 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixBoost: Improving the Robustness of Deep Neural Networks by Boosting Data Augmentation
Dec 08, 2022



As more and more artificial intelligence (AI) technologies move from the laboratory to real-world applications, the open-set and robustness challenges brought by data from the real world have received increasing attention. Data augmentation is a widely used method to improve model performance, and some recent works have also confirmed its positive effect on the robustness of AI models. However, most of the existing data augmentation methods are heuristic, lacking the exploration of their internal mechanisms. We apply the explainable artificial intelligence (XAI) method, explore the internal mechanisms of popular data augmentation methods, analyze the relationship between game interactions and some widely used robustness metrics, and propose a new proxy for model robustness in the open-set environment. Based on the analysis of the internal mechanisms, we develop a mask-based boosting method for data augmentation that comprehensively improves several robustness measures of AI models and beats state-of-the-art data augmentation approaches. Experiments show that our method can be widely applied to many popular data augmentation methods. Different from the adversarial training, our boosting method not only significantly improves the robustness of models, but also improves the accuracy of test sets. Our code is available at \url{https://github.com/Anonymous_for_submission}.
Spatial-Temporal Graph Convolutional Gated Recurrent Network for Traffic Forecasting
Oct 06, 2022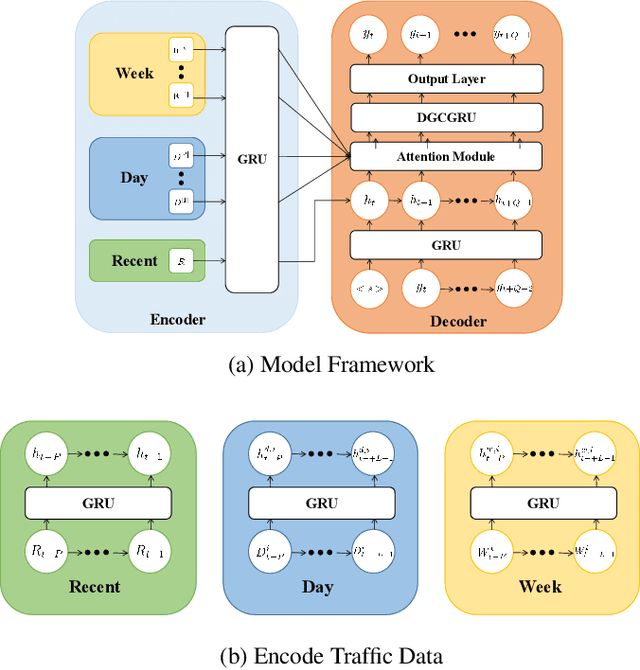
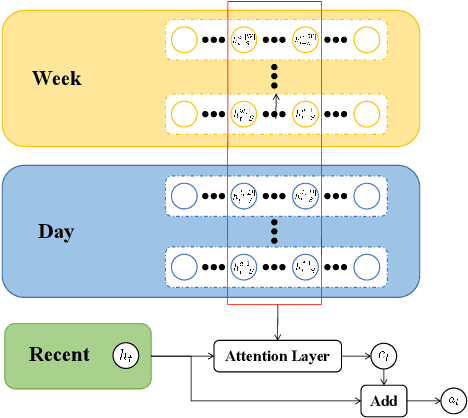
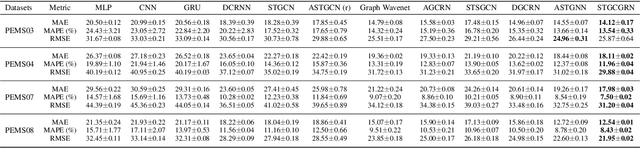
As an important part of intelligent transportation systems, traffic forecasting has attracted tremendous attention from academia and industry. Despite a lot of methods being proposed for traffic forecasting, it is still difficult to model complex spatial-temporal dependency. Temporal dependency includes short-term dependency and long-term dependency, and the latter is often overlooked. Spatial dependency can be divided into two parts: distance-based spatial dependency and hidden spatial dependency. To model complex spatial-temporal dependency, we propose a novel framework for traffic forecasting, named Spatial-Temporal Graph Convolutional Gated Recurrent Network (STGCGRN). We design an attention module to capture long-term dependency by mining periodic information in traffic data. We propose a Double Graph Convolution Gated Recurrent Unit (DGCGRU) to capture spatial dependency, which integrates graph convolutional network and GRU. The graph convolution part models distance-based spatial dependency with the distance-based predefined adjacency matrix and hidden spatial dependency with the self-adaptive adjacency matrix, respectively. Specially, we employ the multi-head mechanism to capture multiple hidden dependencies. In addition, the periodic pattern of each prediction node may be different, which is often ignored, resulting in mutual interference of periodic information among nodes when modeling spatial dependency. For this, we explore the architecture of model and improve the performance. Experiments on four datasets demonstrate the superior performance of our model.
