 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn $\ell_p$-norm Robustness of Ensemble Stumps and Trees
Sep 29, 2020

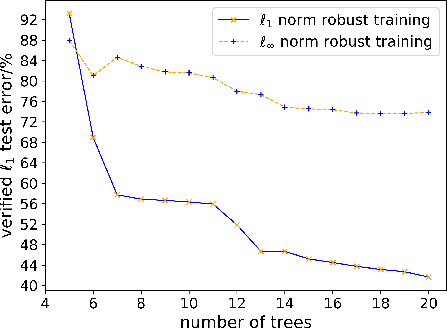
Recent papers have demonstrated that ensemble stumps and trees could be vulnerable to small input perturbations, so robustness verification and defense for those models have become an important research problem. However, due to the structure of decision trees, where each node makes decision purely based on one feature value, all the previous works only consider the $\ell_\infty$ norm perturbation. To study robustness with respect to a general $\ell_p$ norm perturbation, one has to consider the correlation between perturbations on different features, which has not been handled by previous algorithms. In this paper, we study the problem of robustness verification and certified defense with respect to general $\ell_p$ norm perturbations for ensemble decision stumps and trees. For robustness verification of ensemble stumps, we prove that complete verification is NP-complete for $p\in(0, \infty)$ while polynomial time algorithms exist for $p=0$ or $\infty$. For $p\in(0, \infty)$ we develop an efficient dynamic programming based algorithm for sound verification of ensemble stumps. For ensemble trees, we generalize the previous multi-level robustness verification algorithm to $\ell_p$ norm. We demonstrate the first certified defense method for training ensemble stumps and trees with respect to $\ell_p$ norm perturbations, and verify its effectiveness empirically on real datasets.
Improving the Speed and Quality of GAN by Adversarial Training
Aug 07, 2020
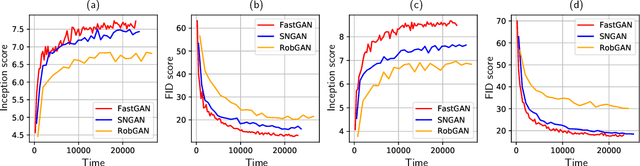
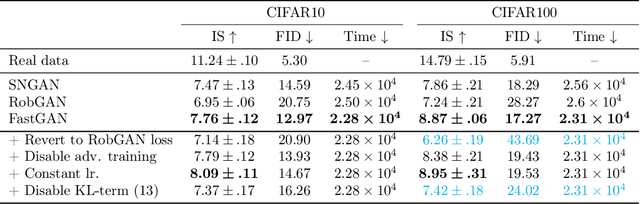

Generative adversarial networks (GAN) have shown remarkable results in image generation tasks. High fidelity class-conditional GAN methods often rely on stabilization techniques by constraining the global Lipschitz continuity. Such regularization leads to less expressive models and slower convergence speed; other techniques, such as the large batch training, require unconventional computing power and are not widely accessible. In this paper, we develop an efficient algorithm, namely FastGAN (Free AdverSarial Training), to improve the speed and quality of GAN training based on the adversarial training technique. We benchmark our method on CIFAR10, a subset of ImageNet, and the full ImageNet datasets. We choose strong baselines such as SNGAN and SAGAN; the results demonstrate that our training algorithm can achieve better generation quality (in terms of the Inception score and Frechet Inception distance) with less overall training time. Most notably, our training algorithm brings ImageNet training to the broader public by requiring 2-4 GPUs.
Multi-Stage Influence Function
Jul 17, 2020
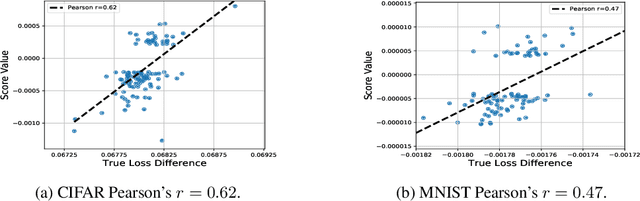

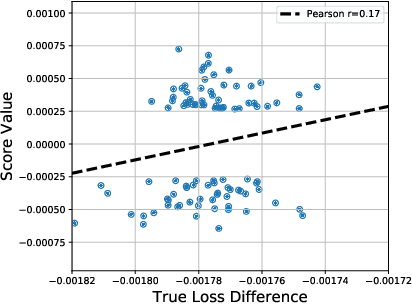
Multi-stage training and knowledge transfer, from a large-scale pretraining task to various finetuning tasks, have revolutionized natural language processing and computer vision resulting in state-of-the-art performance improvements. In this paper, we develop a multi-stage influence function score to track predictions from a finetuned model all the way back to the pretraining data. With this score, we can identify the pretraining examples in the pretraining task that contribute most to a prediction in the finetuning task. The proposed multi-stage influence function generalizes the original influence function for a single model in (Koh & Liang, 2017), thereby enabling influence computation through both pretrained and finetuned models. We study two different scenarios with the pretrained embeddings fixed or updated in the finetuning tasks. We test our proposed method in various experiments to show its effectiveness and potential applications.
