 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegoDNN: Block-grained Scaling of Deep Neural Networks for Mobile Vision
Dec 18, 2021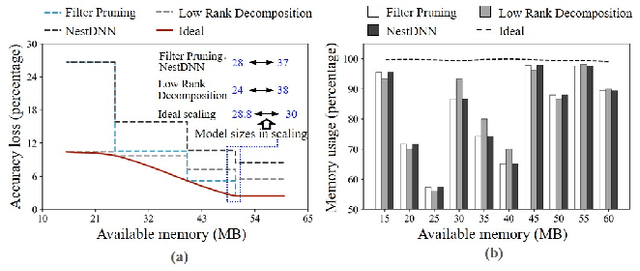
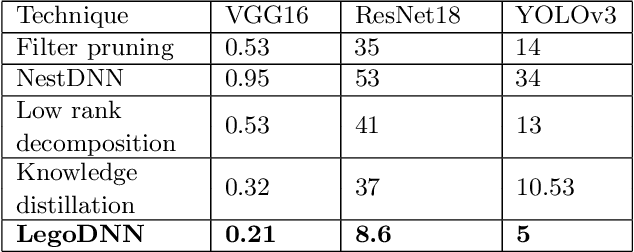
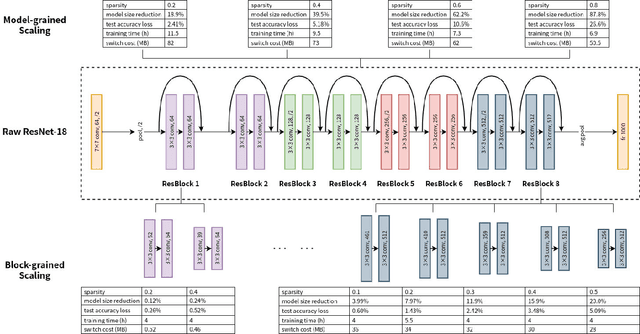
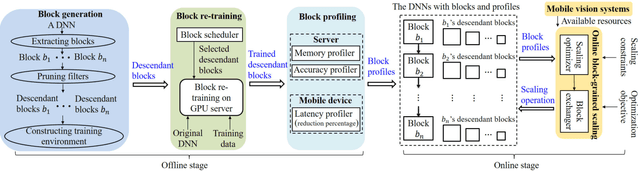
Deep neural networks (DNNs) have become ubiquitous techniques in mobile and embedded systems for applications such as image/object recognition and classification. The trend of executing multiple DNNs simultaneously exacerbate the existing limitations of meeting stringent latency/accuracy requirements on resource constrained mobile devices. The prior art sheds light on exploring the accuracy-resource tradeoff by scaling the model sizes in accordance to resource dynamics. However, such model scaling approaches face to imminent challenges: (i) large space exploration of model sizes, and (ii) prohibitively long training time for different model combinations. In this paper, we present LegoDNN, a lightweight, block-grained scaling solution for running multi-DNN workloads in mobile vision systems. LegoDNN guarantees short model training times by only extracting and training a small number of common blocks (e.g. 5 in VGG and 8 in ResNet) in a DNN. At run-time, LegoDNN optimally combines the descendant models of these blocks to maximize accuracy under specific resources and latency constraints, while reducing switching overhead via smart block-level scaling of the DNN. We implement LegoDNN in TensorFlow Lite and extensively evaluate it against state-of-the-art techniques (FLOP scaling, knowledge distillation and model compression) using a set of 12 popular DNN models. Evaluation results show that LegoDNN provides 1,296x to 279,936x more options in model sizes without increasing training time, thus achieving as much as 31.74% improvement in inference accuracy and 71.07% reduction in scaling energy consumptions.
