 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-free Dense Depth Distillation
Aug 26, 2022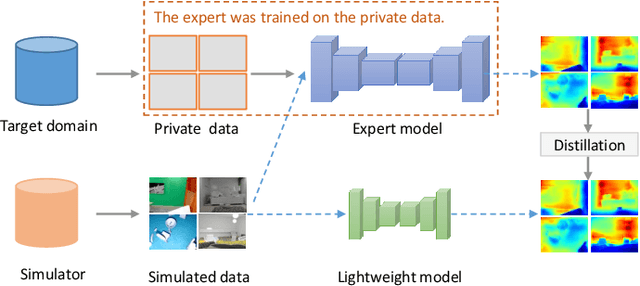
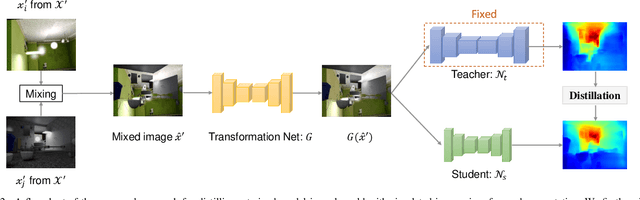

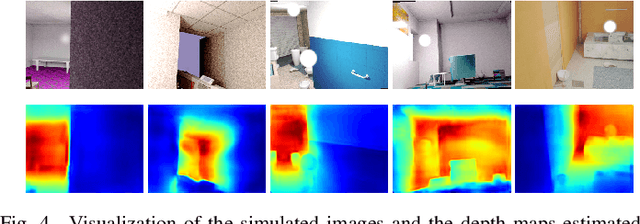
We study data-free knowledge distillation (KD) for monocular depth estimation (MDE), which learns a lightweight network for real-world depth perception by compressing from a trained expert model under the teacher-student framework while lacking training data in the target domain. Owing to the essential difference between dense regression and image recognition, previous methods of data-free KD are not applicable to MDE. To strengthen the applicability in the real world, in this paper, we seek to apply KD with out-of-distribution simulated images. The major challenges are i) lacking prior information about object distribution of the original training data; ii) the domain shift between the real world and the simulation. To cope with the first difficulty, we apply object-wise image mixing to generate new training samples for maximally covering distributed patterns of objects in the target domain. To tackle the second difficulty, we propose to utilize a transformation network that efficiently learns to fit the simulated data to the feature distribution of the teacher model. We evaluate the proposed approach for various depth estimation models and two different datasets. As a result, our method outperforms the baseline KD by a good margin and even achieves slightly better performance with as few as $1/6$ images, demonstrating a clear superiority.
Deep Depth Completion: A Survey
May 17, 2022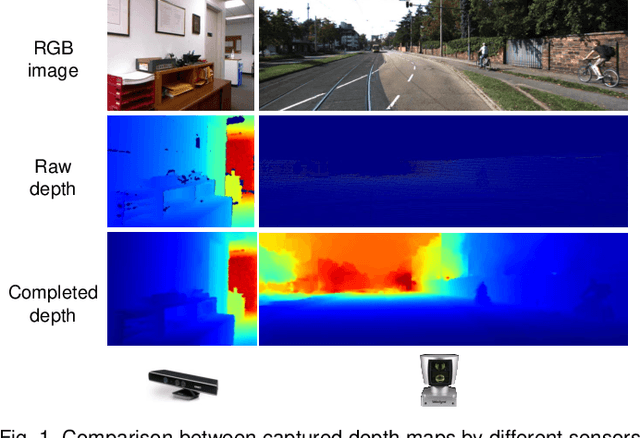
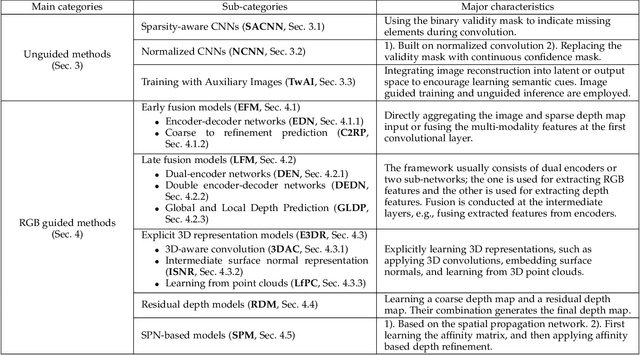
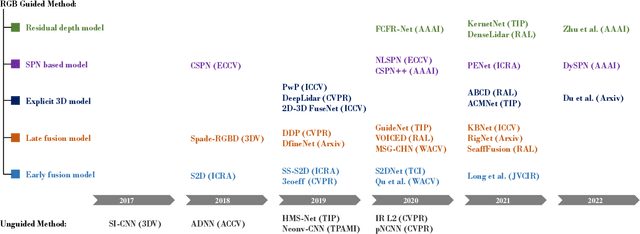
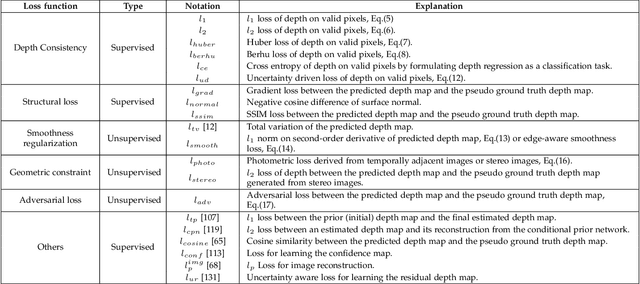
