 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Adaptive Text Style Transfer
Aug 25, 2019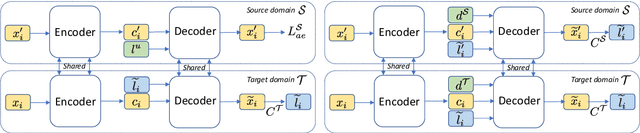
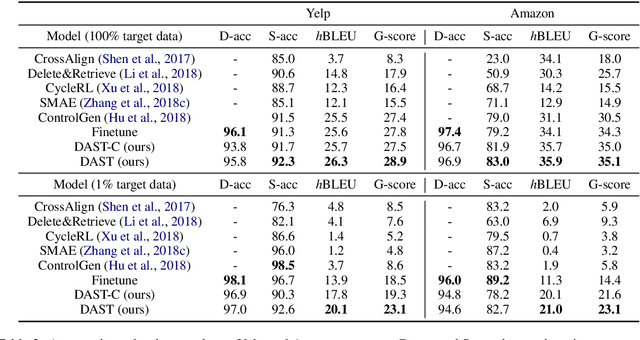
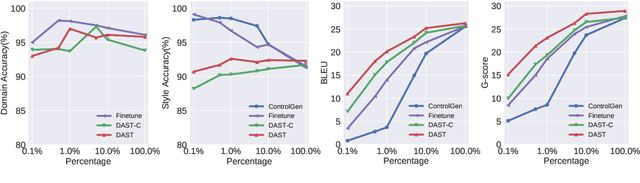
Text style transfer without parallel data has achieved some practical success. However, in the scenario where less data is available, these methods may yield poor performance. In this paper, we examine domain adaptation for text style transfer to leverage massively available data from other domains. These data may demonstrate domain shift, which impedes the benefits of utilizing such data for training. To address this challenge, we propose simple yet effective domain adaptive text style transfer models, enabling domain-adaptive information exchange. The proposed models presumably learn from the source domain to: (i) distinguish stylized information and generic content information; (ii) maximally preserve content information; and (iii) adaptively transfer the styles in a domain-aware manner. We evaluate the proposed models on two style transfer tasks (sentiment and formality) over multiple target domains where only limited non-parallel data is available. Extensive experiments demonstrate the effectiveness of the proposed model compared to the baselines.
Conversing by Reading: Contentful Neural Conversation with On-demand Machine Reading
Jun 07, 2019
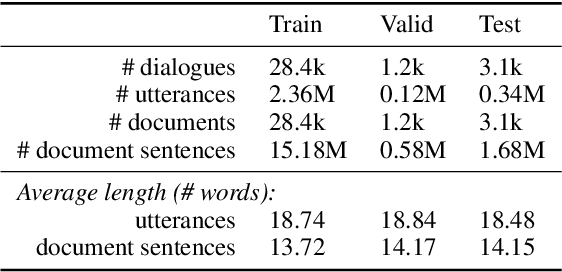
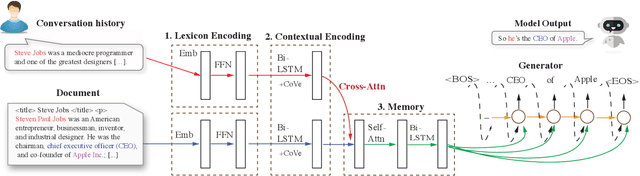
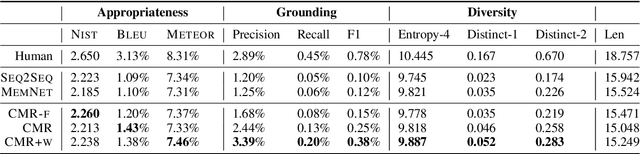
Although neural conversation models are effective in learning how to produce fluent responses, their primary challenge lies in knowing what to say to make the conversation contentful and non-vacuous. We present a new end-to-end approach to contentful neural conversation that jointly models response generation and on-demand machine reading. The key idea is to provide the conversation model with relevant long-form text on the fly as a source of external knowledge. The model performs QA-style reading comprehension on this text in response to each conversational turn, thereby allowing for more focused integration of external knowledge than has been possible in prior approaches. To support further research on knowledge-grounded conversation, we introduce a new large-scale conversation dataset grounded in external web pages (2.8M turns, 7.4M sentences of grounding). Both human evaluation and automated metrics show that our approach results in more contentful responses compared to a variety of previous methods, improving both the informativeness and diversity of generated output.