Explanation-based Counterfactual Retraining(XCR): A Calibration Method for Black-box Models
Jun 22, 2022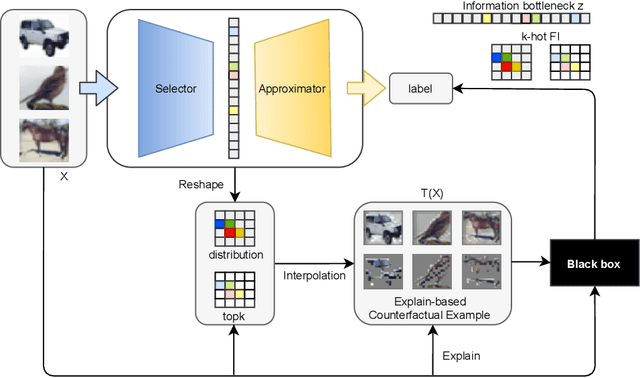


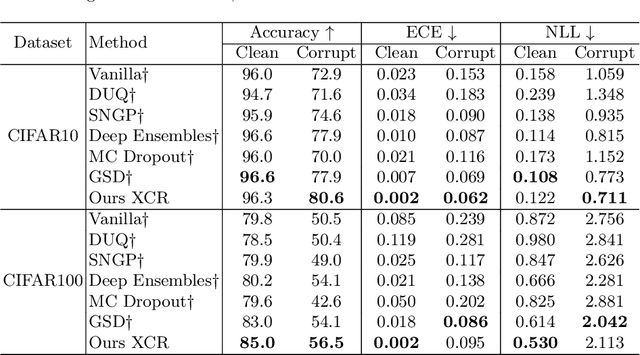
With the rapid development of eXplainable Artificial Intelligence (XAI), a long line of past work has shown concerns about the Out-of-Distribution (OOD) problem in perturbation-based post-hoc XAI models and explanations are socially misaligned. We explore the limitations of post-hoc explanation methods that use approximators to mimic the behavior of black-box models. Then we propose eXplanation-based Counterfactual Retraining (XCR), which extracts feature importance fastly. XCR applies the explanations generated by the XAI model as counterfactual input to retrain the black-box model to address OOD and social misalignment problems. Evaluation of popular image datasets shows that XCR can improve model performance when only retaining 12.5% of the most crucial features without changing the black-box model structure. Furthermore, the evaluation of the benchmark of corruption datasets shows that the XCR is very helpful for improving model robustness and positively impacts the calibration of OOD problems. Even though not calibrated in the validation set like some OOD calibration methods, the corrupted data metric outperforms existing methods. Our method also beats current OOD calibration methods on the OOD calibration metric if calibration on the validation set is applied.
