 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Natural Language to Planning Goals with Large-Language Models
Feb 10, 2023



Recent large language models (LLMs) have demonstrated remarkable performance on a variety of natural language processing (NLP) tasks, leading to intense excitement about their applicability across various domains. Unfortunately, recent work has also shown that LLMs are unable to perform accurate reasoning nor solve planning problems, which may limit their usefulness for robotics-related tasks. In this work, our central question is whether LLMs are able to translate goals specified in natural language to a structured planning language. If so, LLM can act as a natural interface between the planner and human users; the translated goal can be handed to domain-independent AI planners that are very effective at planning. Our empirical results on GPT 3.5 variants show that LLMs are much better suited towards translation rather than planning. We find that LLMs are able to leverage commonsense knowledge and reasoning to furnish missing details from under-specified goals (as is often the case in natural language). However, our experiments also reveal that LLMs can fail to generate goals in tasks that involve numerical or physical (e.g., spatial) reasoning, and that LLMs are sensitive to the prompts used. As such, these models are promising for translation to structured planning languages, but care should be taken in their use.
Multi-embodiment Legged Robot Control as a Sequence Modeling Problem
Dec 18, 2022



Robots are traditionally bounded by a fixed embodiment during their operational lifetime, which limits their ability to adapt to their surroundings. Co-optimizing control and morphology of a robot, however, is often inefficient due to the complex interplay between the controller and morphology. In this paper, we propose a learning-based control method that can inherently take morphology into consideration such that once the control policy is trained in the simulator, it can be easily deployed to robots with different embodiments in the real world. In particular, we present the Embodiment-aware Transformer (EAT), an architecture that casts this control problem as conditional sequence modeling. EAT outputs the optimal actions by leveraging a causally masked Transformer. By conditioning an autoregressive model on the desired robot embodiment, past states, and actions, our EAT model can generate future actions that best fit the current robot embodiment. Experimental results show that EAT can outperform all other alternatives in embodiment-varying tasks, and succeed in an example of real-world evolution tasks: stepping down a stair through updating the morphology alone. We hope that EAT will inspire a new push toward real-world evolution across many domains, where algorithms like EAT can blaze a trail by bridging the field of evolutionary robotics and big data sequence modeling.
Sim-to-Real Transfer for Quadrupedal Locomotion via Terrain Transformer
Dec 15, 2022Deep reinforcement learning has recently emerged as an appealing alternative for legged locomotion over multiple terrains by training a policy in physical simulation and then transferring it to the real world (i.e., sim-to-real transfer). Despite considerable progress, the capacity and scalability of traditional neural networks are still limited, which may hinder their applications in more complex environments. In contrast, the Transformer architecture has shown its superiority in a wide range of large-scale sequence modeling tasks, including natural language processing and decision-making problems. In