 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Visual Fields with Neural Amplitude Encoding
Aug 14, 2025Quantum Implicit Neural Representations (QINRs) include components for learning and execution on gate-based quantum computers. While QINRs recently emerged as a promising new paradigm, many challenges concerning their architecture and ansatz design, the utility of quantum-mechanical properties, training efficiency and the interplay with classical modules remain. This paper advances the field by introducing a new type of QINR for 2D image and 3D geometric field learning, which we collectively refer to as Quantum Visual Field (QVF). QVF encodes classical data into quantum statevectors using neural amplitude encoding grounded in a learnable energy manifold, ensuring meaningful Hilbert space embeddings. Our ansatz follows a fully entangled design of learnable parametrised quantum circuits, with quantum (unitary) operations performed in the real Hilbert space, resulting in numerically stable training with fast convergence. QVF does not rely on classical post-processing -- in contrast to the previous QINR learning approach -- and directly employs projective measurement to extract learned signals encoded in the ansatz. Experiments on a quantum hardware simulator demonstrate that QVF outperforms the existing quantum approach and widely used classical foundational baselines in terms of visual representation accuracy across various metrics and model characteristics, such as learning of high-frequency details. We also show applications of QVF in 2D and 3D field completion and 3D shape interpolation, highlighting its practical potential.
HumanOLAT: A Large-Scale Dataset for Full-Body Human Relighting and Novel-View Synthesis
Aug 12, 2025Simultaneous relighting and novel-view rendering of digital human representations is an important yet challenging task with numerous applications. Progress in this area has been significantly limited due to the lack of publicly available, high-quality datasets, especially for full-body human captures. To address this critical gap, we introduce the HumanOLAT dataset, the first publicly accessible large-scale dataset of multi-view One-Light-at-a-Time (OLAT) captures of full-body humans. The dataset includes HDR RGB frames under various illuminations, such as white light, environment maps, color gradients and fine-grained OLAT illuminations. Our evaluations of state-of-the-art relighting and novel-view synthesis methods underscore both the dataset's value and the significant challenges still present in modeling complex human-centric appearance and lighting interactions. We believe HumanOLAT will significantly facilitate future research, enabling rigorous benchmarking and advancements in both general and human-specific relighting and rendering techniques.
CNS-Bench: Benchmarking Image Classifier Robustness Under Continuous Nuisance Shifts
Jul 23, 2025An important challenge when using computer vision models in the real world is to evaluate their performance in potential out-of-distribution (OOD) scenarios. While simple synthetic corruptions are commonly applied to test OOD robustness, they often fail to capture nuisance shifts that occur in the real world. Recently, diffusion models have been applied to generate realistic images for benchmarking, but they are restricted to binary nuisance shifts. In this work, we introduce CNS-Bench, a Continuous Nuisance Shift Benchmark to quantify OOD robustness of image classifiers for continuous and realistic generative nuisance shifts. CNS-Bench allows generating a wide range of individual nuisance shifts in continuous severities by applying LoRA adapters to diffusion models. To address failure cases, we propose a filtering mechanism that outperforms previous methods, thereby enabling reliable benchmarking with generative models. With the proposed benchmark, we perform a large-scale study to evaluate the robustness of more than 40 classifiers under various nuisance shifts. Through carefully designed comparisons and analyses, we find that model rankings can change for varying shifts and shift scales, which cannot be captured when applying common binary shifts. Additionally, we show that evaluating the model performance on a continuous scale allows the identification of model failure points, providing a more nuanced understanding of model robustness. Project page including code and data: https://genintel.github.io/CNS.