Depth completion aims at predicting dense pixel-wise depth from a sparse map captured from a depth sensor. It plays an essential role in various applications such as autonomous driving, 3D reconstruction, augmented reality, and robot navigation. Recent successes on the task have been demonstrated and dominated by deep learning based solutions. In this article, for the first time, we provide a comprehensive literature review that helps readers better grasp the research trends and clearly understand the current advances. We investigate the related studies from the design aspects of network architectures, loss functions, benchmark datasets, and learning strategies with a proposal of a novel taxonomy that categorizes existing methods. Besides, we present a quantitative comparison of model performance on two widely used benchmark datasets, including an indoor and an outdoor dataset. Finally, we discuss the challenges of prior works and provide readers with some insights for future research directions.
AgreementLearning: An End-to-End Framework for Learning with Multiple Annotators without Groundtruth
Sep 08, 2021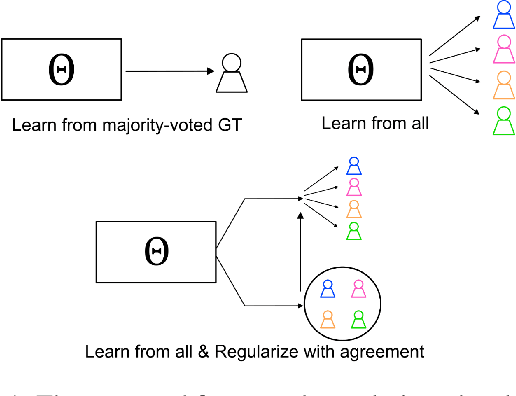
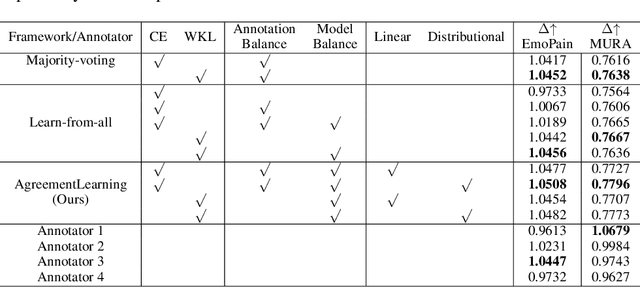
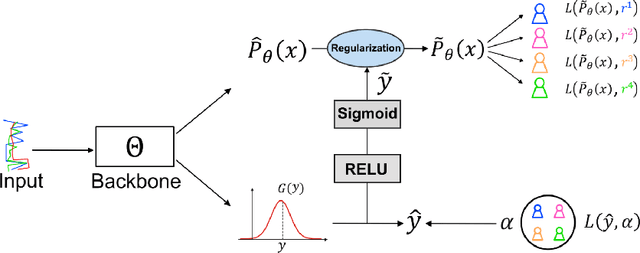
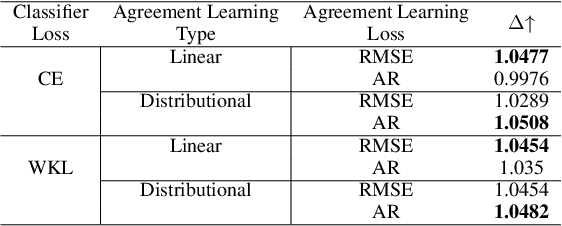
The annotation of domain experts is important for some medical applications where the objective groundtruth is ambiguous to define, e.g., the rehabilitation for some chronic diseases, and the prescreening of some musculoskeletal abnormalities without further medical examinations. However, improper uses of the annotations may hinder developing reliable models. On one hand, forcing the use of a single groundtruth generated from multiple annotations is less informative for the modeling. On the other hand, feeding the model with all the annotations without proper regularization is noisy given existing disagreements. For such issues, we propose a novel agreement learning framework