 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Neural Abstructions: Abstractions that Support Construction for Grounded Language Learning
Jul 20, 2021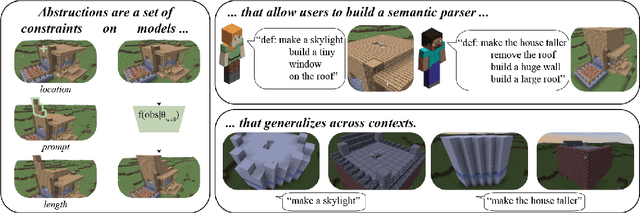
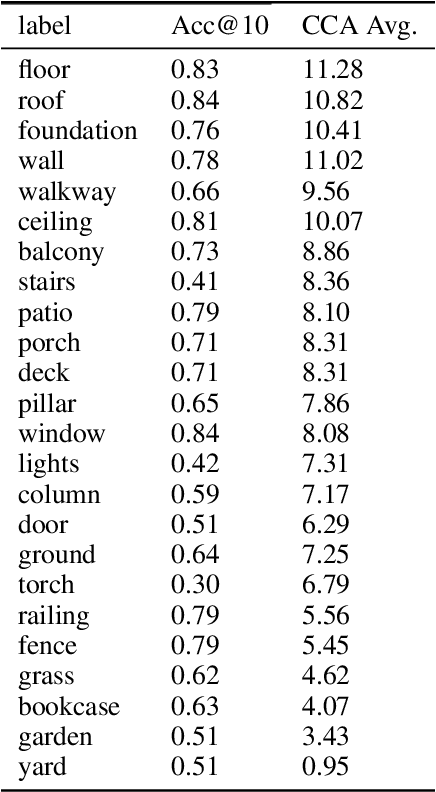
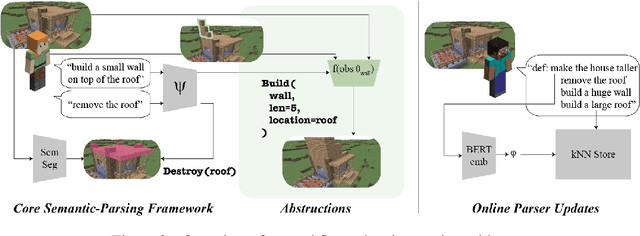
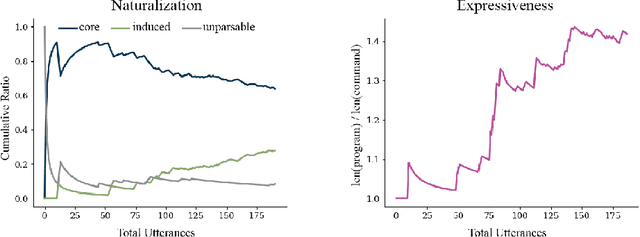
Although virtual agents are increasingly situated in environments where natural language is the most effective mode of interaction with humans, these exchanges are rarely used as an opportunity for learning. Leveraging language interactions effectively requires addressing limitations in the two most common approaches to language grounding: semantic parsers built on top of fixed object categories are precise but inflexible and end-to-end models are maximally expressive, but fickle and opaque. Our goal is to develop a system that balances the strengths of each approach so that users can teach agents new instructions that generalize broadly from a single example. We introduce the idea of neural abstructions: a set of constraints on the inference procedure of a label-conditioned generative model that can affect the meaning of the label in context. Starting from a core programming language that operates over abstructions, users can define increasingly complex mappings from natural language to actions. We show that with this method a user population is able to build a semantic parser for an open-ended house modification task in Minecraft. The semantic parser that results is both flexible and expressive: the percentage of utterances sourced from redefinitions increases steadily over the course of 191 total exchanges, achieving a final value of 28%.