Physics-based Human Pose Estimation from a Single Moving RGB Camera
Jul 23, 2025Most monocular and physics-based human pose tracking methods, while achieving state-of-the-art results, suffer from artifacts when the scene does not have a strictly flat ground plane or when the camera is moving. Moreover, these methods are often evaluated on in-the-wild real world videos without ground-truth data or on synthetic datasets, which fail to model the real world light transport, camera motion, and pose-induced appearance and geometry changes. To tackle these two problems, we introduce MoviCam, the first non-synthetic dataset containing ground-truth camera trajectories of a dynamically moving monocular RGB camera, scene geometry, and 3D human motion with human-scene contact labels. Additionally, we propose PhysDynPose, a physics-based method that incorporates scene geometry and physical constraints for more accurate human motion tracking in case of camera motion and non-flat scenes. More precisely, we use a state-of-the-art kinematics estimator to obtain the human pose and a robust SLAM method to capture the dynamic camera trajectory, enabling the recovery of the human pose in the world frame. We then refine the kinematic pose estimate using our scene-aware physics optimizer. From our new benchmark, we found that even state-of-the-art methods struggle with this inherently challenging setting, i.e. a moving camera and non-planar environments, while our method robustly estimates both human and camera poses in world coordinates.
Attention (as Discrete-Time Markov) Chains
Jul 23, 2025We introduce a new interpretation of the attention matrix as a discrete-time Markov chain. Our interpretation sheds light on common operations involving attention scores such as selection, summation, and averaging in a unified framework. It further extends them by considering indirect attention, propagated through the Markov chain, as opposed to previous studies that only model immediate effects. Our main observation is that tokens corresponding to semantically similar regions form a set of metastable states, where the attention clusters, while noisy attention scores tend to disperse. Metastable states and their prevalence can be easily computed through simple matrix multiplication and eigenanalysis, respectively. Using these lightweight tools, we demonstrate state-of-the-art zero-shot segmentation. Lastly, we define TokenRank -- the steady state vector of the Markov chain, which measures global token importance. We demonstrate that using it brings improvements in unconditional image generation. We believe our framework offers a fresh view of how tokens are being attended in modern visual transformers.
Restereo: Diffusion stereo video generation and restoration
Jun 06, 2025Stereo video generation has been gaining increasing attention with recent advancements in video diffusion models. However, most existing methods focus on generating 3D stereoscopic videos from monocular 2D videos. These approaches typically assume that the input monocular video is of high quality, making the task primarily about inpainting occluded regions in the warped video while preserving disoccluded areas. In this paper, we introduce a new pipeline that not only generates stereo videos but also enhances both left-view and right-view videos consistently with a single model. Our approach achieves this by fine-tuning the model on degraded data for restoration, as well as conditioning the model on warped masks for consistent stereo generation. As a result, our method can be fine-tuned on a relatively small synthetic stereo video datasets and applied to low-quality real-world videos, performing both stereo video generation and restoration. Experiments demonstrate that our method outperforms existing approaches both qualitatively and quantitatively in stereo video generation from low-resolution inputs.
Do It Yourself: Learning Semantic Correspondence from Pseudo-Labels
Jun 05, 2025Finding correspondences between semantically similar points across images and object instances is one of the everlasting challenges in computer vision. While large pre-trained vision models have recently been demonstrated as effective priors for semantic matching, they still suffer from ambiguities for symmetric objects or repeated object parts. We propose to improve semantic correspondence estimation via 3D-aware pseudo-labeling. Specifically, we train an adapter to refine off-the-shelf features using pseudo-labels obtained via 3D-aware chaining, filtering wrong labels through relaxed cyclic consistency, and 3D spherical prototype mapping constraints. While reducing the need for dataset specific annotations compared to prior work, we set a new state-of-the-art on SPair-71k by over 4% absolute gain and by over 7% against methods with similar supervision requirements. The generality of our proposed approach simplifies extension of training to other data sources, which we demonstrate in our experiments.