Defense against Adversarial Attacks in NLP via Dirichlet Neighborhood Ensemble
Jun 20, 2020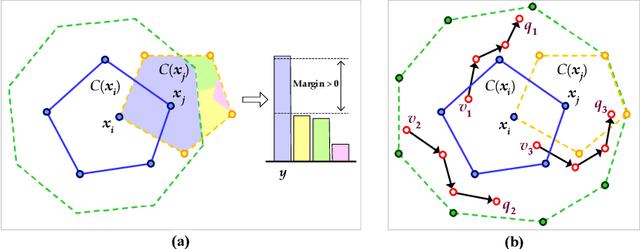
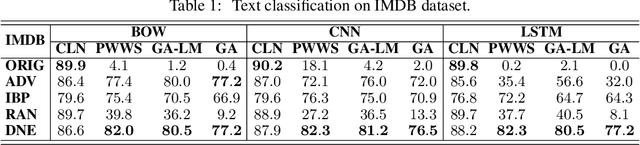
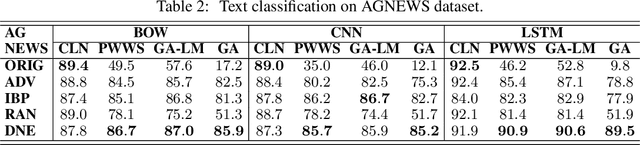
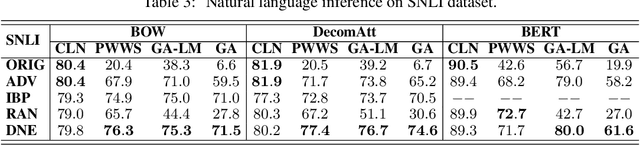
Despite neural networks have achieved prominent performance on many natural language processing (NLP) tasks, they are vulnerable to adversarial examples. In this paper, we propose Dirichlet Neighborhood Ensemble (DNE), a randomized smoothing method for training a robust model to defense substitution-based attacks. During training, DNE forms virtual sentences by sampling embedding vectors for each word in an input sentence from a convex hull spanned by the word and its synonyms, and it augments them with the training data. In such a way, the model is robust to adversarial attacks while maintaining the performance on the original clean data. DNE is agnostic to the network architectures and scales to large models for NLP applications. We demonstrate through extensive experimentation that our method consistently outperforms recently proposed defense methods by a significant margin across different network architectures and multiple data sets.