Mind Your Outliers! Investigating the Negative Impact of Outliers on Active Learning for Visual Question Answering
Jul 06, 2021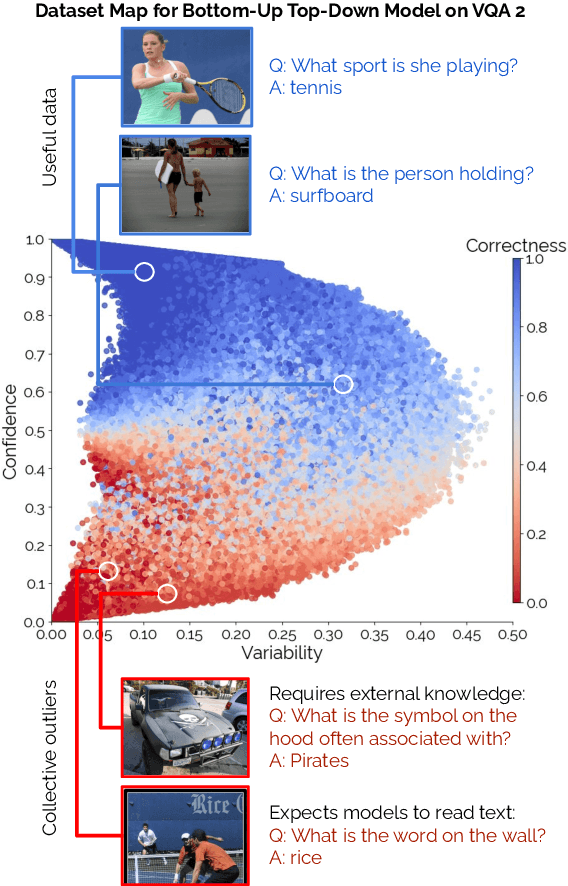
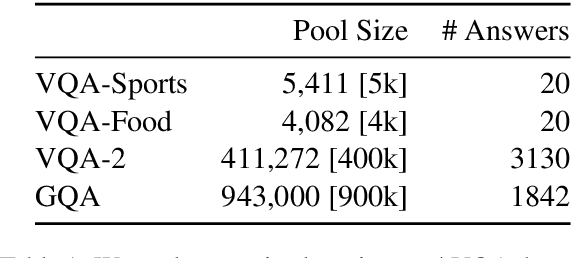
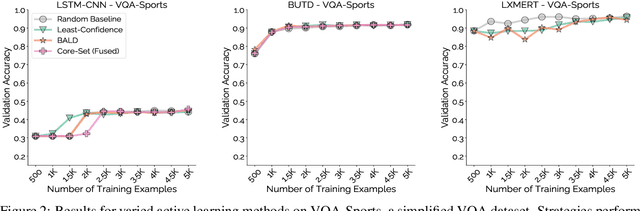
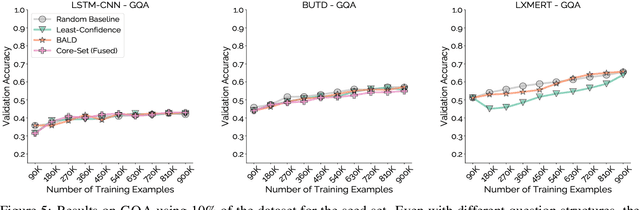
Active learning promises to alleviate the massive data needs of supervised machine learning: it has successfully improved sample efficiency by an order of magnitude on traditional tasks like topic classification and object recognition. However, we uncover a striking contrast to this promise: across 5 models and 4 datasets on the task of visual question answering, a wide variety of active learning approaches fail to outperform random selection. To understand this discrepancy, we profile 8 active learning methods on a per-example basis, and identify the problem as collective outliers -- groups of examples that active learning methods prefer to acquire but models fail to learn (e.g., questions that ask about text in images or require external knowledge). Through systematic ablation experiments and qualitative visualizations, we verify that collective outliers are a general phenomenon responsible for degrading pool-based active learning. Notably, we show that active learning sample efficiency increases significantly as the number of collective outliers in the active learning pool decreases. We conclude with a discussion and prescriptive recommendations for mitigating the effects of these outliers in future work.