READ: Aggregating Reconstruction Error into Out-of-distribution Detection
Jun 15, 2022
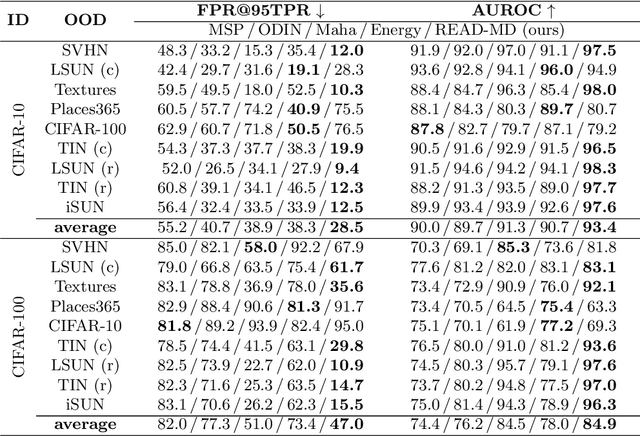
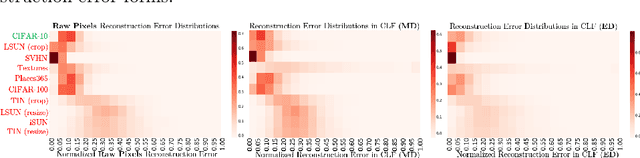
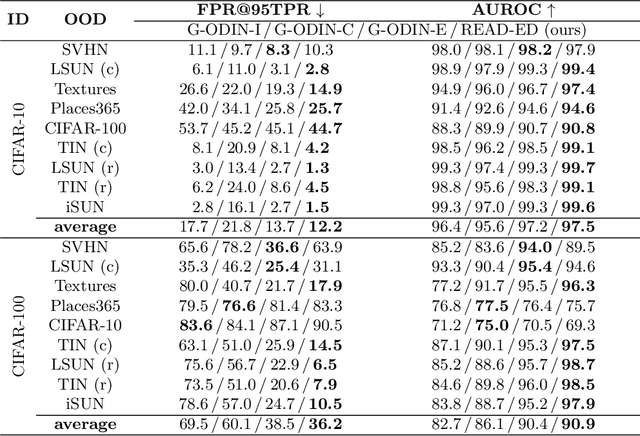
Detecting out-of-distribution (OOD) samples is crucial to the safe deployment of a classifier in the real world. However, deep neural networks are known to be overconfident for abnormal data. Existing works directly design score function by mining the inconsistency from classifier for in-distribution (ID) and OOD. In this paper, we further complement this inconsistency with reconstruction error, based on the assumption that an autoencoder trained on ID data can not reconstruct OOD as well as ID. We propose a novel method, READ (Reconstruction Error Aggregated Detector), to unify inconsistencies from classifier and autoencoder. Specifically, the reconstruction error of raw pixels is transformed to latent space of classifier. We show that the transformed reconstruction error bridges the semantic gap and inherits detection performance from the original. Moreover, we propose an adjustment strategy to alleviate the overconfidence problem of autoencoder according to a fine-grained characterization of OOD data. Under two scenarios of pre-training and retraining, we respectively present two variants of our method, namely READ-MD (Mahalanobis Distance) only based on pre-trained classifier and READ-ED (Euclidean Distance) which retrains the classifier. Our methods do not require access to test time OOD data for fine-tuning hyperparameters. Finally, we demonstrate the effectiveness of the proposed methods through extensive comparisons with state-of-the-art OOD detection algorithms. On a CIFAR-10 pre-trained WideResNet, our method reduces the average FPR@95TPR by up to 9.8% compared with previous state-of-the-art.