DrNAS: Dirichlet Neural Architecture Search
Jun 19, 2020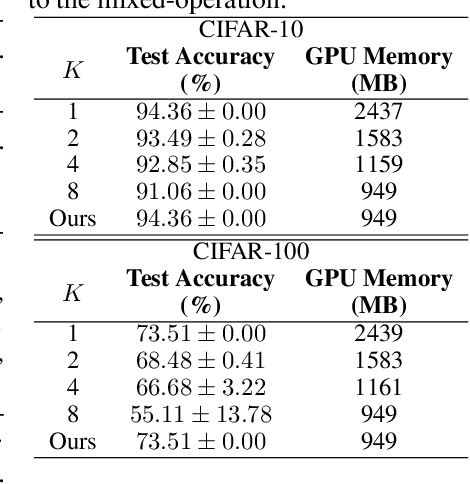

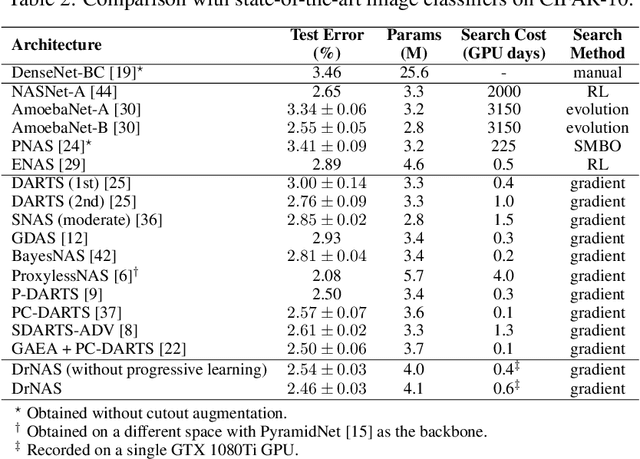
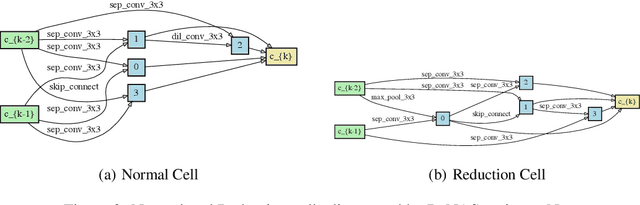
This paper proposes a novel differentiable architecture search method by formulating it into a distribution learning problem. We treat the continuously relaxed architecture mixing weight as random variables, modeled by Dirichlet distribution. With recently developed pathwise derivatives, the Dirichlet parameters can be easily optimized with gradient-based optimizer in an end-to-end manner. This formulation improves the generalization ability and induces stochasticity that naturally encourages exploration in the search space. Furthermore, to alleviate the large memory consumption of differentiable NAS, we propose a simple yet effective progressive learning scheme that enables searching directly on large-scale tasks, eliminating the gap between search and evaluation phases. Extensive experiments demonstrate the effectiveness of our method. Specifically, we obtain a test error of 2.46% for CIFAR-10, 23.7% for ImageNet under the mobile setting. On NAS-Bench-201, we also achieve state-of-the-art results on all three datasets and provide insights for the effective design of neural architecture search algorithms.
The Limit of the Batch Size
Jun 15, 2020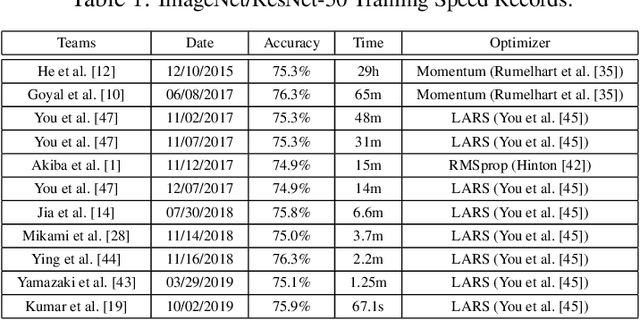
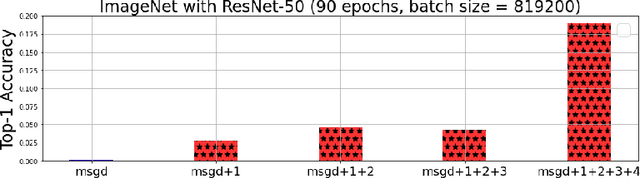

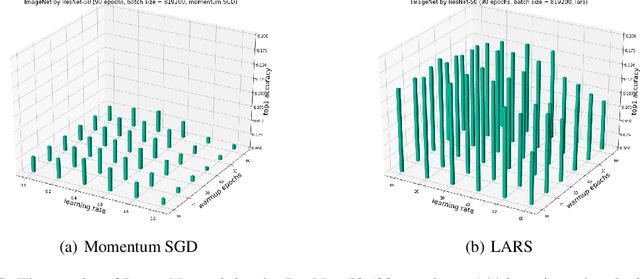
Large-batch training is an efficient approach for current distributed deep learning systems. It has enabled researchers to reduce the ImageNet/ResNet-50 training from 29 hours to around 1 minute. In this paper, we focus on studying the limit of the batch size. We think it may provide a guidance to AI supercomputer and algorithm designers. We provide detailed numerical optimization instructions for step-by-step comparison. Moreover, it is important to understand the generalization and optimization performance of huge batch training. Hoffer et al. introduced "ultra-slow diffusion" theory to large-batch training. However, our experiments show contradictory results with the conclusion of Hoffer et al. We provide comprehensive experimental results and detailed analysis to study the limitations of batch size scaling and "ultra-slow diffusion" theory. For the first time we scale the batch size on ImageNet to at least a magnitude larger than all previous work, and provide detailed studies on the performance of many state-of-the-art optimization schemes under this setting. We propose an optimization recipe that is able to improve the top-1 test accuracy by 18% compared to the baseline.