to tackle the challenge of learning from multiple annotators without objective groundtruth. The framework has two streams, with one stream fitting with the multiple annotators and the other stream learning agreement information between the annotators. In particular, the agreement learning stream produces regularization information to the classifier stream, tuning its decision to be better in line with the agreement between the annotators. The proposed method can be easily plugged to existing backbones developed with majority-voted groundtruth or multiple annotations. Thereon, experiments on two medical datasets demonstrate improved agreement levels with annotators.
Boosting Light-Weight Depth Estimation Via Knowledge Distillation
May 13, 2021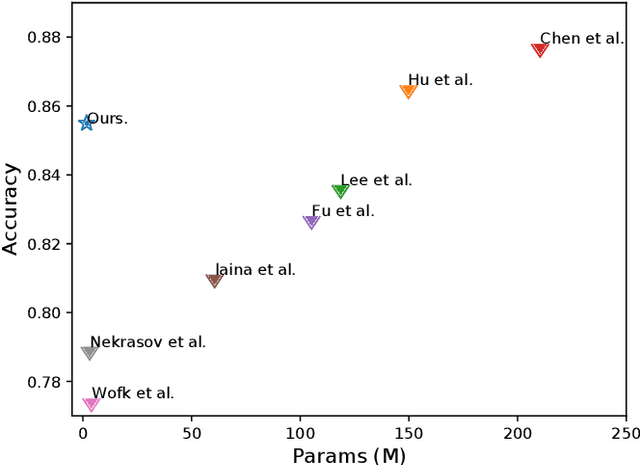

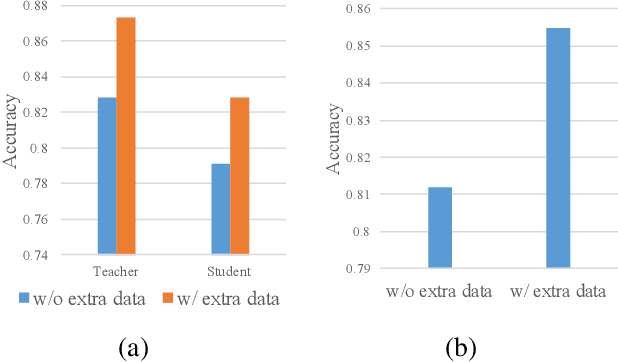
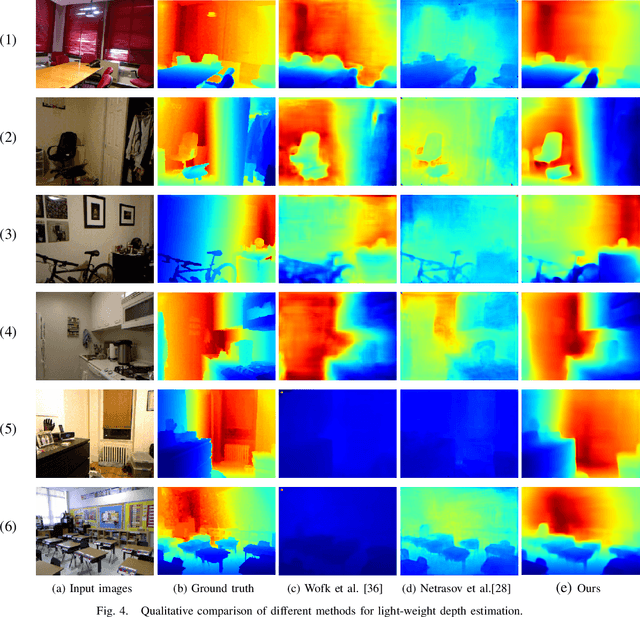
The advanced performance of depth estimation is achieved by the employment of large and complex neural networks. While the performance has still been continuously improved, we argue that the depth estimation has to be accurate and efficient. It's a preliminary requirement for real-world applications. However, fast depth estimation tends to lower the performance as the trade-off between the model's capacity and accuracy. In this paper, we attempt to archive highly accurate depth estimation with a light-weight network. To this end, we first introduce a compact network that can estimate a depth map in real-time. We then technically show two complementary and necessary strategies to improve the performance of the light-weight network. As the number of real-world scenes is infinite, the first is the employment of auxiliary data that increases the diversity of training data. The second is the use of knowledge distillation to further boost the performance. Through extensive and rigorous