Capturing Logical Structure of Visually Structured Documents with Multimodal Transition Parser
May 01, 2021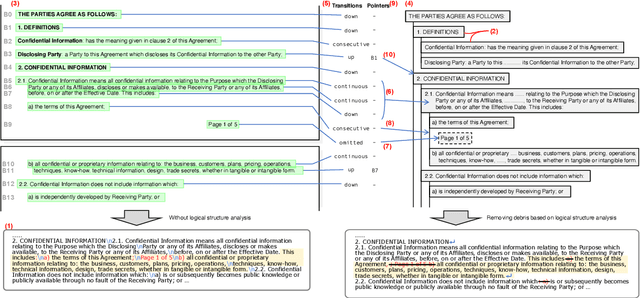

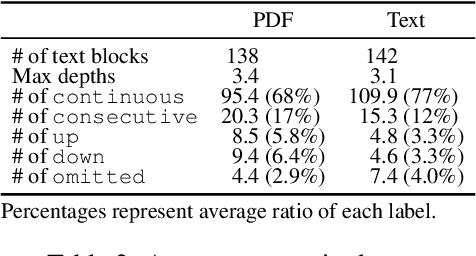
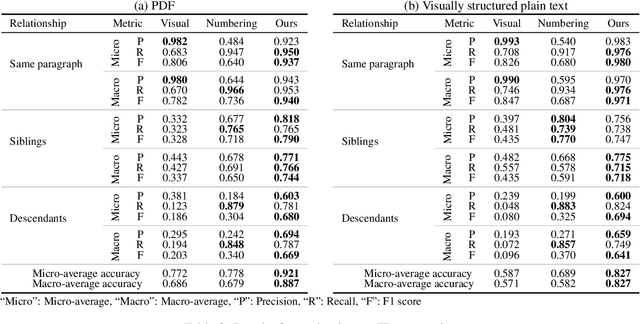
While many NLP papers, tasks and pipelines assume raw, clean texts, many texts we encounter in the wild are not so clean, with many of them being visually structured documents (VSDs) such as PDFs. Conventional preprocessing tools for VSDs mainly focused on word segmentation and coarse layout analysis, while fine-grained logical structure analysis (such as identifying paragraph boundaries and their hierarchies) of VSDs is underexplored. To that end, we proposed to formulate the task as prediction of transition labels between text fragments that maps the fragments to a tree, and developed a feature-based machine learning system that fuses visual, textual and semantic cues. Our system significantly outperformed baselines in identifying different structures in VSDs. For example, our system obtained a paragraph boundary detection F1 score of 0.951 which is significantly better than a popular PDF-to-text tool with a F1 score of 0.739.
Human-like informative conversations: Better acknowledgements using conditional mutual information
Apr 16, 2021
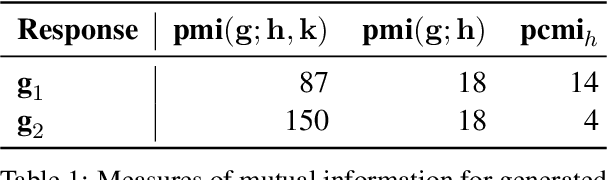

This work aims to build a dialogue agent that can weave new factual content into conversations as naturally as humans. We draw insights from linguistic principles of conversational analysis and annotate human-human conversations from the Switchboard Dialog Act Corpus to examine humans strategies for acknowledgement, transition, detail selection and presentation. When current chatbots (explicitly provided with new factual content) introduce facts into a conversation, their generated responses do not acknowledge the prior turns. This is because models trained with two contexts - new factual content and conversational history - generate responses that are non-specific w.r.t. one of the contexts, typically the conversational history. We show that specificity w.r.t. conversational history is better captured by Pointwise Conditional Mutual Information ($\text{pcmi}_h$) than by the established use of Pointwise Mutual Information ($\text{pmi}$). Our proposed method, Fused-PCMI, trades off $\text{pmi}$ for $\text{pcmi}_h$ and is preferred by humans for overall quality over the Max-PMI baseline 60% of the time. Human evaluators also judge responses with higher $\text{pcmi}_h$ better at acknowledgement 74% of the time. The results demonstrate that systems mimicking human conversational traits (in this case acknowledgement) improve overall quality and more broadly illustrate the utility of linguistic principles in improving dialogue agents.