Vision-based Navigation with Language-based Assistance via Imitation Learning with Indirect Intervention
Apr 06, 2019
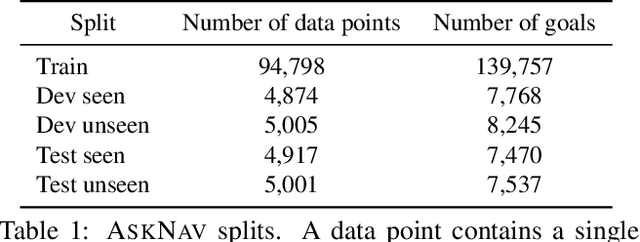
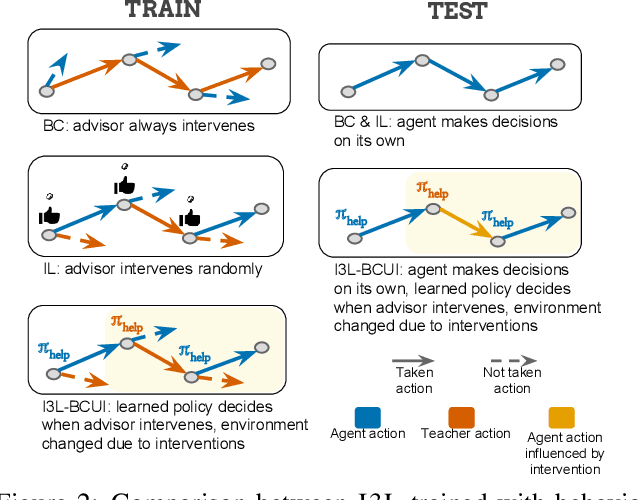
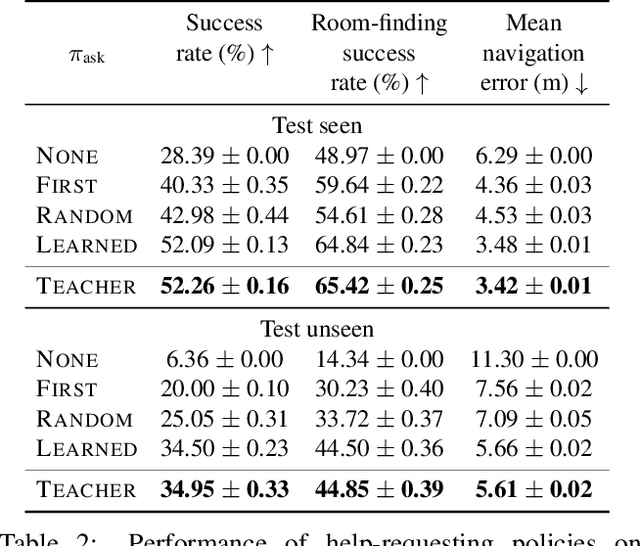
We present Vision-based Navigation with Language-based Assistance (VNLA), a grounded vision-language task where an agent with visual perception is guided via language to find objects in photorealistic indoor environments. The task emulates a real-world scenario in that (a) the requester may not know how to navigate to the target objects and thus makes requests by only specifying high-level end-goals, and (b) the agent is capable of sensing when it is lost and querying an advisor, who is more qualified at the task, to obtain language subgoals to make progress. To model language-based assistance, we develop a general framework termed Imitation Learning with Indirect Intervention (I3L), and propose a solution that is effective on the VNLA task. Empirical results show that this approach significantly improves the success rate of the learning agent over other baselines in both seen and unseen environments. Our code and data are publicly available at https://github.com/debadeepta/vnla .
