 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Training of Neural Networks at Arbitrary Precision and Sparsity
Sep 14, 2024



The discontinuous operations inherent in quantization and sparsification introduce obstacles to backpropagation. This is particularly challenging when training deep neural networks in ultra-low precision and sparse regimes. We propose a novel, robust, and universal solution: a denoising affine transform that stabilizes training under these challenging conditions. By formulating quantization and sparsification as perturbations during training, we derive a perturbation-resilient approach based on ridge regression. Our solution employs a piecewise constant backbone model to ensure a performance lower bound and features an inherent noise reduction mechanism to mitigate perturbation-induced corruption. This formulation allows existing models to be trained at arbitrarily low precision and sparsity levels with off-the-shelf recipes. Furthermore, our method provides a novel perspective on training temporal binary neural networks, contributing to ongoing efforts to narrow the gap between artificial and biological neural networks.
MobileNetV4 -- Universal Models for the Mobile Ecosystem
Apr 16, 2024



We present the latest generation of MobileNets, known as MobileNetV4 (MNv4), featuring universally efficient architecture designs for mobile devices. At its core, we introduce the Universal Inverted Bottleneck (UIB) search block, a unified and flexible structure that merges Inverted Bottleneck (IB), ConvNext, Feed Forward Network (FFN), and a novel Extra Depthwise (ExtraDW) variant. Alongside UIB, we present Mobile MQA, an attention block tailored for mobile accelerators, delivering a significant 39% speedup. An optimized neural architecture search (NAS) recipe is also introduced which improves MNv4 search effectiveness. The integration of UIB, Mobile MQA and the refined NAS recipe results in a new suite of MNv4 models that are mostly Pareto optimal across mobile CPUs, DSPs, GPUs, as well as specialized accelerators like Apple Neural Engine and Google Pixel EdgeTPU - a characteristic not found in any other models tested. Finally, to further boost accuracy, we introduce a novel distillation technique. Enhanced by this technique, our MNv4-Hybrid-Large model delivers 87% ImageNet-1K accuracy, with a Pixel 8 EdgeTPU runtime of just 3.8ms.
Exploiting Invariance in Training Deep Neural Networks
Mar 30, 2021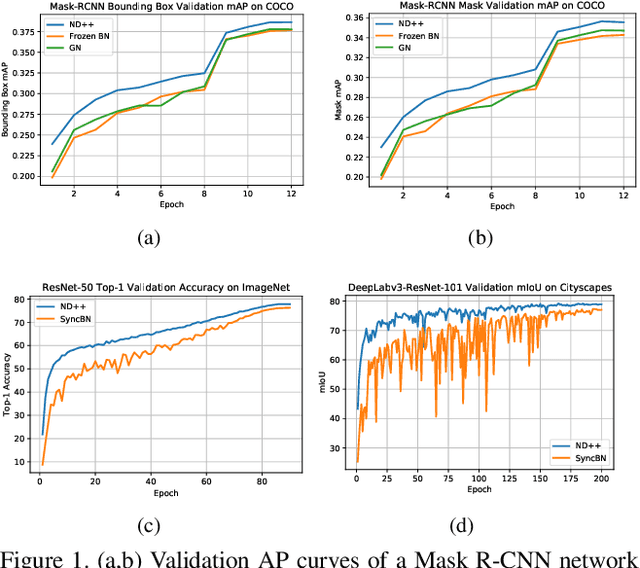
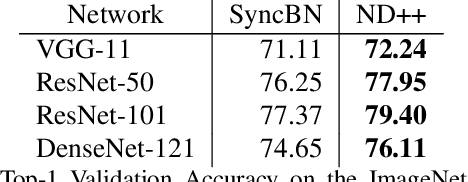