Provably Robust Metric Learning
Jun 12, 2020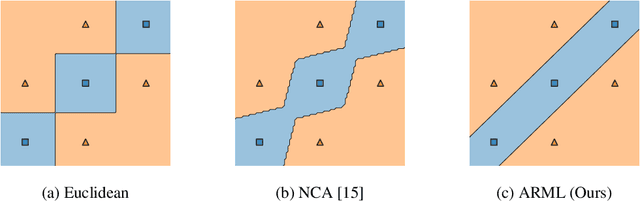
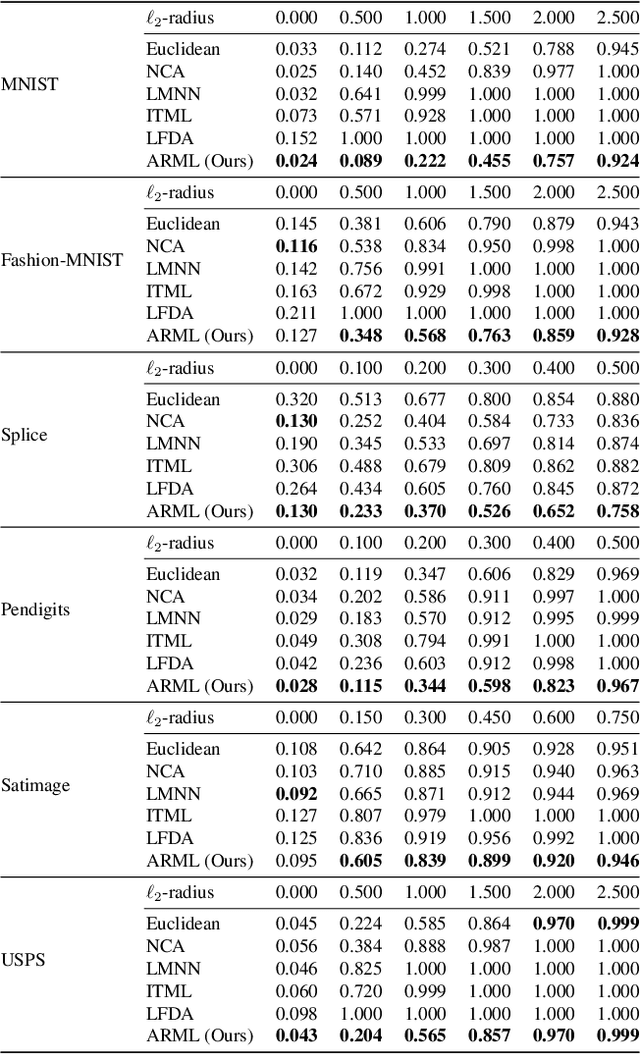
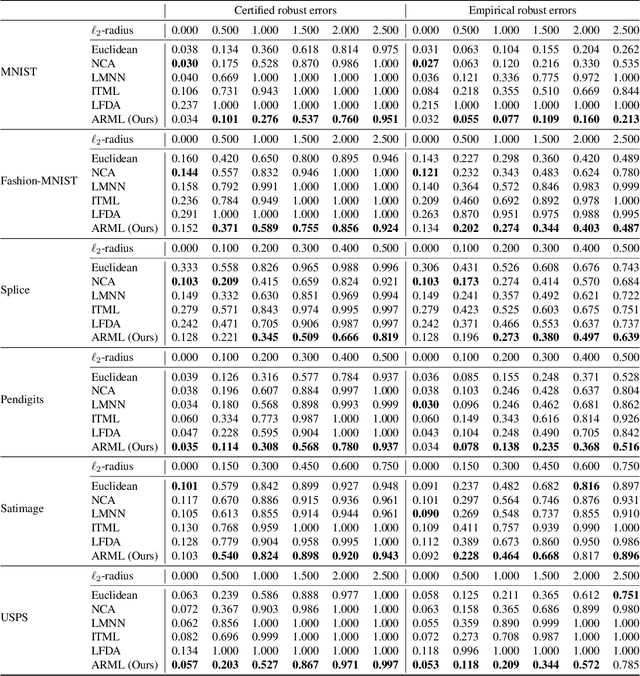
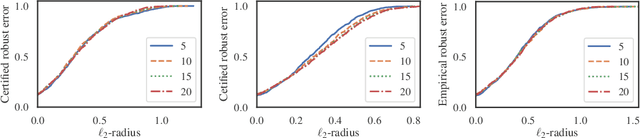
Metric learning is an important family of algorithms for classification and similarity search, but the robustness of learned metrics against small adversarial perturbations is less studied. In this paper, we show that existing metric learning algorithms, which focus on boosting the clean accuracy, can result in metrics that are less robust than the Euclidean distance. To overcome this problem, we propose a novel metric learning algorithm to find a Mahalanobis distance that is robust against adversarial perturbations, and the robustness of the resulting model is certifiable. Experimental results show that the proposed metric learning algorithm improves both certified robust errors and empirical robust errors (errors under adversarial attacks). Furthermore, unlike neural network defenses which usually encounter a trade-off between clean and robust errors, our method does not sacrifice clean errors compared with previous metric learning methods. Our code is available at https://github.com/wangwllu/provably_robust_metric_learning.
An Efficient Algorithm For Generalized Linear Bandit: Online Stochastic Gradient Descent and Thompson Sampling