Pre-Training Transformers as Energy-Based Cloze Models
Dec 15, 2020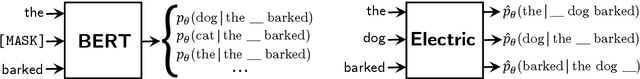
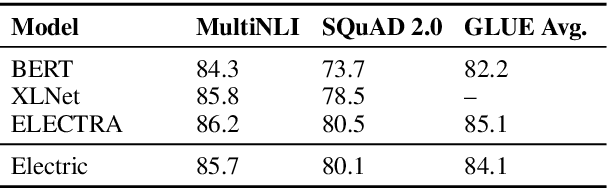
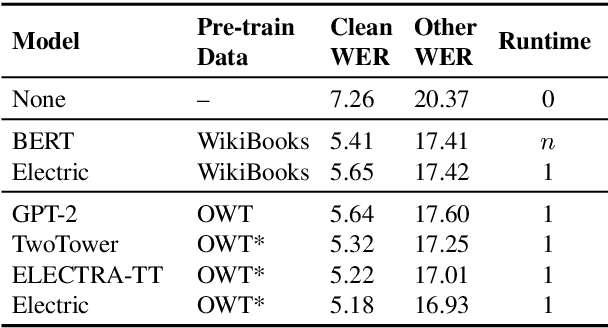
We introduce Electric, an energy-based cloze model for representation learning over text. Like BERT, it is a conditional generative model of tokens given their contexts. However, Electric does not use masking or output a full distribution over tokens that could occur in a context. Instead, it assigns a scalar energy score to each input token indicating how likely it is given its context. We train Electric using an algorithm based on noise-contrastive estimation and elucidate how this learning objective is closely related to the recently proposed ELECTRA pre-training method. Electric performs well when transferred to downstream tasks and is particularly effective at producing likelihood scores for text: it re-ranks speech recognition n-best lists better than language models and much faster than masked language models. Furthermore, it offers a clearer and more principled view of what ELECTRA learns during pre-training.
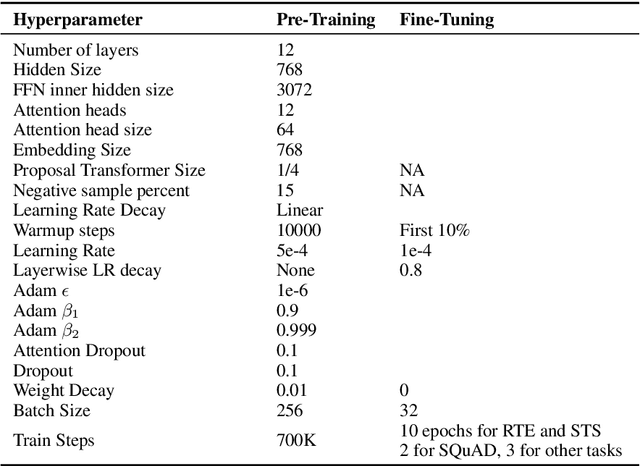
SLM: Learning a Discourse Language Representation with Sentence Unshuffling