Inspired by two basic mechanisms in animal visual systems, we introduce a feature transform technique that imposes invariance properties in the training of deep neural networks. The resulting algorithm requires less parameter tuning, trains well with an initial learning rate 1.0, and easily generalizes to different tasks. We enforce scale invariance with local statistics in the data to align similar samples generated in diverse situations. To accelerate convergence, we enforce a GL(n)-invariance property with global statistics extracted from a batch that the gradient descent solution should remain invariant under basis change. Tested on ImageNet, MS COCO, and Cityscapes datasets, our proposed technique requires fewer iterations to train, surpasses all baselines by a large margin, seamlessly works on both small and large batch size training, and applies to different computer vision tasks of image classification, object detection, and semantic segmentation.
Network Deconvolution
May 28, 2019
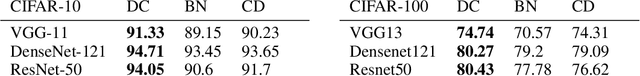
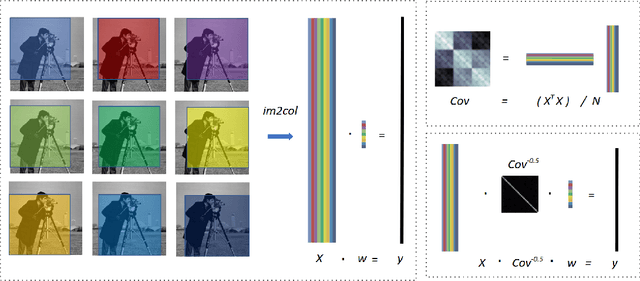

Convolution is a central operation in Convolutional Neural Networks (CNNs), which applies a kernel or mask to overlapping regions shifted across the image. In this work we show that the underlying kernels are trained with highly correlated data, which leads to co-adaptation of model weights. To address this issue we propose what we call network deconvolution, a procedure that aims to remove pixel-wise and channel-wise correlations before the data is fed into each layer. We show that by removing this correlation we are able to achieve better convergence rates during model training with superior results without the use of batch normalization on the CIFAR-10, CIFAR-100, MNIST, Fashion-MNIST datasets, as well as against reference models from "model zoo" on the ImageNet standard benchmark.
EV-IMO: Motion Segmentation Dataset and Learning Pipeline for Event Cameras
Mar 18, 2019
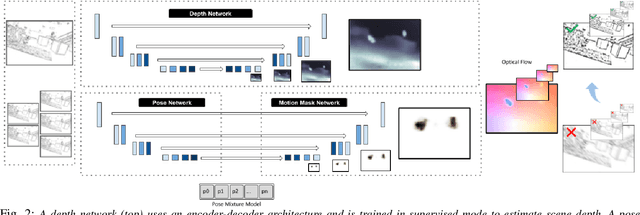
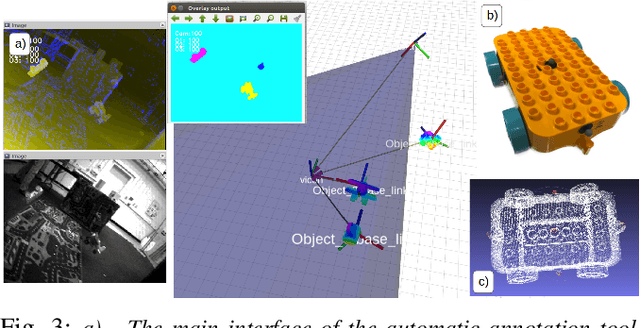

We present the first event-based learning approach for motion segmentation in indoor scenes and the first event-based dataset - EV-IMO - which includes accurate pixel-wise motion masks, egomotion and ground truth depth. Our approach is based on an efficient implementation of the SfM learning pipeline using a low parameter neural network architecture on event data. In addition to camera egomotion and a dense depth map, the network estimates pixel-wise independently moving object segmentation and computes per-object 3D translational velocities for moving objects. We also train a shallow network with just 40k parameters, which is able to compute depth and egomotion. Our EV-IMO dataset features 32 minutes of indoor recording with up to 3 fast moving objects simultaneously in the camera field of view. The objects and the camera are tracked by the VICON motion capture system. By 3D scanning the room and the objects, accurate depth map ground truth and pixel-wise object masks are obtained, which are reliable even in poor lighting conditions and during fast motion. We then train and evaluate our learning pipeline on EV-IMO and demonstrate that our approach far surpasses its rivals and is well suited for scene constrained robotics applications.
Unsupervised Learning of Dense Optical Flow, Depth and Egomotion from Sparse Event Data
Feb 25, 2019