* 13 pages, 15 figures
Pareto Domain Adaptation
Dec 09, 2021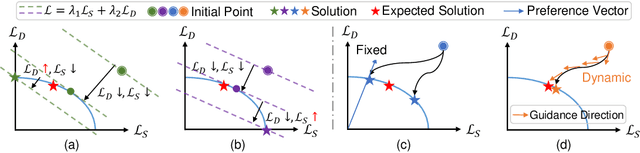
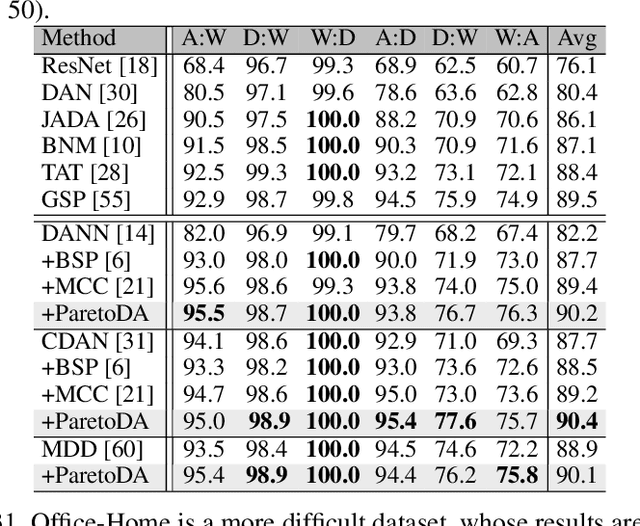
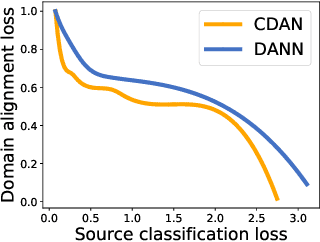
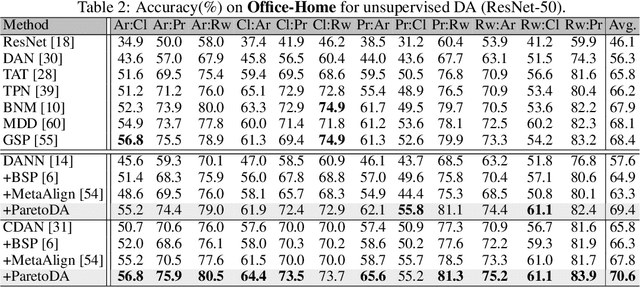
Domain adaptation (DA) attempts to transfer the knowledge from a labeled source domain to an unlabeled target domain that follows different distribution from the source. To achieve this, DA methods include a source classification objective to extract the source knowledge and a domain alignment objective to diminish the domain shift, ensuring knowledge transfer. Typically, former DA methods adopt some weight hyper-parameters to linearly combine the training objectives to form an overall objective. However, the gradient directions of these objectives may conflict with each other due to domain shift. Under such circumstances, the linear optimization scheme might decrease the overall objective value at the expense of damaging one of the training objectives, leading to restricted solutions. In this paper, we rethink the optimization scheme for DA from a gradient-based perspective. We propose a Pareto Domain Adaptation (ParetoDA) approach to control the overall optimization direction, aiming to cooperatively optimize all training objectives. Specifically, to reach a desirable solution on the target domain, we design a surrogate loss mimicking target classification. To improve target-prediction accuracy to support the mimicking, we propose a target-prediction refining mechanism which exploits domain labels via Bayes' theorem. On the other hand, since prior knowledge of weighting schemes for objectives is often unavailable to guide optimization to approach the optimal solution on the target domain, we propose a dynamic preference mechanism to dynamically guide our cooperative optimization by the gradient of the surrogate loss on a held-out unlabeled target dataset. Extensive experiments on image classification and semantic segmentation benchmarks demonstrate the effectiveness of ParetoDA
Active Learning for Domain Adaptation: An Energy-based Approach
Dec 08, 2021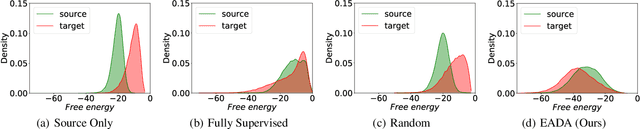
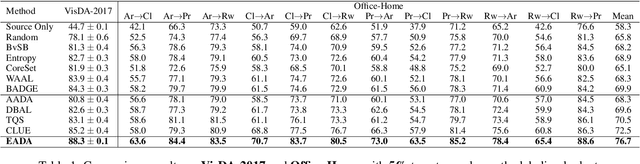
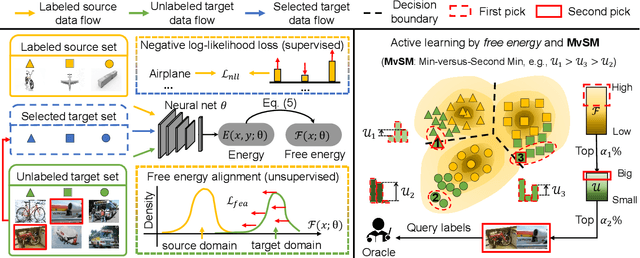
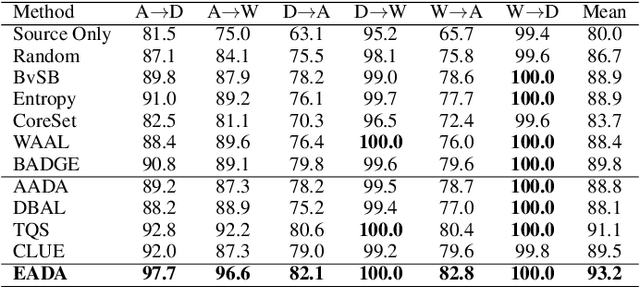