Oct 30, 2020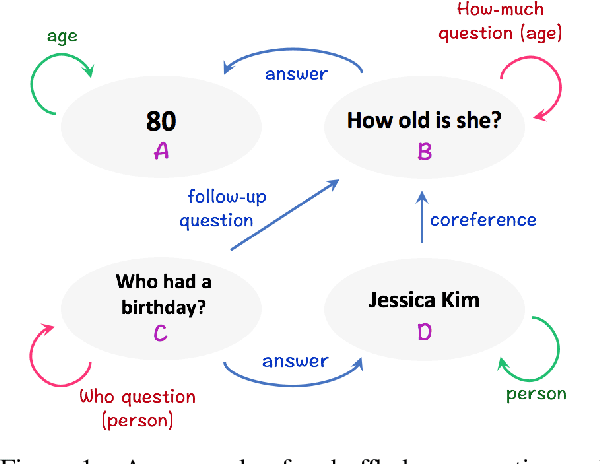
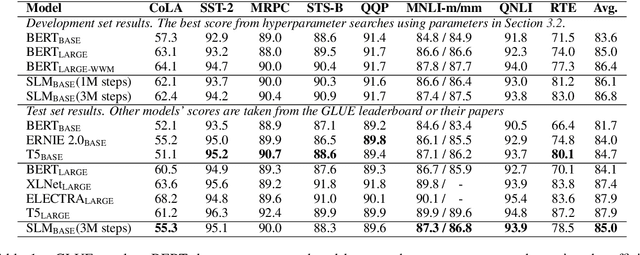
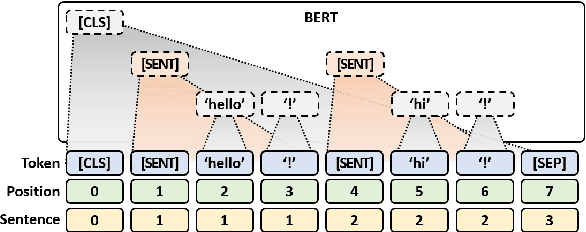
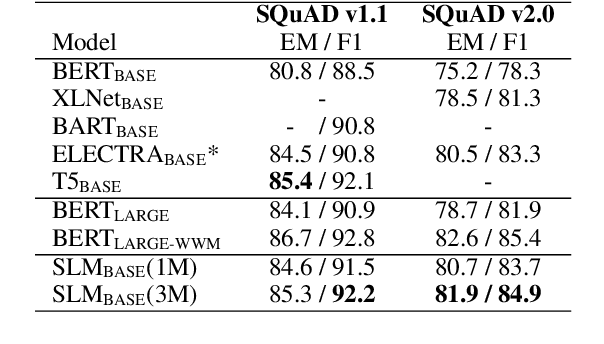
We introduce Sentence-level Language Modeling, a new pre-training objective for learning a discourse language representation in a fully self-supervised manner. Recent pre-training methods in NLP focus on learning either bottom or top-level language representations: contextualized word representations derived from language model objectives at one extreme and a whole sequence representation learned by order classification of two given textual segments at the other. However, these models are not directly encouraged to capture representations of intermediate-size structures that exist in natural languages such as sentences and the relationships among them. To that end, we propose a new approach to encourage learning of a contextualized sentence-level representation by shuffling the sequence of input sentences and training a hierarchical transformer model to reconstruct the original ordering. Through experiments on downstream tasks such as GLUE, SQuAD, and DiscoEval, we show that this feature of our model improves the performance of the original BERT by large margins.