Jointly Optimizing Diversity and Relevance in Neural Response Generation
Apr 04, 2019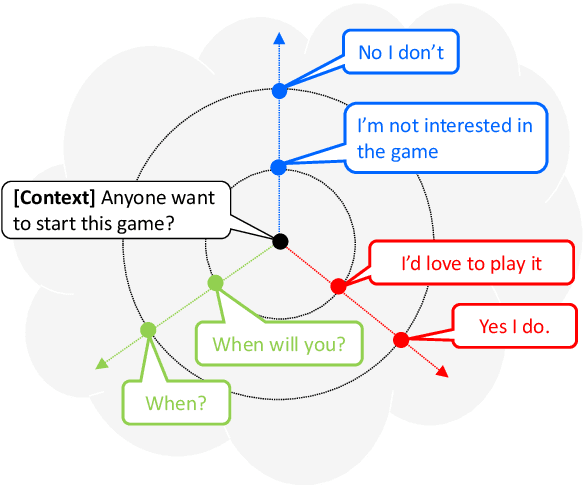
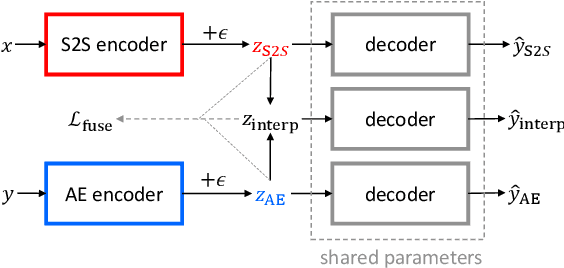

Although recent neural conversation models have shown great potential, they often generate bland and generic responses. While various approaches have been explored to diversify the output of the conversation model, the improvement often comes at the cost of decreased relevance. In this paper, we propose a SpaceFusion model to jointly optimize diversity and relevance that essentially fuses the latent space of a sequence-to-sequence model and that of an autoencoder model by leveraging novel regularization terms. As a result, our approach induces a latent space in which the distance and direction from the predicted response vector roughly match the relevance and diversity, respectively. This property also lends itself well to an intuitive visualization of the latent space. Both automatic and human evaluation results demonstrate that the proposed approach brings significant improvement compared to strong baselines in both diversity and relevance.
Consistent Dialogue Generation with Self-supervised Feature Learning
Mar 27, 2019
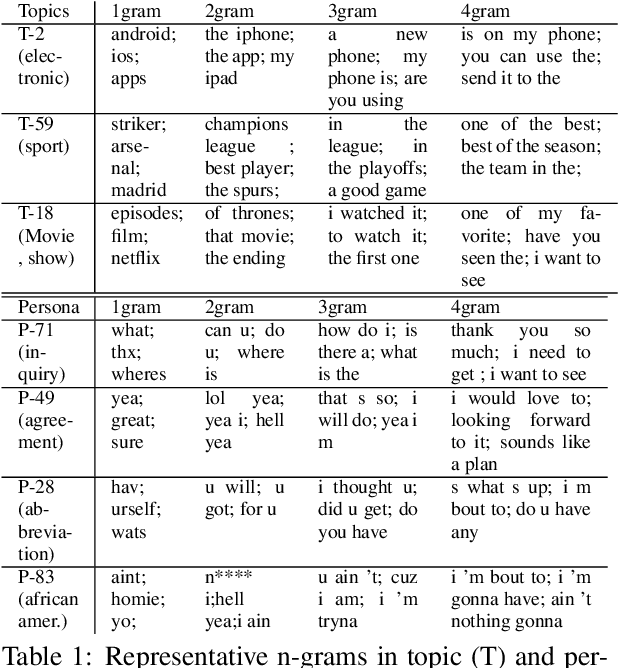
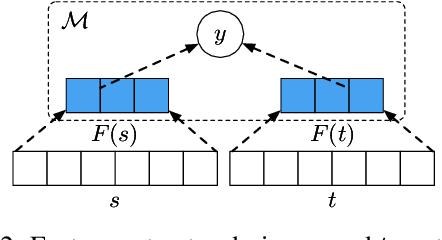
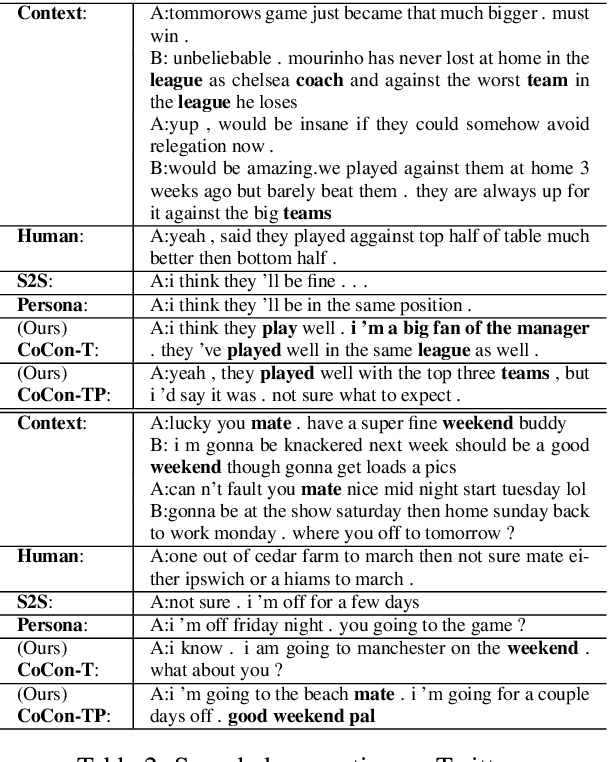
Generating responses that are consistent with the dialogue context is one of the central challenges in building engaging conversational agents. In this paper, we propose a neural conversation model that generates consistent responses by maintaining certain features related to topics and personas throughout the conversation. Unlike past work that requires external supervision such as user identities, which are often unavailable or classified as sensitive information, our approach trains topic and persona feature extractors in a self-supervised way by utilizing the natural structure of dialogue data. Moreover, we adopt a binary feature representation and introduce a feature disentangling loss which, paired with controllable response generation techniques, allows us to promote or demote certain learned topics and personas features. The evaluation result demonstrates the model's capability of capturing meaningful topics and personas features, and the incorporation of the learned features brings significant improvement in terms of the quality of generated responses on two datasets, even comparing with model which explicit persona information.
Dialog System Technology Challenge 7
Jan 11, 2019

This paper introduces the Seventh Dialog System Technology Challenges (DSTC), which use shared datasets to explore the problem of building dialog systems. Recently, end-to-end dialog modeling approaches have been applied to various dialog tasks. The seventh DSTC (DSTC7) focuses on developing technologies related to end-to-end dialog systems for (1) sentence selection, (2) sentence generation and (3) audio visual scene aware dialog. This paper summarizes the overall setup and results of DSTC7, including detailed descriptions of the different tracks and provided datasets. We also describe overall trends in the submitted systems and the key results. Each track introduced new datasets and participants achieved impressive results using state-of-the-art end-to-end technologies.