Unsupervised domain adaptation has recently emerged as an effective paradigm for generalizing deep neural networks to new target domains. However, there is still enormous potential to be tapped to reach the fully supervised performance. In this paper, we present a novel active learning strategy to assist knowledge transfer in the target domain, dubbed active domain adaptation. We start from an observation that energy-based models exhibit free energy biases when training (source) and test (target) data come from different distributions. Inspired by this inherent mechanism, we empirically reveal that a simple yet efficient energy-based sampling strategy sheds light on selecting the most valuable target samples than existing approaches requiring particular architectures or computation of the distances. Our algorithm, Energy-based Active Domain Adaptation (EADA), queries groups of targe data that incorporate both domain characteristic and instance uncertainty into every selection round. Meanwhile, by aligning the free energy of target data compact around the source domain via a regularization term, domain gap can be implicitly diminished. Through extensive experiments, we show that EADA surpasses state-of-the-art methods on well-known challenging benchmarks with substantial improvements, making it a useful option in the open world. Code is available at https://github.com/BIT-DA/EADA.
Exploiting Both Domain-specific and Invariant Knowledge via a Win-win Transformer for Unsupervised Domain Adaptation
Nov 25, 2021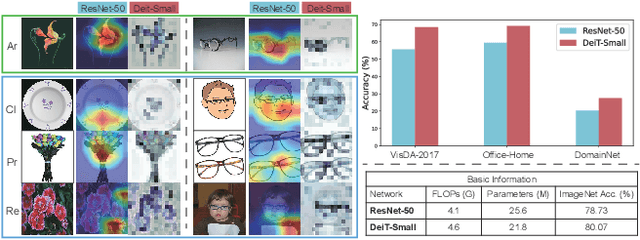
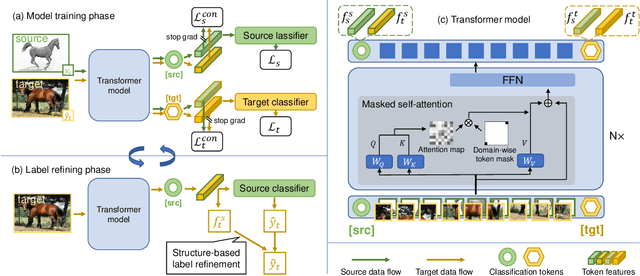
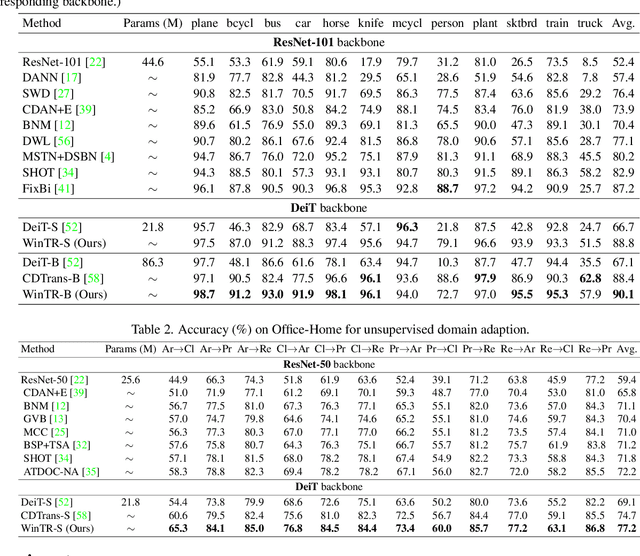
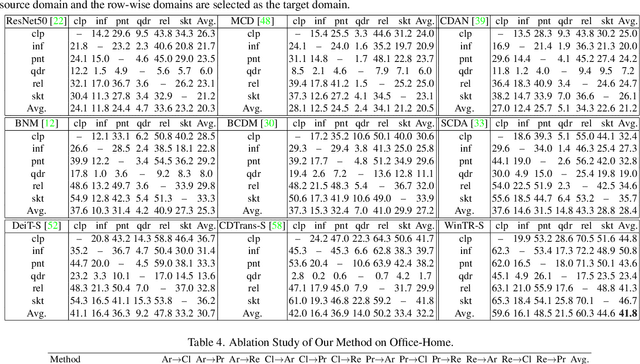
Unsupervised Domain Adaptation (UDA) aims to transfer knowledge from a labeled source domain to an unlabeled target domain. Most existing UDA approaches enable knowledge transfer via learning domain-invariant representation and sharing one classifier across two domains. However, ignoring the domain-specific information that are related to the task, and forcing a unified classifier to fit both domains will limit the feature expressiveness in each domain. In this paper, by observing that the Transformer architecture with comparable parameters can generate more transferable representations than CNN counterparts, we propose a Win-Win TRansformer framework (WinTR) that separately explores the domain-specific knowledge