Completing Partial Point Clouds with Outliers by Collaborative Completion and Segmentation
Mar 18, 2022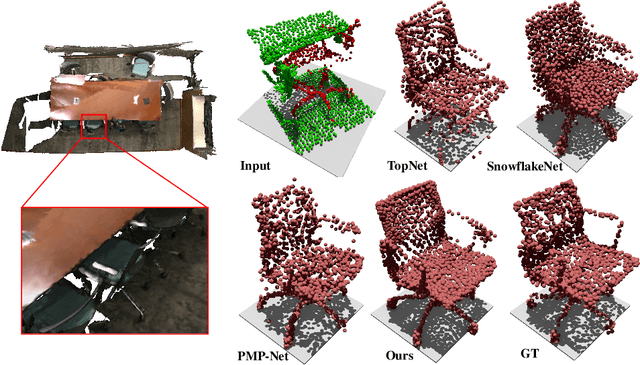
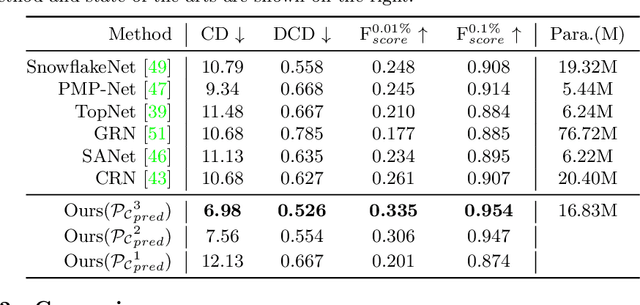
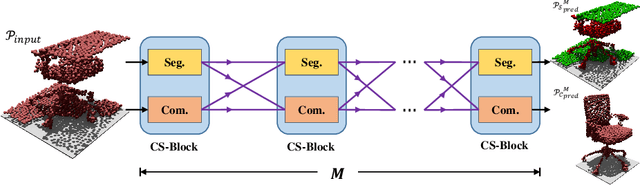
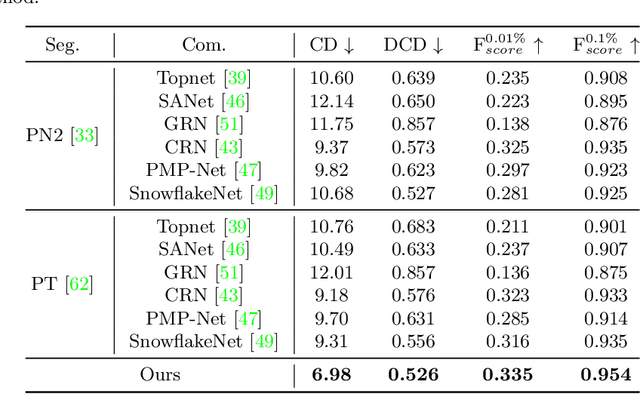
Most existing point cloud completion methods are only applicable to partial point clouds without any noises and outliers, which does not always hold in practice. We propose in this paper an end-to-end network, named CS-Net, to complete the point clouds contaminated by noises or containing outliers. In our CS-Net, the completion and segmentation modules work collaboratively to promote each other, benefited from our specifically designed cascaded structure. With the help of segmentation, more clean point cloud is fed into the completion module. We design a novel completion decoder which harnesses the labels obtained by segmentation together with FPS to purify the point cloud and leverages KNN-grouping for better generation. The completion and segmentation modules work alternately share the useful information from each other to gradually improve the quality of prediction. To train our network, we build a dataset to simulate the real case where incomplete point clouds contain outliers. Our comprehensive experiments and comparisons against state-of-the-art completion methods demonstrate our superiority. We also compare with the scheme of segmentation followed by completion and their end-to-end fusion, which also proves our efficacy.