Jun 07, 2020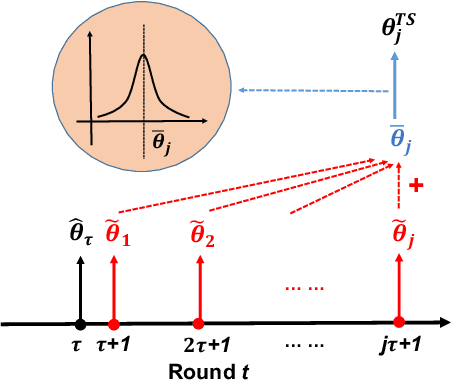

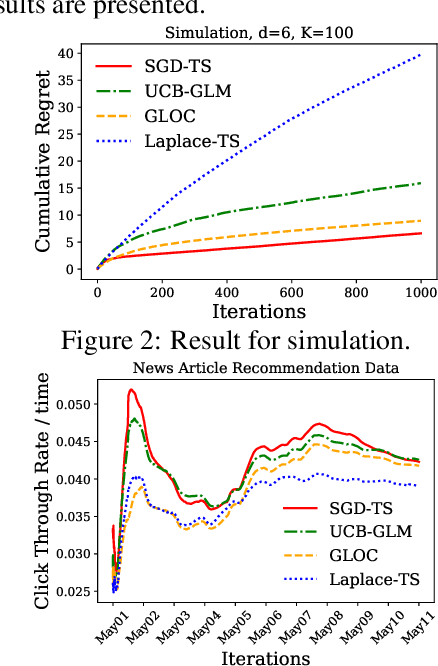
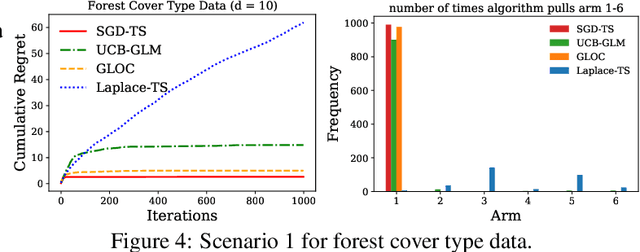
We consider the contextual bandit problem, where a player sequentially makes decisions based on past observations to maximize the cumulative reward. Although many algorithms have been proposed for contextual bandit, most of them rely on finding the maximum likelihood estimator at each iteration, which requires $O(t)$ time at the $t$-th iteration and are memory inefficient. A natural way to resolve this problem is to apply online stochastic gradient descent (SGD) so that the per-step time and memory complexity can be reduced to constant with respect to $t$, but a contextual bandit policy based on online SGD updates that balances exploration and exploitation has remained elusive. In this work, we show that online SGD can be applied to the generalized linear bandit problem. The proposed SGD-TS algorithm, which uses a single-step SGD update to exploit past information and uses Thompson Sampling for exploration, achieves $\tilde{O}(\sqrt{dT})$ regret with the total time complexity that scales linearly in $T$ and $d$, where $T$ is the total number of rounds and $d$ is the number of features. Experimental results show that SGD-TS consistently outperforms existing algorithms on both synthetic and real datasets.