for each domain and meanwhile interchanges cross-domain knowledge. Specifically, we learn two different mappings using two individual classification tokens in the Transformer, and design for each one a domain-specific classifier. The cross-domain knowledge is transferred via source guided label refinement and single-sided feature alignment with respect to source or target, which keeps the integrity of domain-specific information. Extensive experiments on three benchmark datasets show that our method outperforms the state-of-the-art UDA methods, validating the effectiveness of exploiting both domain-specific and invariant
Towards Fewer Annotations: Active Learning via Region Impurity and Prediction Uncertainty for Domain Adaptive Semantic Segmentation
Nov 25, 2021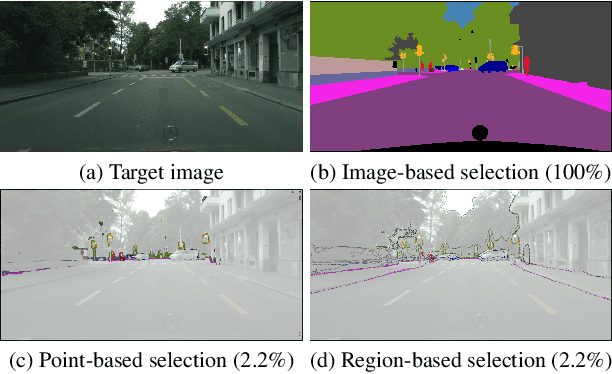
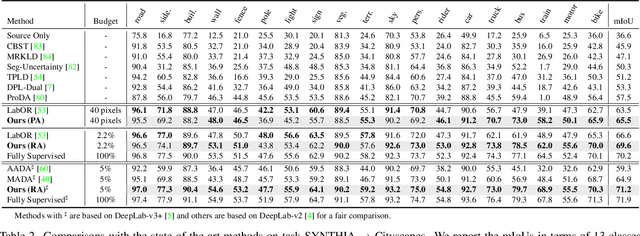
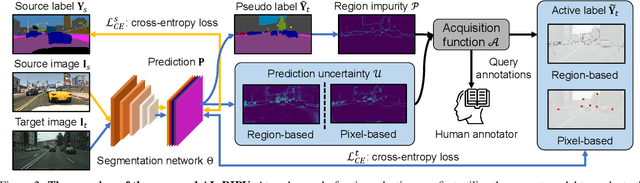
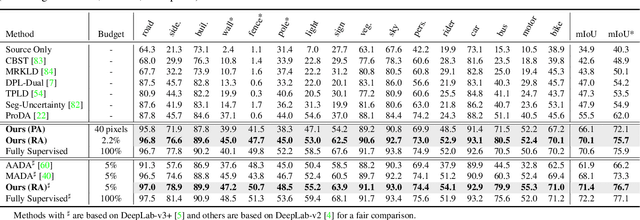
Self-training has greatly facilitated domain adaptive semantic segmentation, which iteratively generates pseudo labels on the target domain and retrains the network. However, since the realistic segmentation datasets are highly imbalanced, target pseudo labels are typically biased to the majority classes and basically noisy, leading to an error-prone and sub-optimal model. To address this issue, we propose a region-based active learning approach for semantic segmentation under a domain shift, aiming to automatically query a small partition of image regions to be labeled while maximizing segmentation performance. Our algorithm, Active Learning via Region Impurity and Prediction Uncertainty (AL-RIPU), introduces a novel acquisition strategy characterizing the spatial adjacency of image regions along with the prediction confidence. We show that the proposed region-based selection strategy makes more efficient use of a limited budget than image-based or point-based counterparts. Meanwhile, we enforce local prediction consistency between a pixel and its nearest neighbor on a source image. Further, we develop a negative learning loss to enhance the discriminative representation learning on the target domain. Extensive experiments demonstrate that our method only requires very few annotations to almost reach the supervised performance and substantially outperforms state-of-the-art methods.