Tailor Versatile Multi-modal Learning for Multi-label Emotion Recognition
Jan 15, 2022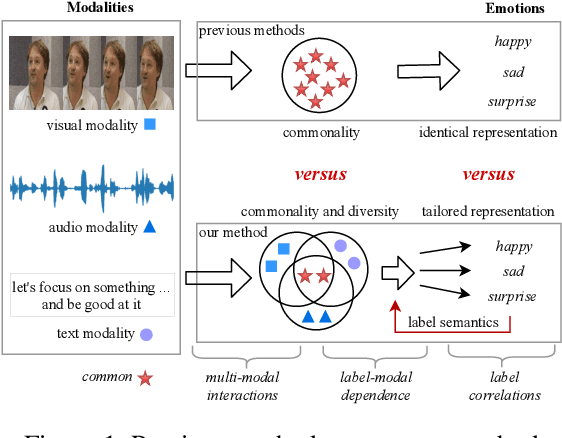

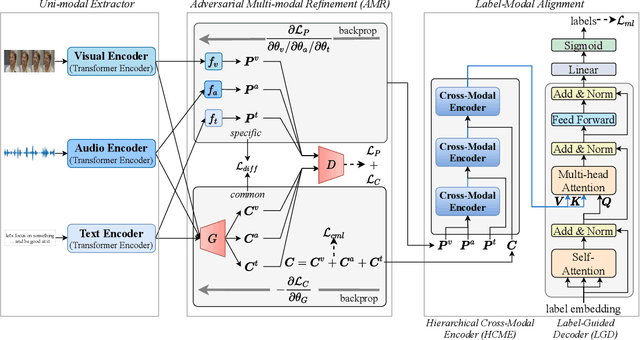
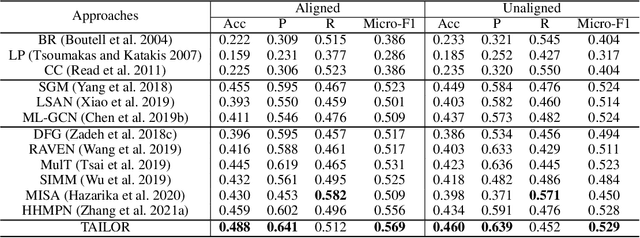
Multi-modal Multi-label Emotion Recognition (MMER) aims to identify various human emotions from heterogeneous visual, audio and text modalities. Previous methods mainly focus on projecting multiple modalities into a common latent space and learning an identical representation for all labels, which neglects the diversity of each modality and fails to capture richer semantic information for each label from different perspectives. Besides, associated relationships of modalities and labels have not been fully exploited. In this paper, we propose versaTile multi-modAl learning for multI-labeL emOtion Recognition (TAILOR), aiming to refine multi-modal representations and enhance discriminative capacity of each label. Specifically, we design an adversarial multi-modal refinement module to sufficiently explore the commonality among different modalities and strengthen the diversity of each modality. To further exploit label-modal dependence, we devise a BERT-like cross-modal encoder to gradually fuse private and common modality representations in a granularity descent way, as well as a label-guided decoder to adaptively generate a tailored representation for each label with the guidance of label semantics. In addition, we conduct experiments on the benchmark MMER dataset CMU-MOSEI in both aligned and unaligned settings, which demonstrate the superiority of TAILOR over the state-of-the-arts. Code is available at https://github.com/kniter1/TAILOR.