Evaluations and Methods for Explanation through Robustness Analysis
May 31, 2020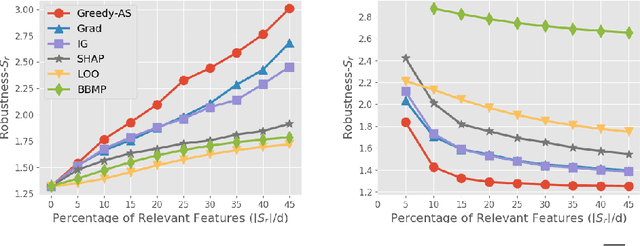


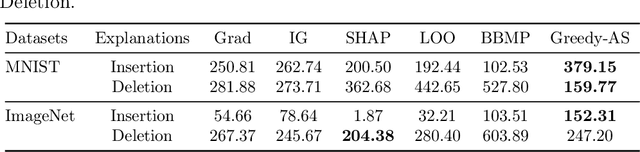
Among multiple ways of interpreting a machine learning model, measuring the importance of a set of features tied to a prediction is probably one of the most intuitive ways to explain a model. In this paper, we establish the link between a set of features to a prediction with a new evaluation criterion, robustness analysis, which measures the minimum distortion distance of adversarial perturbation. By measuring the tolerance level for an adversarial attack, we can extract a set of features that provides the most robust support for a prediction, and also can extract a set of features that contrasts the current prediction to a target class by setting a targeted adversarial attack. By applying this methodology to various prediction tasks across multiple domains, we observe the derived explanations are indeed capturing the significant feature set qualitatively and quantitatively.
Spanning Attack: Reinforce Black-box Attacks with Unlabeled Data
May 11, 2020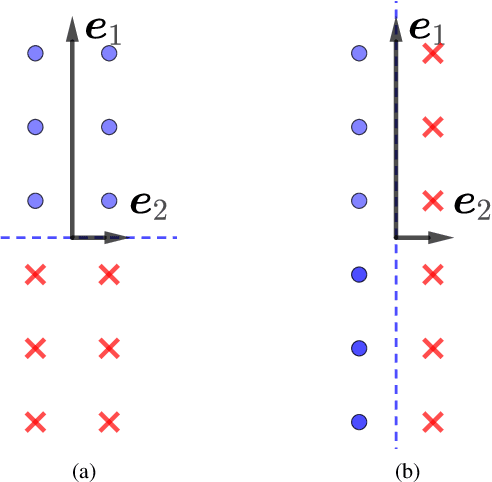
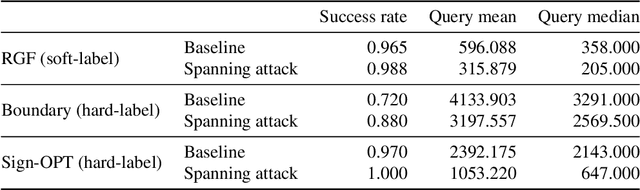
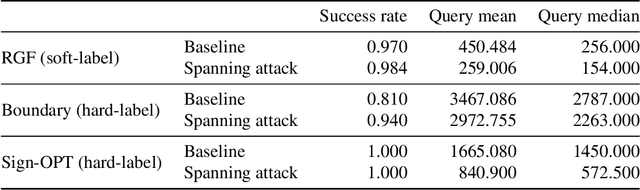

Adversarial black-box attacks aim to craft adversarial perturbations by querying input-output pairs of machine learning models. They are widely used to evaluate the robustness of pre-trained models. However, black-box attacks often suffer from the issue of query inefficiency due to the high dimensionality of the input space, and therefore incur a false sense of model robustness. In this paper, we relax the conditions of the black-box threat model, and propose a novel technique called the spanning attack. By constraining adversarial perturbations in a low-dimensional subspace via spanning an auxiliary unlabeled dataset, the spanning attack significantly improves the query efficiency of black-box attacks. Extensive experiments show that the proposed method works favorably in both soft-label and hard-label black-box attacks. Our code is available at https://github.com/wangwllu/spanning_attack.