Semantic Concentration for Domain Adaptation
Aug 12, 2021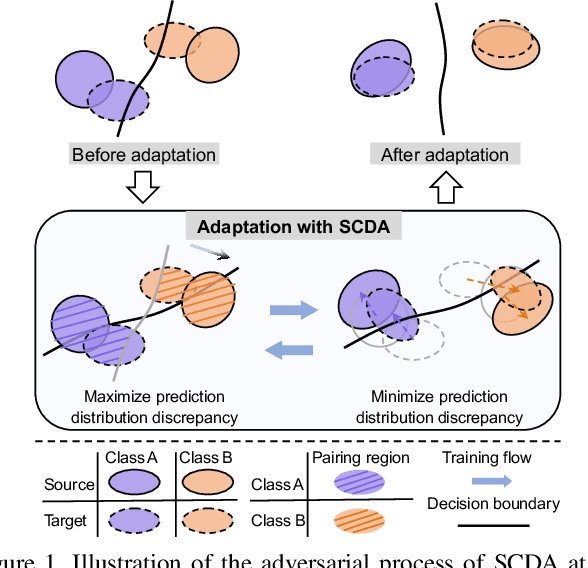
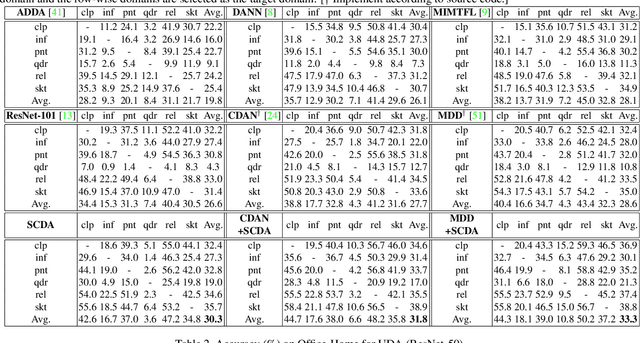
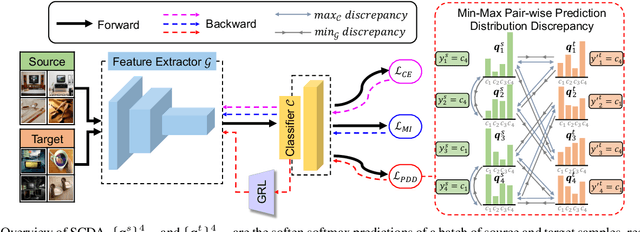
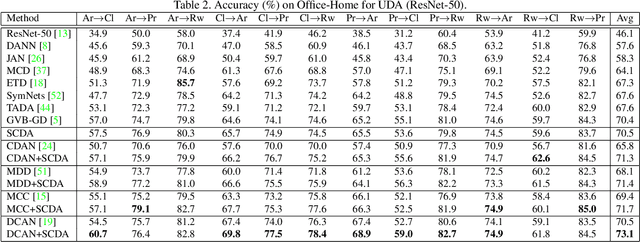
Domain adaptation (DA) paves the way for label annotation and dataset bias issues by the knowledge transfer from a label-rich source domain to a related but unlabeled target domain. A mainstream of DA methods is to align the feature distributions of the two domains. However, the majority of them focus on the entire image features where irrelevant semantic information, e.g., the messy background, is inevitably embedded. Enforcing feature alignments in such case will negatively influence the correct matching of objects and consequently lead to the semantically negative transfer due to the confusion of irrelevant semantics. To tackle this issue, we propose Semantic Concentration for Domain Adaptation (SCDA), which encourages the model to concentrate on the most principal features via the pair-wise adversarial alignment of prediction distributions. Specifically, we train the classifier to class-wisely maximize the prediction distribution divergence of each sample pair, which enables the model to find the region with large differences among the same class of samples. Meanwhile, the feature extractor attempts to minimize that discrepancy, which suppresses the features of dissimilar regions among the same class of samples and accentuates the features of principal parts. As a general method, SCDA can be easily integrated into various DA methods as a regularizer to further boost their performance. Extensive experiments on the cross-domain benchmarks show the efficacy of SCDA.
