 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUDM-GRPO: Stable and Efficient Group Relative Policy Optimization for Uniform Discrete Diffusion Models
Apr 21, 2026Uniform Discrete Diffusion Model (UDM) has recently emerged as a promising paradigm for discrete generative modeling; however, its integration with reinforcement learning remains largely unexplored. We observe that naively applying GRPO to UDM leads to training instability and marginal performance gains. To address this, we propose UDM-GRPO, the first framework to integrate UDM with RL. Our method is guided by two key insights: (i) treating the final clean sample as the action provides more accurate and stable optimization signals; and (ii) reconstructing trajectories via the diffusion forward process better aligns probability paths with the pretraining distribution. Additionally, we introduce two strategies, Reduced-Step and CFG-Free, to further improve training efficiency. UDM-GRPO significantly improves base model performance across multiple T2I tasks. Notably, GenEval accuracy improves from $69\%$ to $96\%$ and PickScore increases from $20.46$ to $23.81$, achieving state-of-the-art performance in both continuous and discrete settings. On the OCR benchmark, accuracy rises from $8\%$ to $57\%$, further validating the generalization ability of our method. Code is available at https://github.com/Yovecent/UDM-GRPO.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
Differentiable Collision-Supervised Tooth Arrangement Network with a Decoupling Perspective
Sep 18, 2024



Tooth arrangement is an essential step in the digital orthodontic planning process. Existing learning-based methods use hidden teeth features to directly regress teeth motions, which couples target pose perception and motion regression. It could lead to poor perceptions of three-dimensional transformation. They also ignore the possible overlaps or gaps between teeth of predicted dentition, which is generally unacceptable. Therefore, we propose DTAN, a differentiable collision-supervised tooth arrangement network, decoupling predicting tasks and feature modeling. DTAN decouples the tooth arrangement task by first predicting the hidden features of the final teeth poses and then using them to assist in regressing the motions between the beginning and target teeth. To learn the hidden features better, DTAN also decouples the teeth-hidden features into geometric and positional features, which are further supervised by feature consistency constraints. Furthermore, we propose a novel differentiable collision loss function for point cloud data to constrain the related gestures between teeth, which can be easily extended to other 3D point cloud tasks. We propose an arch-width guided tooth arrangement network, named C-DTAN, to make the results controllable. We construct three different tooth arrangement datasets and achieve drastically improved performance on accuracy and speed compared with existing methods.
A Neural Rendering Framework for Free-Viewpoint Relighting
Nov 26, 2019

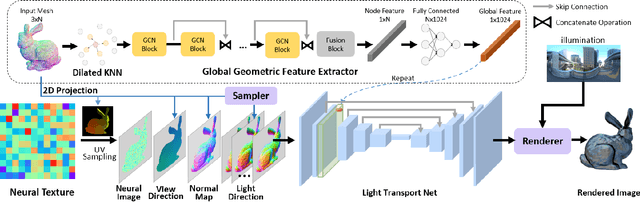
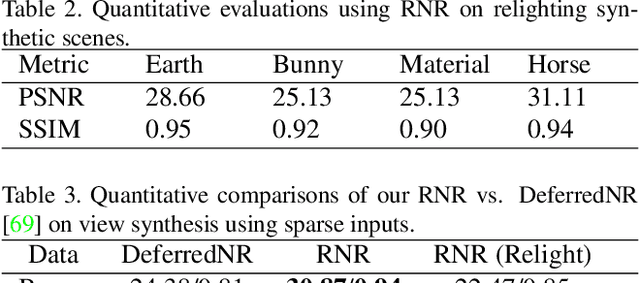
We present a novel Relightable Neural Renderer (RNR) for simultaneous view synthesis and relighting using multi-view image inputs. Existing neural rendering (NR) does not explicitly model the physical rendering process and hence has limited capabilities on relighting. RNR instead models image formation in terms of environment lighting, object intrinsic attributes, and the light transport function (LTF), each corresponding to a learnable component. In particular, the incorporation of a physically based rendering process not only enables relighting but also improves the quality of novel view synthesis. Comprehensive experiments on synthetic and real data show that RNR provides a practical and effective solution for conducting free-viewpoint relighting.