experiments, we show that our method outperforms previous light-weight methods in terms of inference accuracy, computational efficiency and generalization. We can achieve comparable performance compared to state-of-the-of-art methods with only 1% parameters, on the other hand, our method outperforms other light-weight methods by a significant margin.
Federated Few-Shot Learning with Adversarial Learning
Apr 01, 2021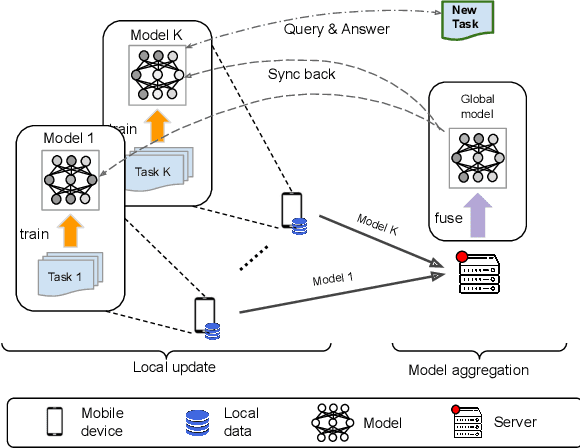

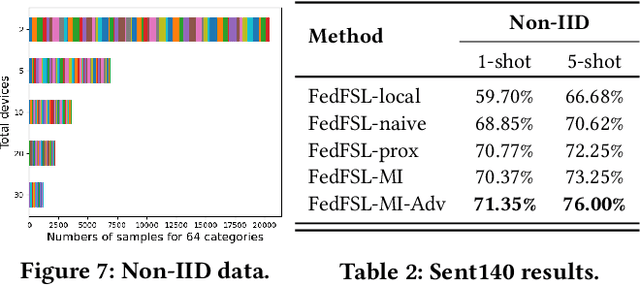
We are interested in developing a unified machine learning model over many mobile devices for practical learning tasks, where each device only has very few training data. This is a commonly encountered situation in mobile computing scenarios, where data is scarce and distributed while the tasks are distinct. In this paper, we propose a federated few-shot learning (FedFSL) framework to learn a few-shot classification model that can classify unseen data classes with only a few labeled samples. With the federated learning strategy, FedFSL can utilize many data sources while keeping data privacy and communication efficiency. There are two technical challenges: 1) directly using the existing federated learning approach may lead to misaligned decision boundaries produced by client models, and 2) constraining the decision boundaries to be similar over clients would overfit to training tasks but not adapt well to unseen tasks. To address these issues, we propose to regularize local updates by minimizing the divergence of client models. We also formulate the training in an adversarial fashion and optimize the client models to produce a discriminative feature space that can better represent unseen data samples. We demonstrate the intuitions and conduct experiments to show our approaches outperform baselines by more than 10% in learning vision tasks and 5% in language tasks.
