 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeterogeneous Memory Enhanced Multimodal Attention Model for Video Question Answering
Paper and Code

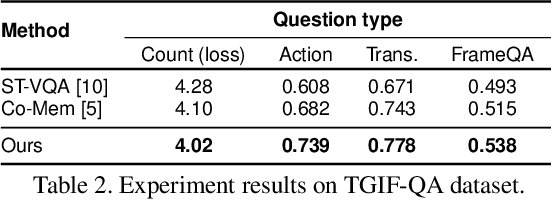
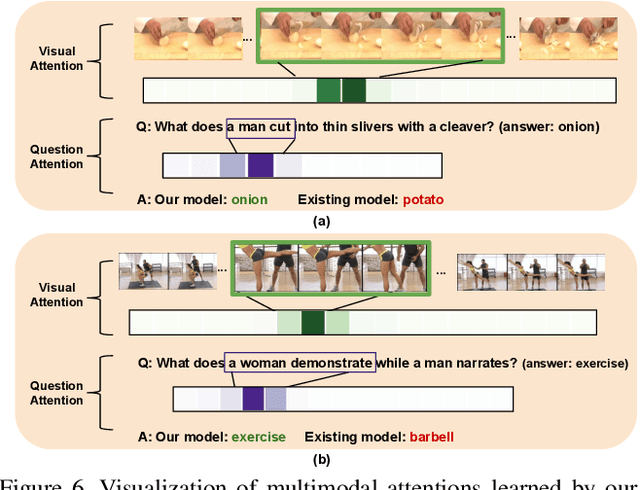
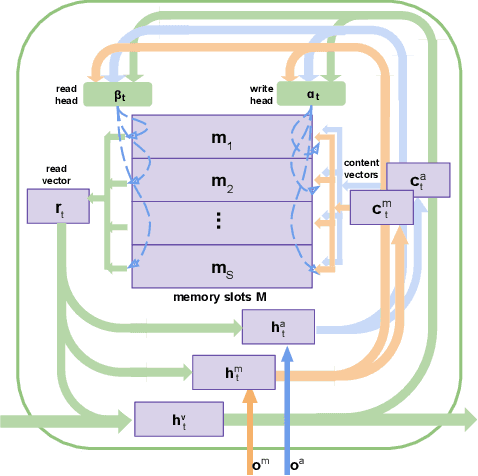
In this paper, we propose a novel end-to-end trainable Video Question Answering (VideoQA) framework with three major components: 1) a new heterogeneous memory which can effectively learn global context information from appearance and motion features; 2) a redesigned question memory which helps understand the complex semantics of question and highlights queried subjects; and 3) a new multimodal fusion layer which performs multi-step reasoning by attending to relevant visual and textual hints with self-updated attention. Our VideoQA model firstly generates the global context-aware visual and textual features respectively by interacting current inputs with memory contents. After that, it makes the attentional fusion of the multimodal visual and textual representations to infer the correct answer. Multiple cycles of reasoning can be made to iteratively refine attention weights of the multimodal data and improve the final representation of the QA pair. Experimental results demonstrate our approach achieves state-of-the-art performance on four VideoQA benchmark datasets.