I2V-GAN: Unpaired Infrared-to-Visible Video Translation
Aug 04, 2021
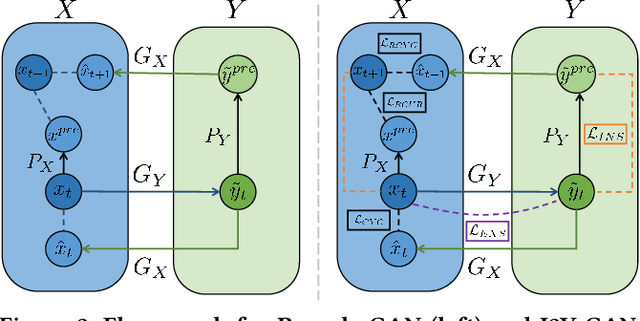
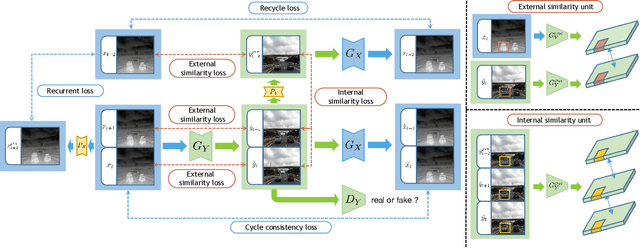
Human vision is often adversely affected by complex environmental factors, especially in night vision scenarios. Thus, infrared cameras are often leveraged to help enhance the visual effects via detecting infrared radiation in the surrounding environment, but the infrared videos are undesirable due to the lack of detailed semantic information. In such a case, an effective video-to-video translation method from the infrared domain to the visible light counterpart is strongly needed by overcoming the intrinsic huge gap between infrared and visible fields. To address this challenging problem, we propose an infrared-to-visible (I2V) video translation method I2V-GAN to generate fine-grained and spatial-temporal consistent visible light videos by given unpaired infrared videos. Technically, our model capitalizes on three types of constraints: 1)adversarial constraint to generate synthetic frames that are similar to the real ones, 2)cyclic consistency with the introduced perceptual loss for effective content conversion as well as style preservation, and 3)similarity constraints across and within domains to enhance the content and motion consistency in both spatial and temporal spaces at a fine-grained level. Furthermore, the current public available infrared and visible light datasets are mainly used for object detection or tracking, and some are composed of discontinuous images which are not suitable for video tasks. Thus, we provide a new dataset for I2V video translation, which is named IRVI. Specifically, it has 12 consecutive video clips of vehicle and monitoring scenes, and both infrared and visible light videos could be apart into 24352 frames. Comprehensive experiments validate that I2V-GAN is superior to the compared SOTA methods in the translation of I2V videos with higher fluency and finer semantic details. The code and IRVI dataset are available at https://github.com/BIT-DA/I2V-GAN.
Semantic Distribution-aware Contrastive Adaptation for Semantic Segmentation
May 11, 2021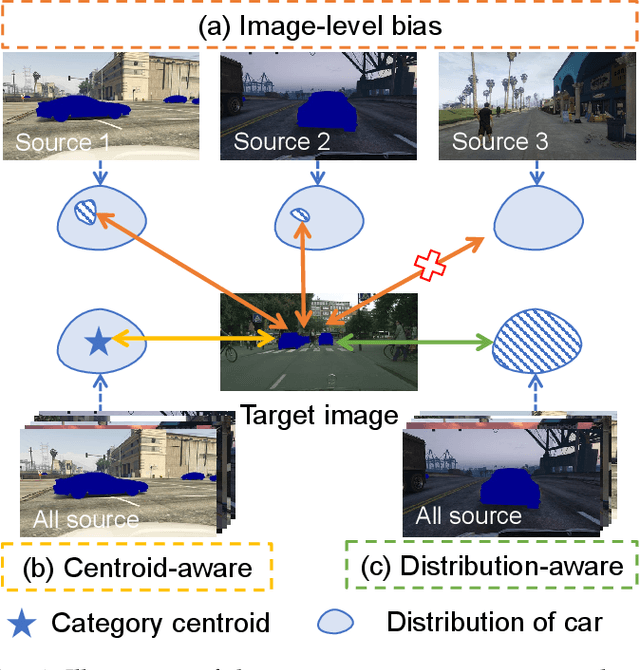
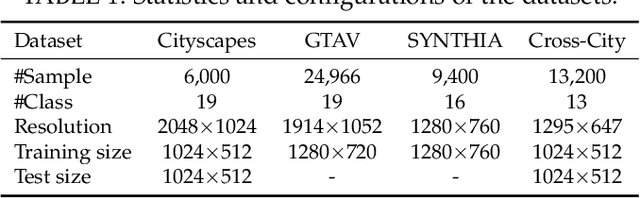
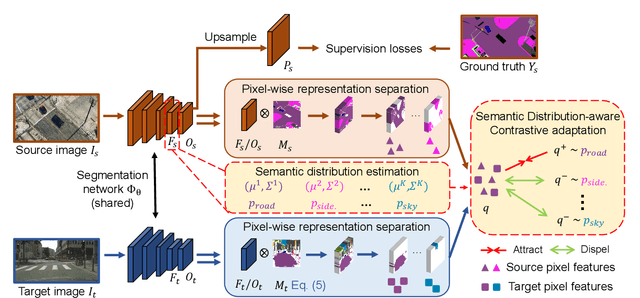
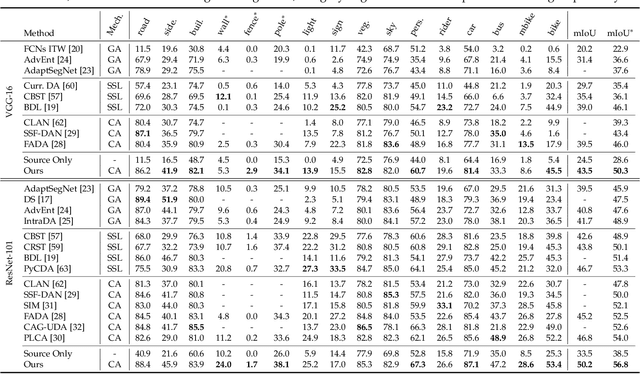