Retrieve, Rerank, Read, then Iterate: Answering Open-Domain Questions of Arbitrary Complexity from Text
Oct 23, 2020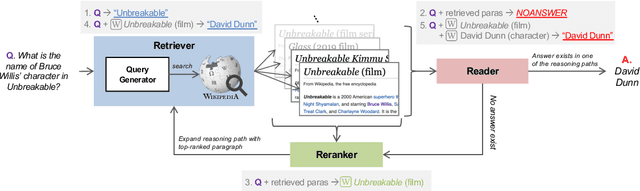
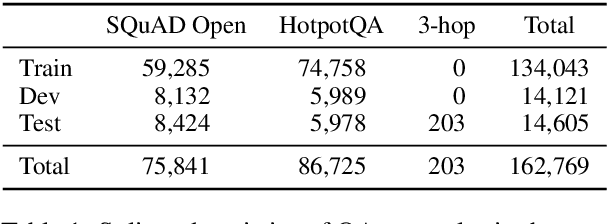
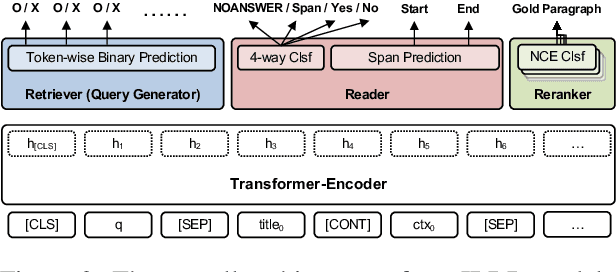
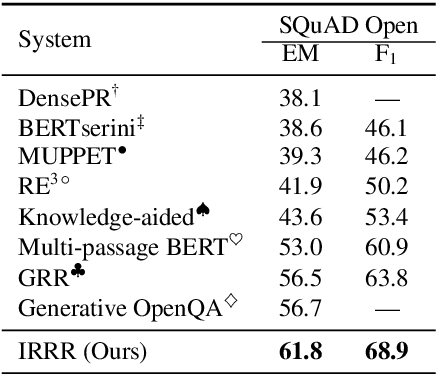
Current approaches to open-domain question answering often make crucial assumptions that prevent them from generalizing to real-world settings, including the access to parameterized retrieval systems well-tuned for the task, access to structured metadata like knowledge bases and web links, or a priori knowledge of the complexity of questions to be answered (e.g., single-hop or multi-hop). To address these limitations, we propose a unified system to answer open-domain questions of arbitrary complexity directly from text that works with off-the-shelf retrieval systems on arbitrary text collections. We employ a single multi-task model to perform all the necessary subtasks---retrieving supporting facts, reranking them, and predicting the answer from all retrieved documents---in an iterative fashion. To emulate a more realistic setting, we also constructed a new unified benchmark by collecting about 200 multi-hop questions that require three Wikipedia pages to answer, and combining them with existing datasets. We show that our model not only outperforms state-of-the-art systems on several existing benchmarks that exclusively feature single-hop or multi-hop open-domain questions, but also achieves strong performance on the new benchmark.
RNNs can generate bounded hierarchical languages with optimal memory
Oct 15, 2020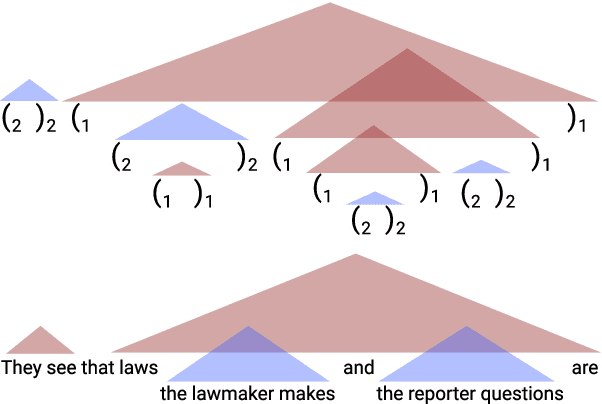
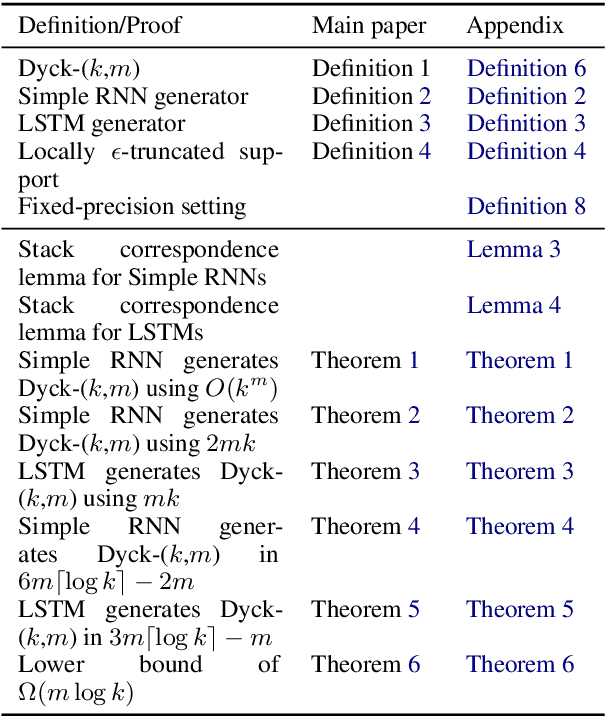
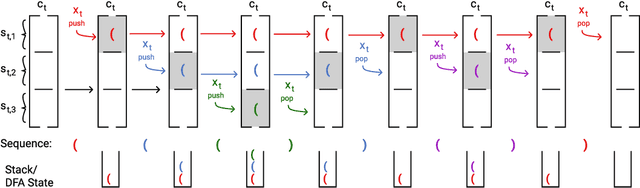