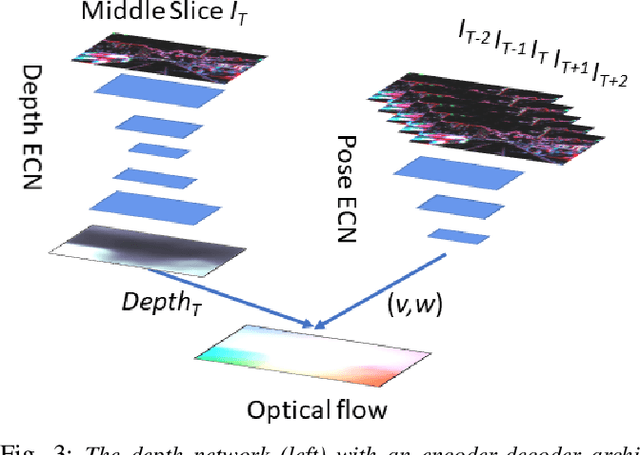
In this work we present a lightweight, unsupervised learning pipeline for \textit{dense} depth, optical flow and egomotion estimation from sparse event output of the Dynamic Vision Sensor (DVS). To tackle this low level vision task, we use a novel encoder-decoder neural network architecture - ECN. Our work is the first monocular pipeline that generates dense depth and optical flow from sparse event data only. The network works in self-supervised mode and has just 150k parameters. We evaluate our pipeline on the MVSEC self driving dataset and present results for depth, optical flow and and egomotion estimation. Due to the lightweight design, the inference part of the network runs at 250 FPS on a single GPU, making the pipeline ready for realtime robotics applications. Our experiments demonstrate significant improvements upon previous works that used deep learning on event data, as well as the ability of our pipeline to perform well during both day and night.
Evenly Cascaded Convolutional Networks
Jul 27, 2018


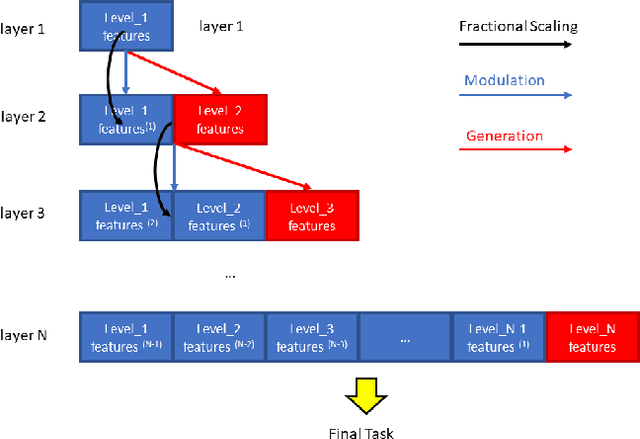
We introduce Evenly Cascaded convolutional Network (ECN), a neural network taking inspiration from the cascade algorithm of wavelet analysis. ECN employs two feature streams - a low-level and high-level steam. At each layer these streams interact, such that low-level features are modulated using advanced perspectives from the high-level stream. ECN is evenly structured through resizing feature map dimensions by a consistent ratio, which removes the burden of ad-hoc specification of feature map dimensions. ECN produces easily interpretable features maps, a result whose intuition can be understood in the context of scale-space theory. We demonstrate that ECN's design facilitates the training process through providing easily trainable shortcuts. We report new state-of-the-art results for small networks, without the need for additional treatment such as pruning or compression - a consequence of ECN's simple structure and direct training. A 6-layered ECN design with under 500k parameters achieves 95.24% and 78.99% accuracy on CIFAR-10 and CIFAR-100 datasets, respectively, outperforming the current state-of-the-art on small parameter networks, and a 3 million parameter ECN produces results competitive to the state-of-the-art.
On the Importance of Consistency in Training Deep Neural Networks
Aug 02, 2017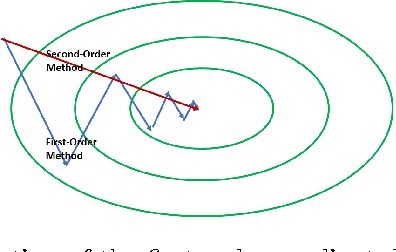