Domain adaptive semantic segmentation refers to making predictions on a certain target domain with only annotations of a specific source domain. Current state-of-the-art works suggest that performing category alignment can alleviate domain shift reasonably. However, they are mainly based on image-to-image adversarial training and little consideration is given to semantic variations of an object among images, failing to capture a comprehensive picture of different categories. This motivates us to explore a holistic representative, the semantic distribution from each category in source domain, to mitigate the problem above. In this paper, we present semantic distribution-aware contrastive adaptation algorithm that enables pixel-wise representation alignment under the guidance of semantic distributions. Specifically, we first design a pixel-wise contrastive loss by considering the correspondences between semantic distributions and pixel-wise representations from both domains. Essentially, clusters of pixel representations from the same category should cluster together and those from different categories should spread out. Next, an upper bound on this formulation is derived by involving the learning of an infinite number of (dis)similar pairs, making it efficient. Finally, we verify that SDCA can further improve segmentation accuracy when integrated with the self-supervised learning. We evaluate SDCA on multiple benchmarks, achieving considerable improvements over existing algorithms.The code is publicly available at https://github.com/BIT-DA/SDCA
MetaSAug: Meta Semantic Augmentation for Long-Tailed Visual Recognition
Apr 07, 2021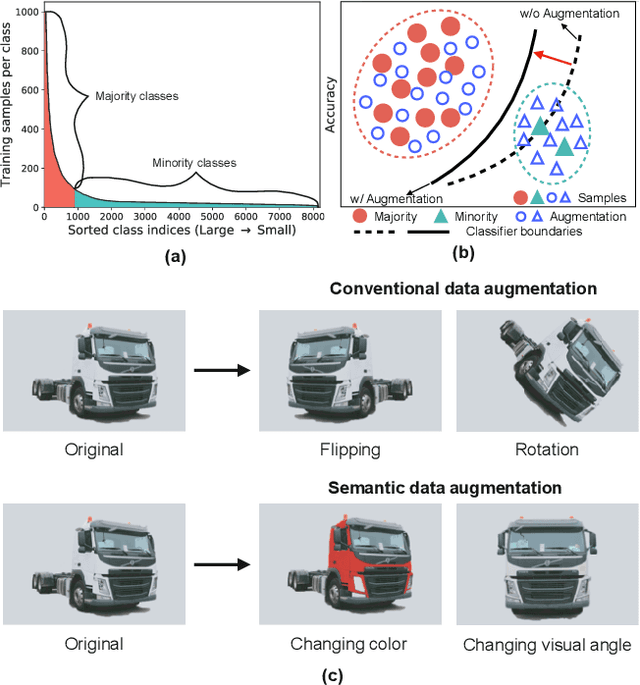
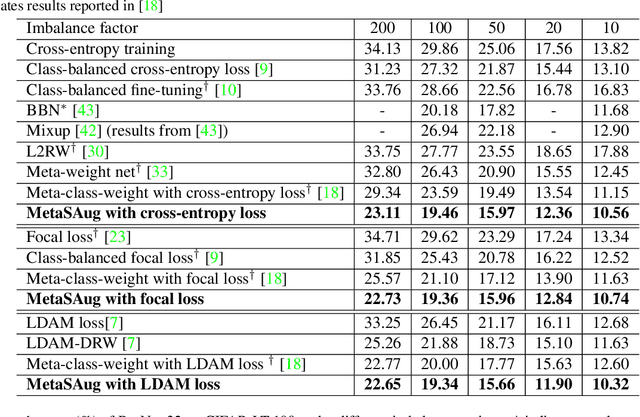
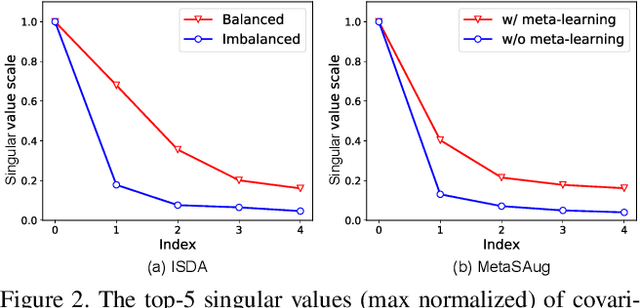
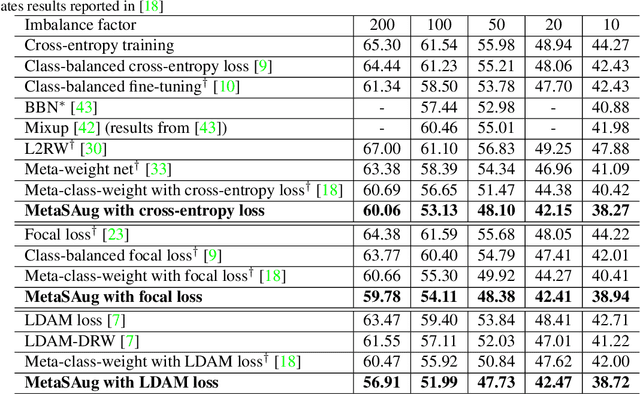
Real-world training data usually exhibits long-tailed distribution, where several majority classes have a significantly larger number of samples than the remaining minority classes. This imbalance degrades the performance of typical supervised learning algorithms designed for balanced training sets. In this paper, we address this issue by augmenting minority classes with a recently proposed implicit semantic data augmentation (ISDA) algorithm, which produces diversified augmented samples by translating deep features along many semantically meaningful directions. Importantly, given that