Generating Informative and Diverse Conversational Responses via Adversarial Information Maximization
Nov 03, 2018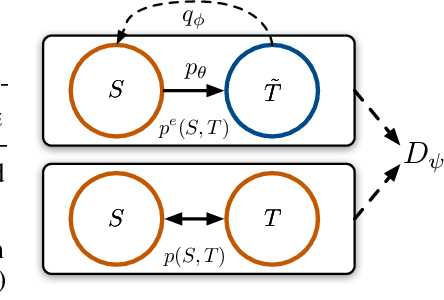
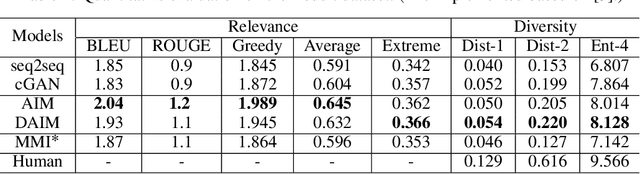

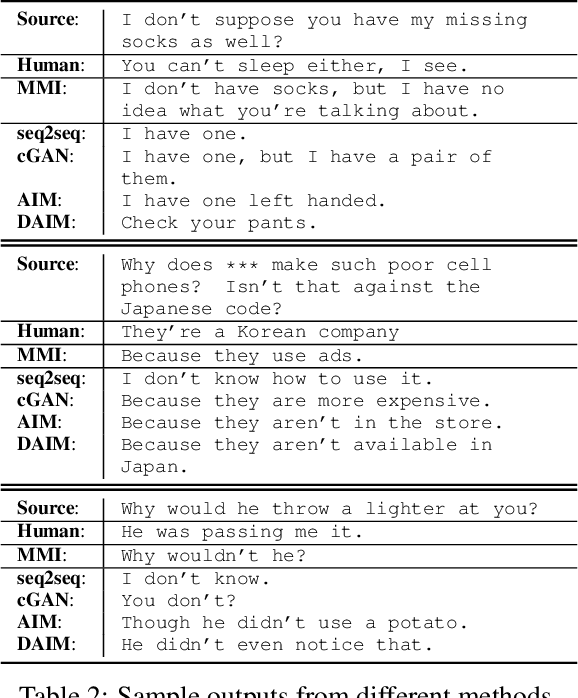
Responses generated by neural conversational models tend to lack informativeness and diversity. We present Adversarial Information Maximization (AIM), an adversarial learning strategy that addresses these two related but distinct problems. To foster response diversity, we leverage adversarial training that allows distributional matching of synthetic and real responses. To improve informativeness, our framework explicitly optimizes a variational lower bound on pairwise mutual information between query and response. Empirical results from automatic and human evaluations demonstrate that our methods significantly boost informativeness and diversity.
Multi-Task Learning for Speaker-Role Adaptation in Neural Conversation Models
Oct 20, 2017
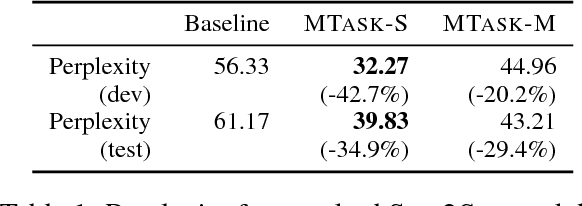
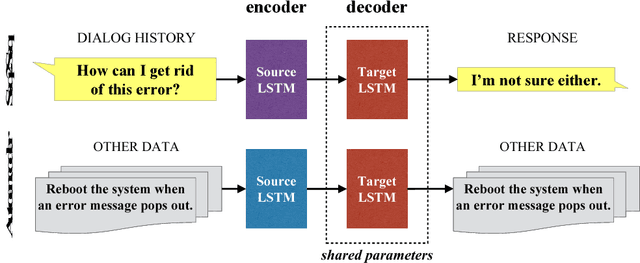
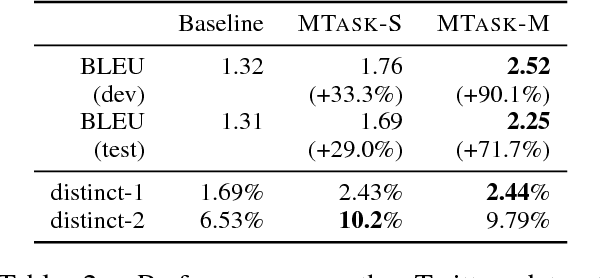
Building a persona-based conversation agent is challenging owing to the lack of large amounts of speaker-specific conversation data for model training. This paper addresses the problem by proposing a multi-task learning approach to training neural conversation models that leverages both conversation data across speakers and other types of data pertaining to the speaker and speaker roles to be modeled. Experiments show that our approach leads to significant improvements over baseline model quality, generating responses that capture more precisely speakers' traits and speaking styles. The model offers the benefits of being algorithmically simple and easy to implement, and not relying on large quantities of data representing specific individual speakers.