Two Wrongs Don't Make a Right: Combating Confirmation Bias in Learning with Label Noise
Dec 06, 2021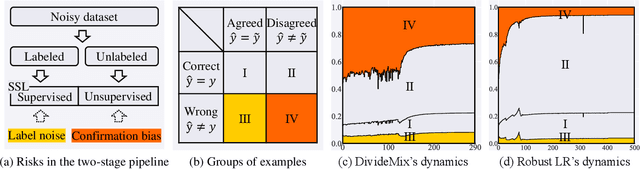
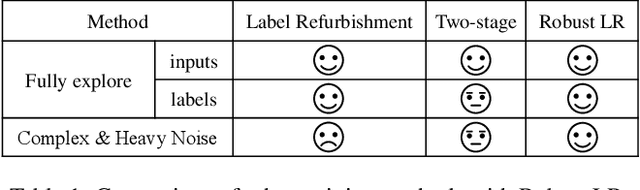
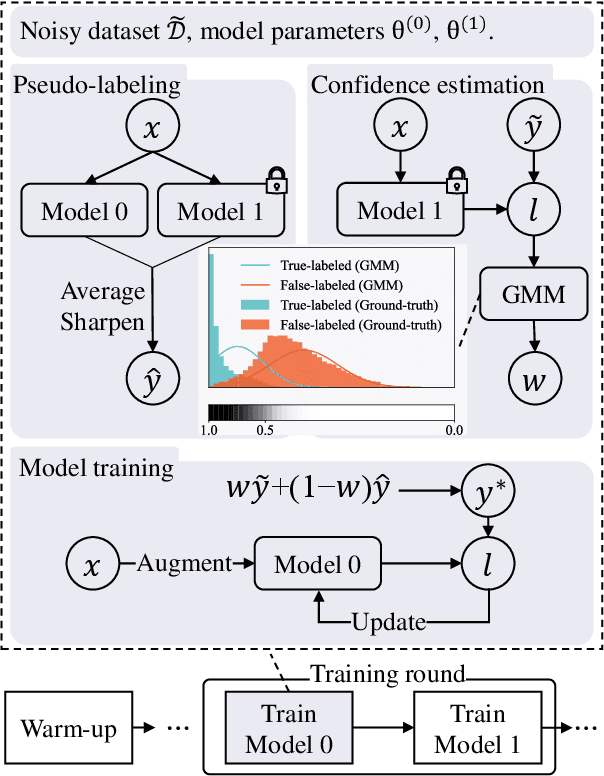
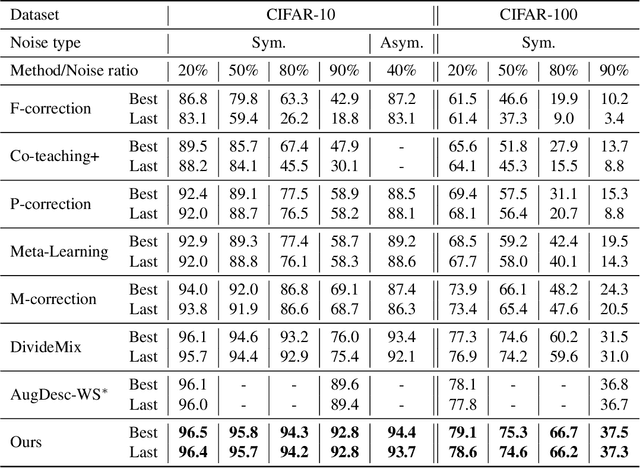
Noisy labels damage the performance of deep networks. For robust learning, a prominent two-stage pipeline alternates between eliminating possible incorrect labels and semi-supervised training. However, discarding part of observed labels could result in a loss of information, especially when the corruption is not completely random, e.g., class-dependent or instance-dependent. Moreover, from the training dynamics of a representative two-stage method DivideMix, we identify the domination of confirmation bias: Pseudo-labels fail to correct a considerable amount of noisy labels and consequently, the errors accumulate. To sufficiently exploit information from observed labels and mitigate wrong corrections, we propose Robust Label Refurbishment (Robust LR)-a new hybrid method that integrates pseudo-labeling and confidence estimation techniques to refurbish noisy labels. We show that our method successfully alleviates the damage of both label noise and confirmation bias. As a result, it achieves state-of-the-art results across datasets and noise types. For example, Robust LR achieves up to 4.5% absolute top-1 accuracy improvement over the previous best on the real-world noisy dataset WebVision.