EVA: Expressive Virtual Avatars from Multi-view Videos
May 21, 2025

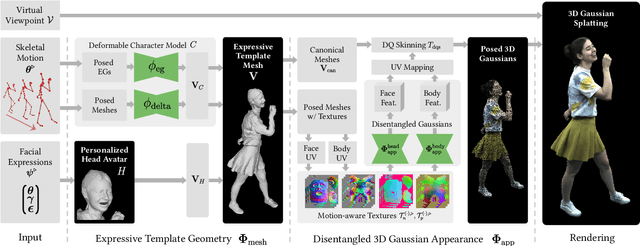

With recent advancements in neural rendering and motion capture algorithms, remarkable progress has been made in photorealistic human avatar modeling, unlocking immense potential for applications in virtual reality, augmented reality, remote communication, and industries such as gaming, film, and medicine. However, existing methods fail to provide complete, faithful, and expressive control over human avatars due to their entangled representation of facial expressions and body movements. In this work, we introduce Expressive Virtual Avatars (EVA), an actor-specific, fully controllable, and expressive human avatar framework that achieves high-fidelity, lifelike renderings in real time while enabling independent control of facial expressions, body movements, and hand gestures. Specifically, our approach designs the human avatar as a two-layer model: an expressive template geometry layer and a 3D Gaussian appearance layer. First, we present an expressive template tracking algorithm that leverages coarse-to-fine optimization to accurately recover body motions, facial expressions, and non-rigid deformation parameters from multi-view videos. Next, we propose a novel decoupled 3D Gaussian appearance model designed to effectively disentangle body and facial appearance. Unlike unified Gaussian estimation approaches, our method employs two specialized and independent modules to model the body and face separately. Experimental results demonstrate that EVA surpasses state-of-the-art methods in terms of rendering quality and expressiveness, validating its effectiveness in creating full-body avatars. This work represents a significant advancement towards fully drivable digital human models, enabling the creation of lifelike digital avatars that faithfully replicate human geometry and appearance.
IntrinsicEdit: Precise generative image manipulation in intrinsic space
May 15, 2025



Generative diffusion models have advanced image editing with high-quality results and intuitive interfaces such as prompts and semantic drawing. However, these interfaces lack precise control, and the associated methods typically specialize on a single editing task. We introduce a versatile, generative workflow that operates in an intrinsic-image latent space, enabling semantic, local manipulation with pixel precision for a range of editing operations. Building atop the RGB-X diffusion framework, we address key challenges of identity preservation and intrinsic-channel entanglement. By incorporating exact diffusion inversion and disentangled channel manipulation, we enable precise, efficient editing with automatic resolution of global illumination effects -- all without additional data collection or model fine-tuning. We demonstrate state-of-the-art performance across a variety of tasks on complex images, including color and texture adjustments, object insertion and removal, global relighting, and their combinations.
Common3D: Self-Supervised Learning of 3D Morphable Models for Common Objects in Neural Feature Space
Apr 30, 20253D morphable models (3DMMs) are a powerful tool to represent the possible shapes and appearances of an object category. Given a single test image, 3DMMs can be used to solve various tasks, such as predicting the 3D shape, pose, semantic correspondence, and instance segmentation of an object. Unfortunately, 3DMMs are only available for very few object categories that are of particular interest, like faces or human bodies, as they require a demanding 3D data acquisition and category-specific training process. In contrast, we introduce a new method, Common3D, that learns 3DMMs of common objects in a fully self-supervised manner from a collection of object-centric videos. For this purpose, our model represents objects as a learned 3D template mesh and a deformation field that is parameterized as an image-conditioned neural network. Different from prior works, Common3D represents the object appearance with neural features instead of RGB colors, which enables the learning of more generalizable representations through an abstraction from pixel intensities. Importantly, we train the appearance features using a contrastive objective by exploiting the correspondences defined through the deformable template mesh. This leads to higher quality correspondence features compared to related works and a significantly improved model performance at estimating 3D object pose and semantic correspondence. Common3D is the first completely self-supervised method that can solve various vision tasks in a zero-shot manner.