Projection Robust Wasserstein Distance and Riemannian Optimization
Jun 28, 2020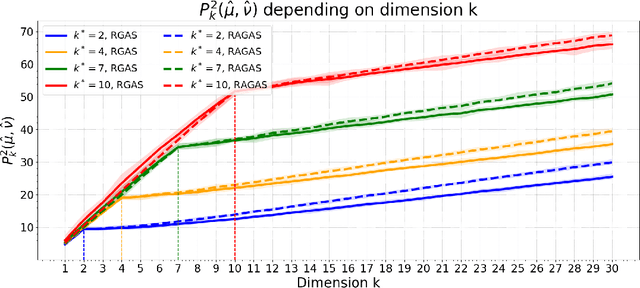

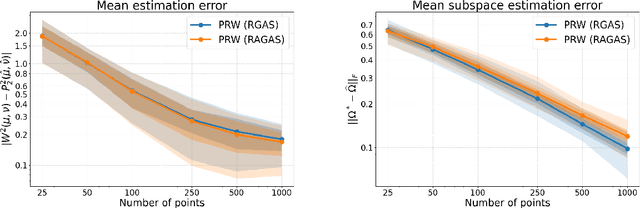
Projection robust Wasserstein (PRW) distance, or Wasserstein projection pursuit (WPP), is a robust variant of the Wasserstein distance. Recent work suggests that this quantity is more robust than the standard Wasserstein distance, in particular when comparing probability measures in high-dimensions. However, it is ruled out for practical application because the optimization model is essentially non-convex and non-smooth which makes the computation intractable. Our contribution in this paper is to revisit the original motivation behind WPP/PRW, but take the hard route of showing that, despite its non-convexity and lack of nonsmoothness, and even despite some hardness results proved by~\citet{Niles-2019-Estimation} in a minimax sense, the original formulation for PRW/WPP \textit{can} be efficiently computed in practice using Riemannian optimization, yielding in relevant cases better behavior than its convex relaxation. More specifically, we provide three simple algorithms with solid theoretical guarantee on their complexity bound (one in the appendix), and demonstrate their effectiveness and efficiency by conducing extensive experiments on synthetic and real data. This paper provides a first step into a computational theory of the PRW distance and provides the links between optimal transport and Riemannian optimization.