Steering Output Style and Topic in Neural Response Generation
Sep 09, 2017
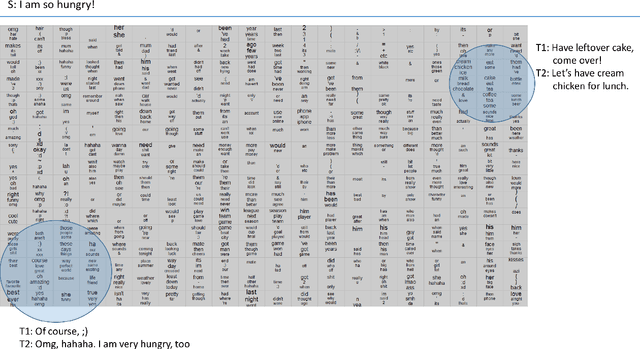
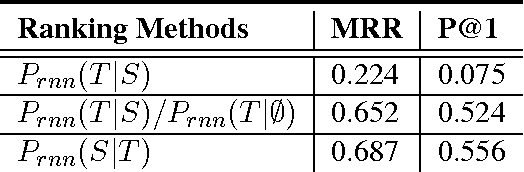
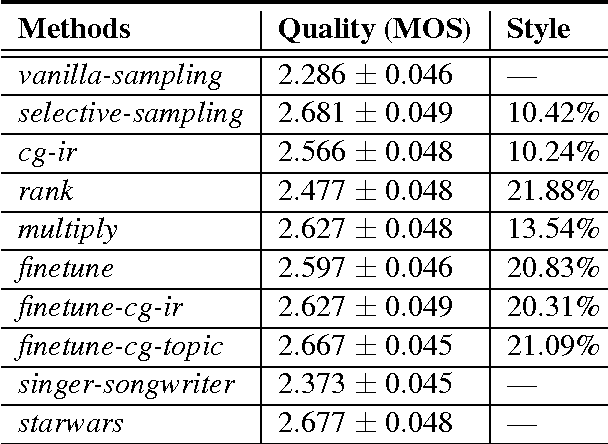
We propose simple and flexible training and decoding methods for influencing output style and topic in neural encoder-decoder based language generation. This capability is desirable in a variety of applications, including conversational systems, where successful agents need to produce language in a specific style and generate responses steered by a human puppeteer or external knowledge. We decompose the neural generation process into empirically easier sub-problems: a faithfulness model and a decoding method based on selective-sampling. We also describe training and sampling algorithms that bias the generation process with a specific language style restriction, or a topic restriction. Human evaluation results show that our proposed methods are able to restrict style and topic without degrading output quality in conversational tasks.
Image-Grounded Conversations: Multimodal Context for Natural Question and Response Generation
Apr 20, 2017



The popularity of image sharing on social media and the engagement it creates between users reflects the important role that visual context plays in everyday conversations. We present a novel task, Image-Grounded Conversations (IGC), in which natural-sounding conversations are generated about a shared image. To benchmark progress, we introduce a new multiple-reference dataset of crowd-sourced, event-centric conversations on images. IGC falls on the continuum between chit-chat and goal-directed conversation models, where visual grounding constrains the topic of conversation to event-driven utterances. Experiments with models trained on social media data show that the combination of visual and textual context enhances the quality of generated conversational turns. In human evaluation, the gap between human performance and that of both neural and retrieval architectures suggests that multi-modal IGC presents an interesting challenge for dialogue research.