Generation, augmentation, and alignment: A pseudo-source domain based method for source-free domain adaptation
Sep 09, 2021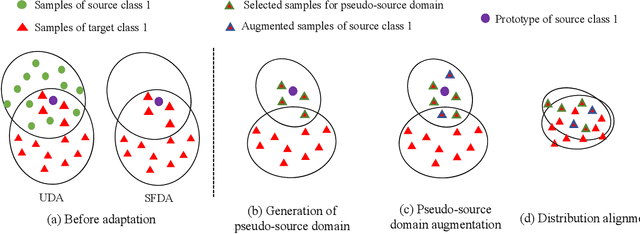
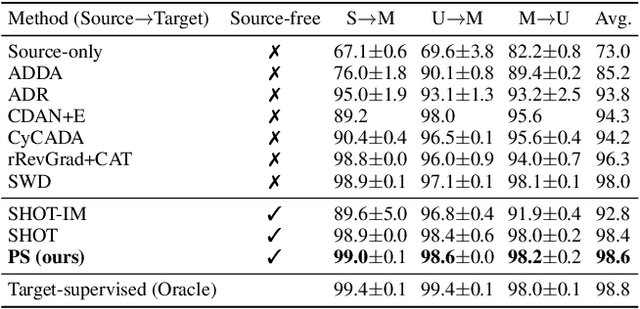
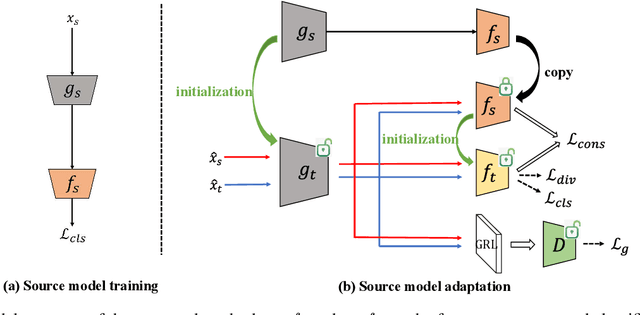
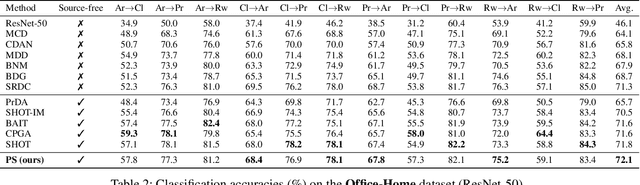
Conventional unsupervised domain adaptation (UDA) methods need to access both labeled source samples and unlabeled target samples simultaneously to train the model. While in some scenarios, the source samples are not available for the target domain due to data privacy and safety. To overcome this challenge, recently, source-free domain adaptation (SFDA) has attracted the attention of researchers, where both a trained source model and unlabeled target samples are given. Existing SFDA methods either adopt a pseudo-label based strategy or generate more samples. However, these methods do not explicitly reduce the distribution shift across domains, which is the key to a good adaptation. Although there are no source samples available, fortunately, we find that some target samples are very similar to the source domain and can be used to approximate the source domain. This approximated domain is denoted as the pseudo-source domain. In this paper, inspired by this observation, we propose a novel method based on the pseudo-source domain. The proposed method firstly generates and augments the pseudo-source domain, and then employs distribution alignment with four novel losses based on pseudo-label based strategy. Among them, a domain adversarial loss is introduced between the pseudo-source domain the remaining target domain to reduce the distribution shift. The results on three real-world datasets verify the effectiveness of the proposed method.
