 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering Autonomous Shuttles with Next-Generation Infrastructure
Oct 28, 2024



As cities strive to address urban mobility challenges, combining autonomous transportation technologies with intelligent infrastructure presents an opportunity to transform how people move within urban environments. Autonomous shuttles are particularly suited for adaptive and responsive public transport for the first and last mile, connecting with smart infrastructure to enhance urban transit. This paper presents the concept, implementation, and evaluation of a proof-of-concept deployment of an autonomous shuttle integrated with smart infrastructure at a public fair. The infrastructure includes two perception-equipped bus stops and a connected pedestrian intersection, all linked through a central communication and control hub. Our key contributions include the development of a comprehensive system architecture for "smart" bus stops, the integration of multiple urban locations into a cohesive smart transport ecosystem, and the creation of adaptive shuttle behavior for automated driving. Additionally, we publish an open source dataset and a Vehicle-to-X (V2X) driver to support further research. Finally, we offer an outlook on future research directions and potential expansions of the demonstrated technologies and concepts.
From One to the Power of Many: Augmentations for Invariance to Multi-LiDAR Perception from Single-Sensor Datasets
Sep 27, 2024



Recently, LiDAR perception methods for autonomous vehicles, powered by deep neural networks have experienced steep growth in performance on classic benchmarks, such as nuScenes and SemanticKITTI. However, there are still large gaps in performance when deploying models trained on such single-sensor setups to modern multi-sensor vehicles. In this work, we investigate if a lack of invariance may be responsible for these performance gaps, and propose some initial solutions in the form of application-specific data augmentations, which can facilitate better transfer to multi-sensor LiDAR setups. We provide experimental evidence that our proposed augmentations improve generalization across LiDAR sensor setups, and investigate how these augmentations affect the models' invariance properties on simulations of different LiDAR sensor setups.
CoCar NextGen: a Multi-Purpose Platform for Connected Autonomous Driving Research
Apr 26, 2024



Real world testing is of vital importance to the success of automated driving. While many players in the business design purpose build testing vehicles, we designed and build a modular platform that offers high flexibility for any kind of scenario. CoCar NextGen is equipped with next generation hardware that addresses all future use cases. Its extensive, redundant sensor setup allows to develop cross-domain data driven approaches that manage the transfer to other sensor setups. Together with the possibility of being deployed on public roads, this creates a unique research platform that supports the road to automated driving on SAE Level 5.
Can you see me now? Blind spot estimation for autonomous vehicles using scenario-based simulation with random reference sensors
Feb 01, 2024



In this paper, we introduce a method for estimating blind spots for sensor setups of autonomous or automated vehicles and/or robotics applications. In comparison to previous methods that rely on geometric approximations, our presented approach provides more realistic coverage estimates by utilizing accurate and detailed 3D simulation environments. Our method leverages point clouds from LiDAR sensors or camera depth images from high-fidelity simulations of target scenarios to provide accurate and actionable visibility estimates. A Monte Carlo-based reference sensor simulation enables us to accurately estimate blind spot size as a metric of coverage, as well as detection probabilities of objects at arbitrary positions.
Analyzing Deep Learning Representations of Point Clouds for Real-Time In-Vehicle LiDAR Perception
Nov 02, 2022



LiDAR sensors are an integral part of modern autonomous vehicles as they provide an accurate, high-resolution 3D representation of the vehicle's surroundings. However, it is computationally difficult to make use of the ever-increasing amounts of data from multiple high-resolution LiDAR sensors. As frame-rates, point cloud sizes and sensor resolutions increase, real-time processing of these point clouds must still extract semantics from this increasingly precise picture of the vehicle's environment. One deciding factor of the run-time performance and accuracy of deep neural networks operating on these point clouds is the underlying data representation and the way it is computed. In this work, we examine the relationship between the computational representations used in neural networks and their performance characteristics. To this end, we propose a novel computational taxonomy of LiDAR point cloud representations used in modern deep neural networks for 3D point cloud processing. Using this taxonomy, we perform a structured analysis of different families of approaches. Thereby, we uncover common advantages and limitations in terms of computational efficiency, memory requirements, and representational capacity as measured by semantic segmentation performance. Finally, we provide some insights and guidance for future developments in neural point cloud processing methods.
AutoSNAP: Automatically Learning Neural Architectures for Instrument Pose Estimation
Jun 26, 2020

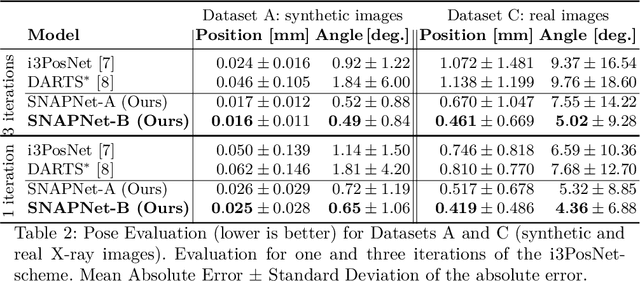
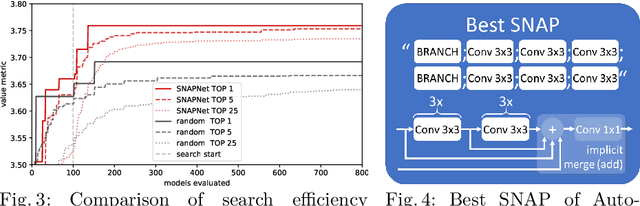
Despite recent successes, the advances in Deep Learning have not yet been fully translated to Computer Assisted Intervention (CAI) problems such as pose estimation of surgical instruments. Currently, neural architectures for classification and segmentation tasks are adopted ignoring significant discrepancies between CAI and these tasks. We propose an automatic framework (AutoSNAP) for instrument pose estimation problems, which discovers and learns the architectures for neural networks. We introduce 1)~an efficient testing environment for pose estimation, 2)~a powerful architecture representation based on novel Symbolic Neural Architecture Patterns (SNAPs), and 3)~an optimization of the architecture using an efficient search scheme. Using AutoSNAP, we discover an improved architecture (SNAPNet) which outperforms both the hand-engineered i3PosNet and the state-of-the-art architecture search method DARTS.