Federated Generative Adversarial Learning
May 24, 2020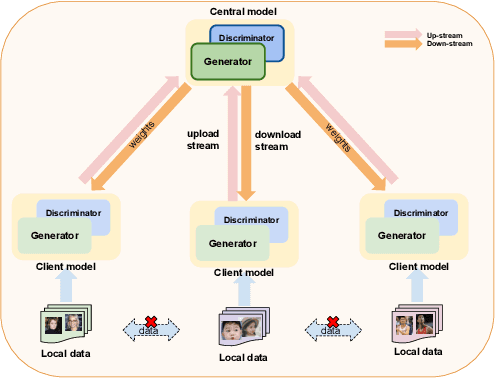
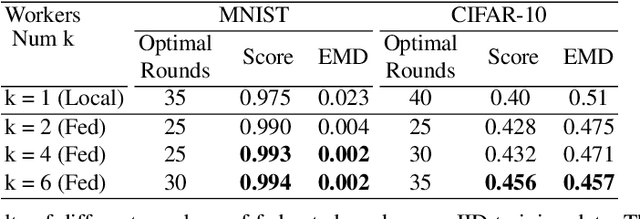
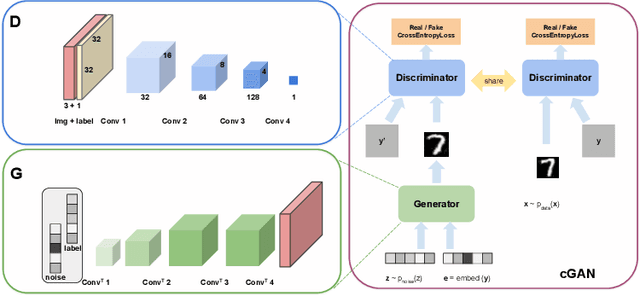
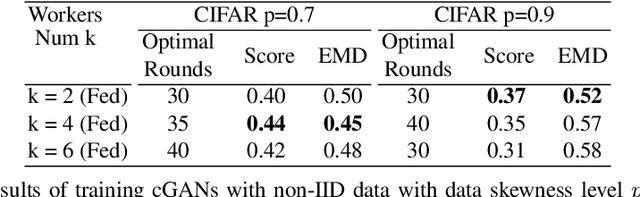
This work studies training generative adversarial networks under the federated learning setting. Generative adversarial networks (GANs) have achieved advancement in various real-world applications, such as image editing, style transfer, scene generations, etc. However, like other deep learning models, GANs are also suffering from data limitation problems in real cases. To boost the performance of GANs in target tasks, collecting images as many as possible from different sources becomes not only important but also essential. For example, to build a robust and accurate bio-metric verification system, huge amounts of images might be collected from surveillance cameras, and/or uploaded from cellphones by users accepting agreements. In an ideal case, utilize all those data uploaded from public and private devices for model training is straightforward. Unfortunately, in the real scenarios, this is hard due to a few reasons. At first, some data face the serious concern of leakage, and therefore it is prohibitive to upload them to a third-party server for model training; at second, the images collected by different kinds of devices, probably have distinctive biases due to various factors, $\textit{e.g.}$, collector preferences, geo-location differences, which is also known as "domain shift". To handle those problems, we propose a novel generative learning scheme utilizing a federated learning framework. Following the configuration of federated learning, we conduct model training and aggregation on one center and a group of clients. Specifically, our method learns the distributed generative models in clients, while the models trained in each client are fused into one unified and versatile model in the center. We perform extensive experiments to compare different federation strategies, and empirically examine the effectiveness of federation under different levels of parallelism and data skewness.
Heterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
Apr 08, 2019
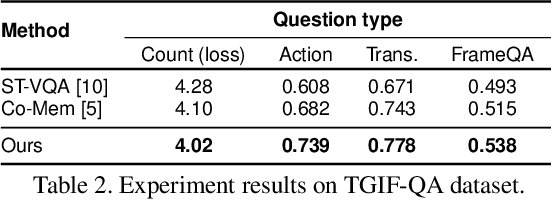
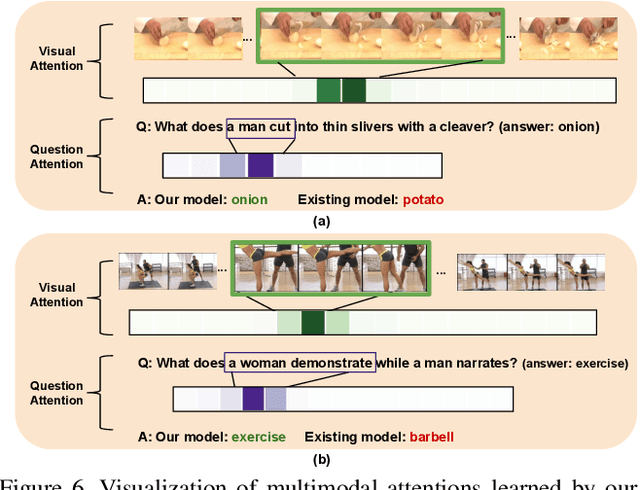
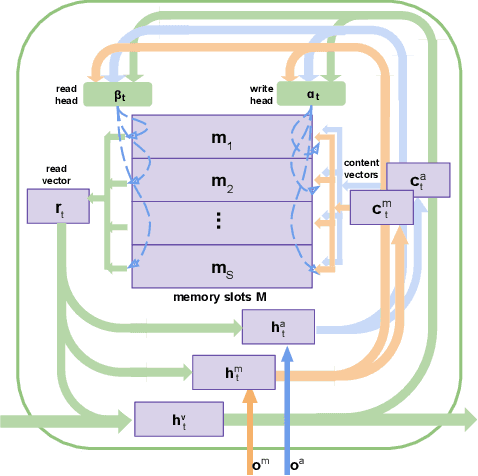
In this paper, we propose a novel end-to-end trainable Video Question Answering (VideoQA) framework with three major components: 1) a new heterogeneous memory which can effectively learn global context information from appearance and motion features; 2) a redesigned question memory which helps understand the complex semantics of question and highlights queried subjects; and 3) a new multimodal fusion layer which performs multi-step reasoning by attending to relevant visual and textual hints with self-updated attention. Our VideoQA model firstly generates the global context-aware visual and textual features respectively by interacting current inputs with memory contents. After that, it makes the attentional fusion of the multimodal visual and textual representations to infer the correct answer. Multiple cycles of reasoning can be made to iteratively refine attention weights of the multimodal data and improve the final representation of the QA pair. Experimental results demonstrate our approach achieves state-of-the-art performance on four VideoQA benchmark datasets.
Forecasting Hands and Objects in Future Frames
Aug 23, 2018
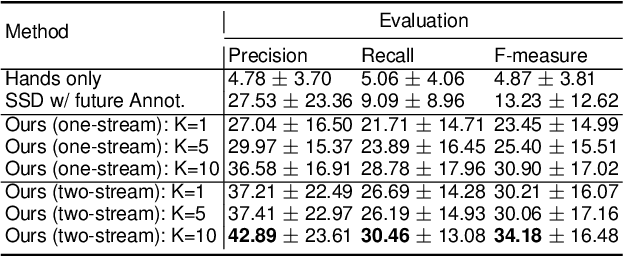
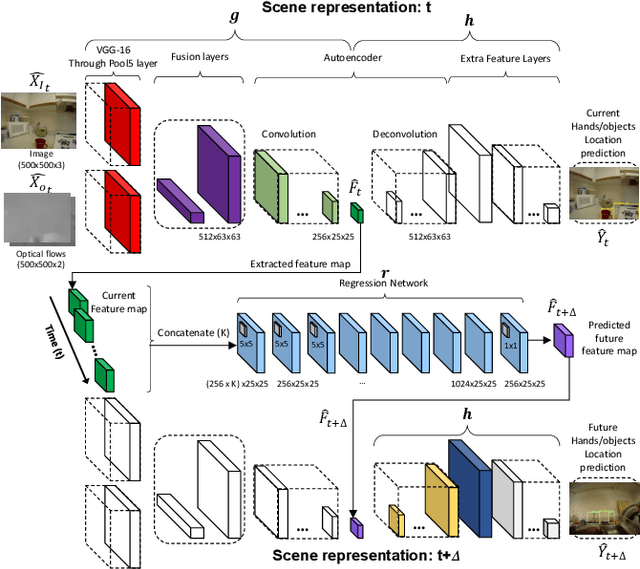
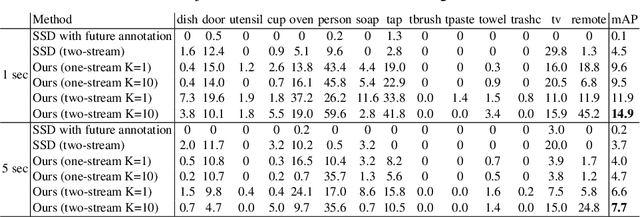
This paper presents an approach to forecast future presence and location of human hands and objects. Given an image frame, the goal is to predict what objects will appear in the future frame (e.g., 5 seconds later) and where they will be located at, even when they are not visible in the current frame. The key idea is that (1) an intermediate representation of a convolutional object recognition model abstracts scene information in its frame and that (2) we can predict (i.e., regress) such representations corresponding to the future frames based on that of the current frame. We design a new two-stream convolutional neural network (CNN) architecture for videos by extending the state-of-the-art convolutional object detection