Recurrent neural networks empirically generate natural language with high syntactic fidelity. However, their success is not well-understood theoretically. We provide theoretical insight into this success, proving in a finite-precision setting that RNNs can efficiently generate bounded hierarchical languages that reflect the scaffolding of natural language syntax. We introduce Dyck-($k$,$m$), the language of well-nested brackets (of $k$ types) and $m$-bounded nesting depth, reflecting the bounded memory needs and long-distance dependencies of natural language syntax. The best known results use $O(k^{\frac{m}{2}})$ memory (hidden units) to generate these languages. We prove that an RNN with $O(m \log k)$ hidden units suffices, an exponential reduction in memory, by an explicit construction. Finally, we show that no algorithm, even with unbounded computation, can suffice with $o(m \log k)$ hidden units.
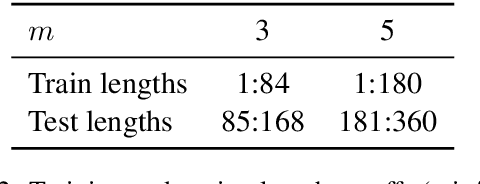
The EOS Decision and Length Extrapolation
Oct 14, 2020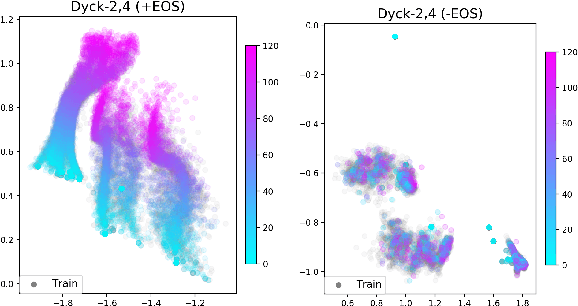

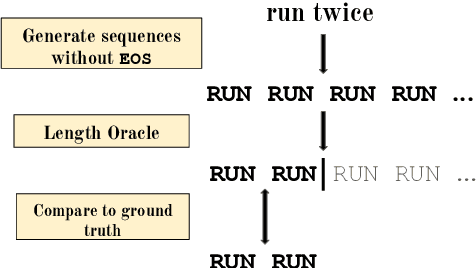

Extrapolation to unseen sequence lengths is a challenge for neural generative models of language. In this work, we characterize the effect on length extrapolation of a modeling decision often overlooked: predicting the end of the generative process through the use of a special end-of-sequence (EOS) vocabulary item. We study an oracle setting - forcing models to generate to the correct sequence length at test time - to compare the length-extrapolative behavior of networks trained to predict EOS (+EOS) with networks not trained to (-EOS). We find that -EOS substantially outperforms +EOS, for example extrapolating well to lengths 10 times longer than those seen at training time in a bracket closing task, as well as achieving a 40% improvement over +EOS in the difficult SCAN dataset length generalization task. By comparing the hidden states and dynamics of -EOS and +EOS models, we observe that +EOS models fail to generalize because they (1) unnecessarily stratify their hidden states by their linear position is a sequence (structures we call length manifolds) or (2) get stuck in clusters (which we refer to as length attractors) once the EOS token is the highest-probability prediction.