 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlease Translate Again: Two Simple Experiments on Whether Human-Like Reasoning Helps Translation
Paper and Code
Jun 05, 2025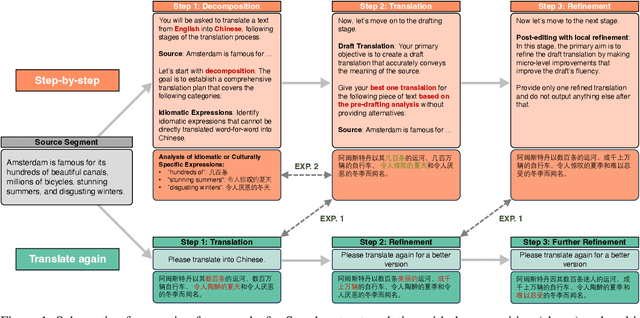
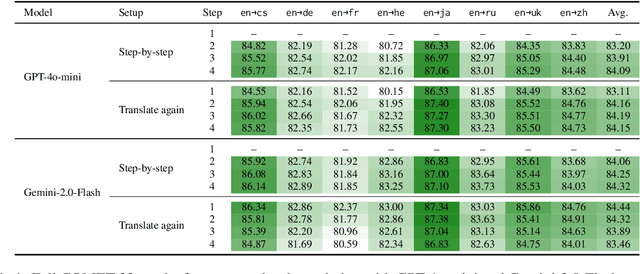
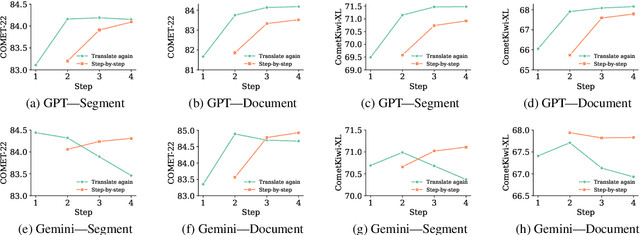
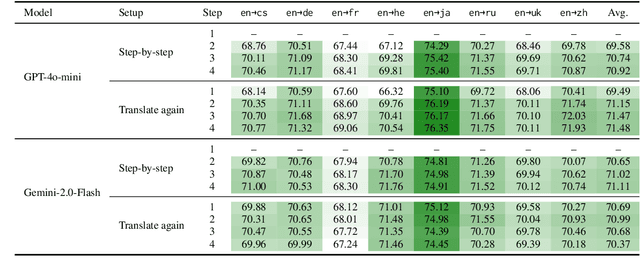
Large Language Models (LLMs) demonstrate strong reasoning capabilities for many tasks, often by explicitly decomposing the task via Chain-of-Thought (CoT) reasoning. Recent work on LLM-based translation designs hand-crafted prompts to decompose translation, or trains models to incorporate intermediate steps.~\textit{Translating Step-by-step}~\citep{briakou2024translating}, for instance, introduces a multi-step prompt with decomposition and refinement of translation with LLMs, which achieved state-of-the-art results on WMT24. In this work, we scrutinise this strategy's effectiveness. Empirically, we find no clear evidence that performance gains stem from explicitly decomposing the translation process, at least for the models on test; and we show that simply prompting LLMs to ``translate again'' yields even better results than human-like step-by-step prompting. Our analysis does not rule out the role of reasoning, but instead invites future work exploring the factors for CoT's effectiveness in the context of translation.