We explain that the difficulties of training deep neural networks come from a syndrome of three consistency issues. This paper describes our efforts in their analysis and treatment. The first issue is the training speed inconsistency in different layers. We propose to address it with an intuitive, simple-to-implement, low footprint second-order method. The second issue is the scale inconsistency between the layer inputs and the layer residuals. We explain how second-order information provides favorable convenience in removing this roadblock. The third and most challenging issue is the inconsistency in residual propagation. Based on the fundamental theorem of linear algebra, we provide a mathematical characterization of the famous vanishing gradient problem. Thus, an important design principle for future optimization and neural network design is derived. We conclude this paper with the construction of a novel contractive neural network.
Spectral Graph Cut from a Filtering Point of View
Nov 08, 2016


Spectral graph theory is well known and widely used in computer vision. In this paper, we analyze image segmentation algorithms that are based on spectral graph theory, e.g., normalized cut, and show that there is a natural connection between spectural graph theory based image segmentationand and edge preserving filtering. Based on this connection we show that the normalized cut algorithm is equivalent to repeated iterations of bilateral filtering. Then, using this equivalence we present and implement a fast normalized cut algorithm for image segmentation. Experiments show that our implementation can solve the original optimization problem in the normalized cut algorithm 10 to 100 times faster. Furthermore, we present a new algorithm called conditioned normalized cut for image segmentation that can easily incorporate color image patches and demonstrate how this segmentation problem can be solved with edge preserving filtering.
LightNet: A Versatile, Standalone Matlab-based Environment for Deep Learning
Aug 02, 2016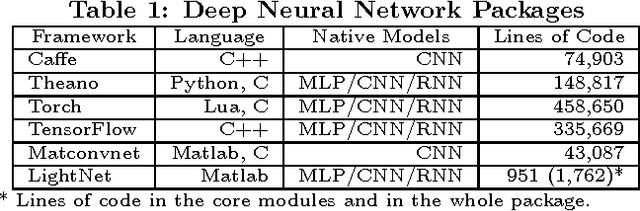

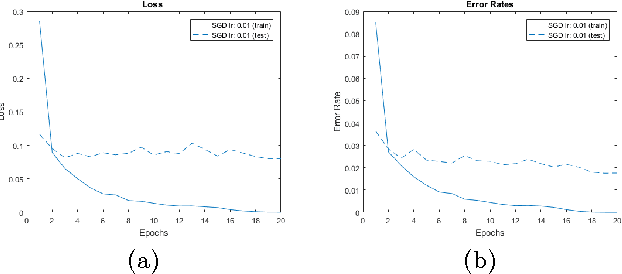
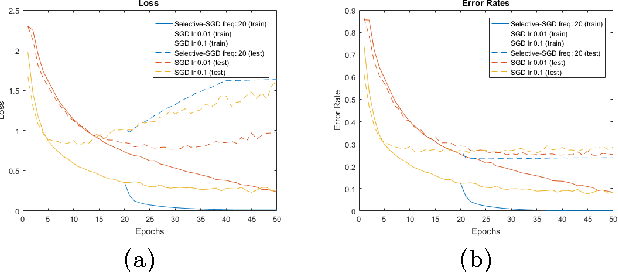
LightNet is a lightweight, versatile and purely Matlab-based deep learning framework. The idea underlying its design is to provide an easy-to-understand, easy-to-use and efficient computational platform for deep learning research. The implemented framework supports major deep learning architectures such as Multilayer Perceptron Networks (MLP), Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN). The framework also supports both CPU and GPU computation, and the switch between them is straightforward. Different applications in computer vision, natural language processing and robotics are demonstrated as experiments.