network, and present a new fully convolutional regression network for predicting future scene representations. Our experiments confirm that combining the regressed future representation with our detection network allows reliable estimation of future hands and objects in videos. We obtain much higher accuracy compared to the state-of-the-art future object presence forecast method on a public dataset.
Joint Person Segmentation and Identification in Synchronized First- and Third-person Videos
Jul 25, 2018
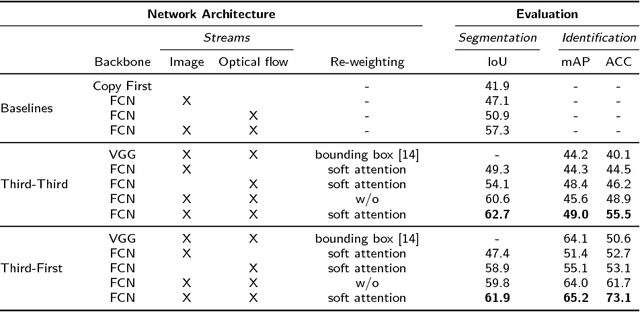
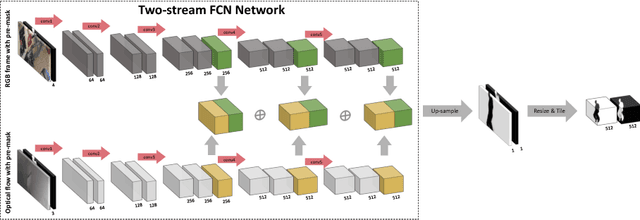
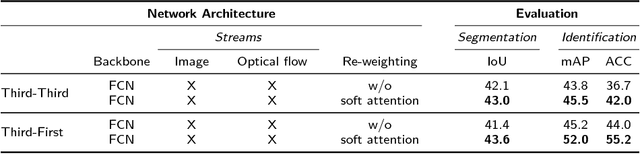
In a world of pervasive cameras, public spaces are often captured from multiple perspectives by cameras of different types, both fixed and mobile. An important problem is to organize these heterogeneous collections of videos by finding connections between them, such as identifying correspondences between the people appearing in the videos and the people holding or wearing the cameras. In this paper, we wish to solve two specific problems: (1) given two or more synchronized third-person videos of a scene, produce a pixel-level segmentation of each visible person and identify corresponding people across different views (i.e., determine who in camera A corresponds with whom in camera B), and (2) given one or more synchronized third-person videos as well as a first-person video taken by a mobile or wearable camera, segment and identify the camera wearer in the third-person videos. Unlike previous work which requires ground truth bounding boxes to estimate the correspondences, we perform person segmentation and identification jointly. We find that solving these two problems simultaneously is mutually beneficial, because better fine-grained segmentation allows us to better perform matching across views, and information from multiple views helps us perform more accurate segmentation. We evaluate our approach on two challenging datasets of interacting people captured from multiple wearable cameras, and show that our proposed method performs significantly better than the state-of-the-art on both person segmentation and identification.