AdaRNN: Adaptive Learning and Forecasting of Time Series
Aug 11, 2021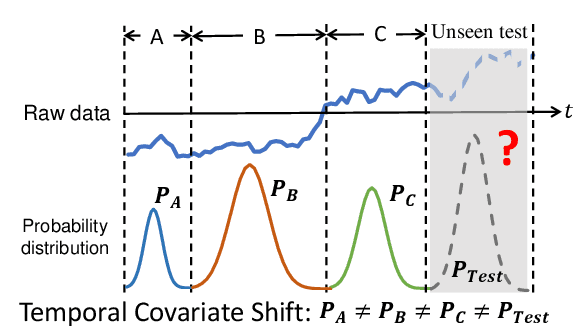
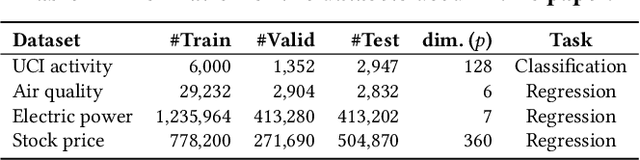
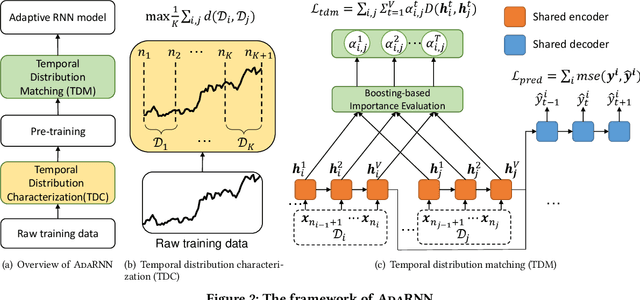
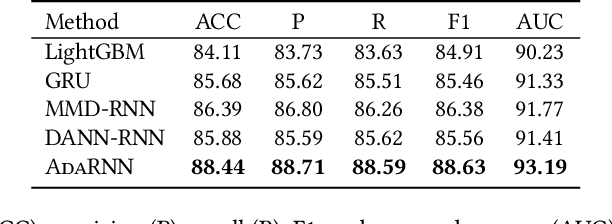
Time series has wide applications in the real world and is known to be difficult to forecast. Since its statistical properties change over time, its distribution also changes temporally, which will cause severe distribution shift problem to existing methods. However, it remains unexplored to model the time series in the distribution perspective. In this paper, we term this as Temporal Covariate Shift (TCS). This paper proposes Adaptive RNNs (AdaRNN) to tackle the TCS problem by building an adaptive model that generalizes well on the unseen test data. AdaRNN is sequentially composed of two novel algorithms. First, we propose Temporal Distribution Characterization to better characterize the distribution information in the TS. Second, we propose Temporal Distribution Matching to reduce the distribution mismatch in TS to learn the adaptive TS model. AdaRNN is a general framework with flexible distribution distances integrated. Experiments on human activity recognition, air quality prediction, and financial analysis show that AdaRNN outperforms the latest methods by a classification accuracy of 2.6% and significantly reduces the RMSE by 9.0%. We also show that the temporal distribution matching algorithm can be extended in Transformer structure to boost its performance.
Semi-Supervised Learning with Multi-Head Co-Training
Jul 10, 2021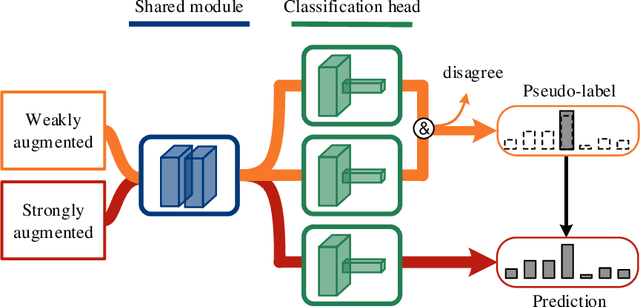


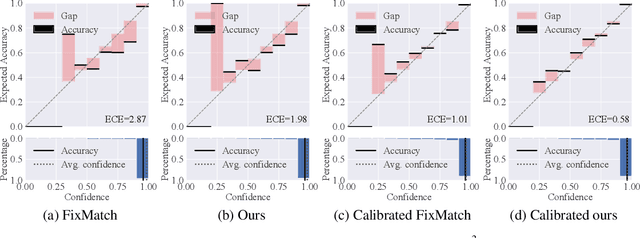
Co-training, extended from self-training, is one of the frameworks for semi-supervised learning. It works at the cost of training extra classifiers, where the algorithm should be delicately designed to prevent individual classifiers from collapsing into each other. In this paper, we present a simple and efficient co-training algorithm, named Multi-Head Co-Training, for semi-supervised image classification. By integrating base learners into a multi-head structure, the model is in a minimal amount of extra parameters. Every classification head in the unified model interacts with its peers through a "Weak and Strong Augmentation" strategy, achieving single-view co-training without promoting diversity explicitly. The effectiveness of Multi-Head Co-Training is demonstrated in an empirical study on standard semi-supervised learning benchmarks.