ISDA estimates the class-conditional statistics to obtain semantic directions, we find it ineffective to do this on minority classes due to the insufficient training data. To this end, we propose a novel approach to learn transformed semantic directions with meta-learning automatically. In specific, the augmentation strategy during training is dynamically optimized, aiming to minimize the loss on a small balanced validation set, which is approximated via a meta update step. Extensive empirical results on CIFAR-LT-10/100, ImageNet-LT, and iNaturalist 2017/2018 validate the effectiveness of our method.
Dynamic Domain Adaptation for Efficient Inference
Mar 26, 2021
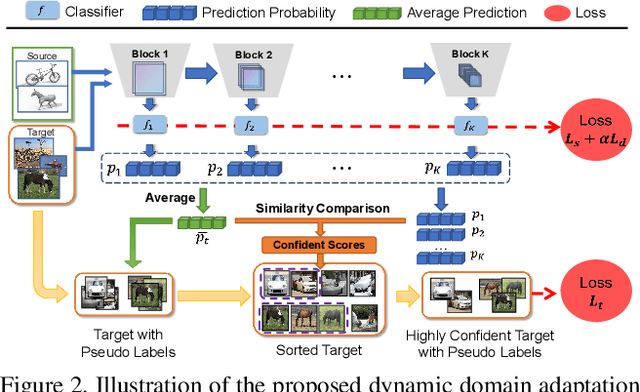

Domain adaptation (DA) enables knowledge transfer from a labeled source domain to an unlabeled target domain by reducing the cross-domain distribution discrepancy. Most prior DA approaches leverage complicated and powerful deep neural networks to improve the adaptation capacity and have shown remarkable success. However, they may have a lack of applicability to real-world situations such as real-time interaction, where low target inference latency is an essential requirement under limited computational budget. In this paper, we tackle the problem by proposing a dynamic domain adaptation (DDA) framework, which can simultaneously achieve efficient target inference in low-resource scenarios and inherit the favorable cross-domain generalization brought by DA. In contrast to static models, as a simple yet generic method, DDA can integrate various domain confusion constraints into any typical adaptive network, where multiple intermediate classifiers can be equipped to infer "easier" and "harder" target data dynamically. Moreover, we present two novel strategies to further boost the adaptation performance of multiple prediction exits: 1) a confidence score learning strategy to derive accurate target pseudo labels by fully exploring the prediction consistency of different classifiers; 2) a class-balanced self-training strategy to explicitly adapt multi-stage classifiers from source to target without losing prediction diversity. Extensive experiments on multiple benchmarks are conducted to verify that DDA can consistently improve the adaptation performance and accelerate target inference under domain shift and limited resources scenarios