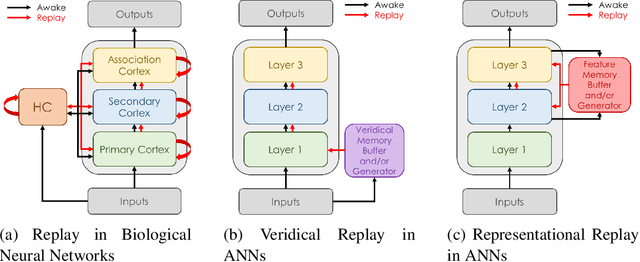
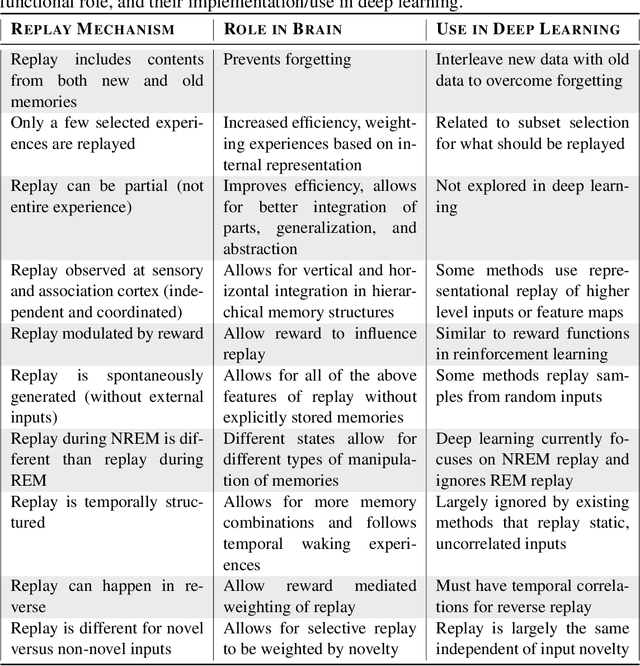
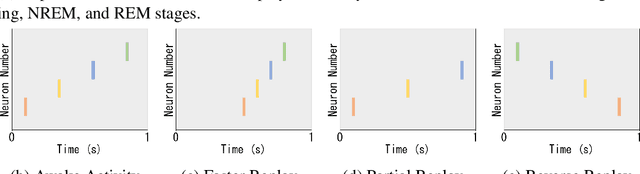
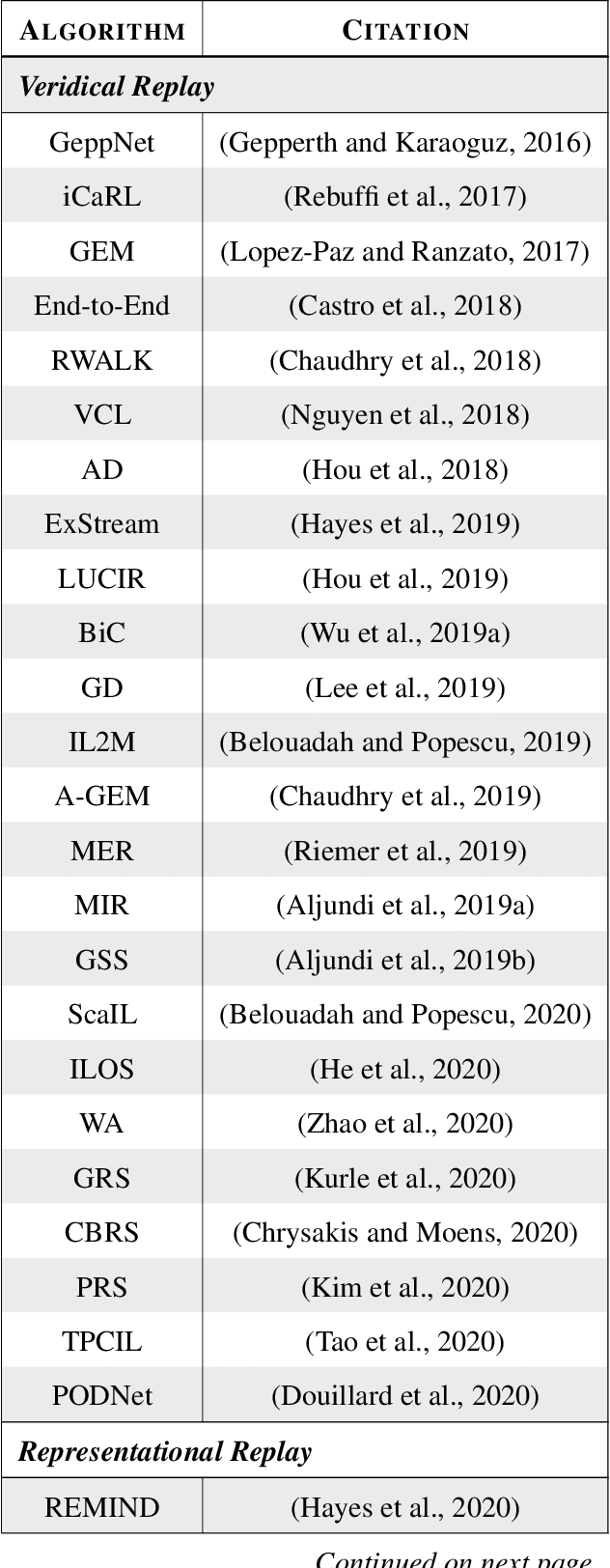
Replay is the reactivation of one or more neural patterns, which are similar to the activation patterns experienced during past waking experiences. Replay was first observed in biological neural networks during sleep, and it is now thought to play a critical role in memory formation, retrieval, and consolidation. Replay-like mechanisms have been incorporated into deep artificial neural networks that learn over time to avoid catastrophic forgetting of previous knowledge. Replay algorithms have been successfully used in a wide range of deep learning methods within supervised, unsupervised, and reinforcement learning paradigms. In this paper, we provide the first comprehensive comparison between replay in the mammalian brain and replay in artificial neural networks. We identify multiple aspects of biological replay that are missing in deep learning systems and hypothesize how they could be utilized to improve artificial neural networks.