this paper, we propose Terrain Transformer (TERT), a high-capacity Transformer model for quadrupedal locomotion control on various terrains. Furthermore, to better leverage Transformer in sim-to-real scenarios, we present a novel two-stage training framework consisting of an offline pretraining stage and an online correction stage, which can naturally integrate Transformer with privileged training. Extensive experiments in simulation demonstrate that TERT outperforms state-of-the-art baselines on different terrains in terms of return, energy consumption and control smoothness. In further real-world validation, TERT successfully traverses nine challenging terrains, including sand pit and stair down, which can not be accomplished by strong baselines.
Strictly Breadth-First AMR Parsing
Nov 08, 2022AMR parsing is the task that maps a sentence to an AMR semantic graph automatically. We focus on the breadth-first strategy of this task, which was proposed recently and achieved better performance than other strategies. However, current models under this strategy only \emph{encourage} the model to produce the AMR graph in breadth-first order, but \emph{cannot guarantee} this. To solve this problem, we propose a new architecture that \emph{guarantees} that the parsing will strictly follow the breadth-first order. In each parsing step, we introduce a \textbf{focused parent} vertex and use this vertex to guide the generation. With the help of this new architecture and some other improvements in the sentence and graph encoder, our model obtains better performance on both the AMR 1.0 and 2.0 dataset.
Compact and Robust Deep Learning Architecture for Fluorescence Lifetime Imaging and FPGA Implementation
Sep 09, 2022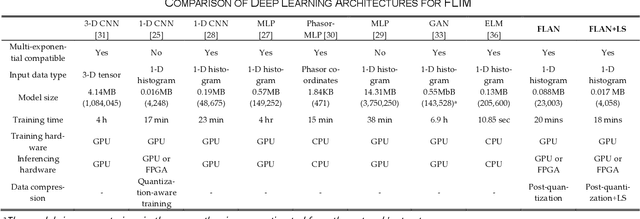
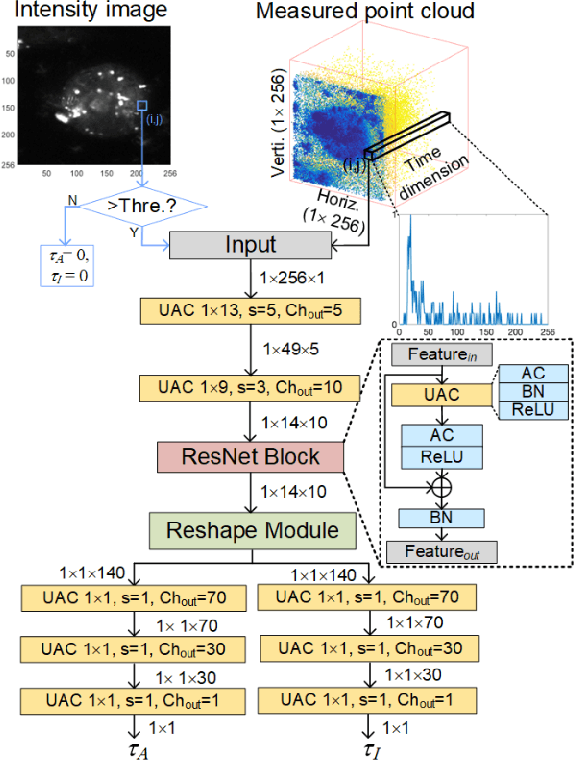
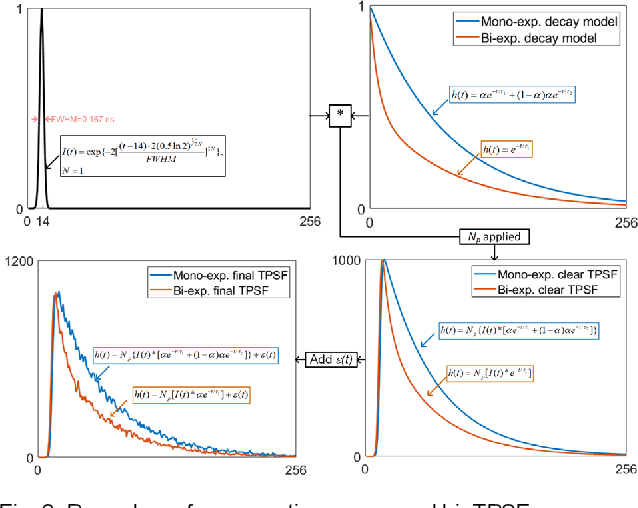
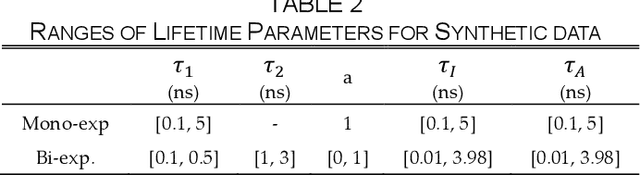
This paper reported a bespoke adder-based deep learning network for time-domain fluorescence lifetime imaging (FLIM). By leveraging the l1-norm extraction method, we propose a 1-D Fluorescence Lifetime AdderNet (FLAN) without multiplication-based convolutions to reduce the computational complexity. Further, we compressed fluorescence decays in temporal dimension using a log-scale merging technique to discard redundant temporal information derived as log-scaling FLAN (FLAN+LS). FLAN+LS achieves 0.11 and 0.23 compression ratios compared with FLAN and a conventional 1-D convolutional neural network (1-D CNN) while maintaining high accuracy in retrieving lifetimes. We extensively evaluated FLAN and FLAN+LS using synthetic and real data. A traditional fitting method and other non-fitting, high-accuracy algorithms were compared with our networks for synthetic data. Our networks attained a minor reconstruction error in different photon-count scenarios. For real data, we used fluorescent beads' data acquired by a confocal microscope to validate the effectiveness of real fluorophores, and our networks can differentiate beads with different lifetimes. Additionally, we implemented the network architecture on a field-programmable gate array (FPGA) with a post-quantization technique to shorten the bit-width, thereby improving computing efficiency. FLAN+LS on hardware achieves the highest computing efficiency compared to 1-D CNN and FLAN. We also discussed the applicability of our network and hardware architecture for other time-resolved biomedical applications using photon-efficient, time-resolved sensors.
Action Recognition based on Cross-Situational Action-object Statistics
Aug 15, 2022

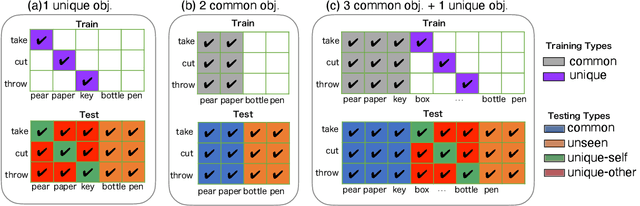
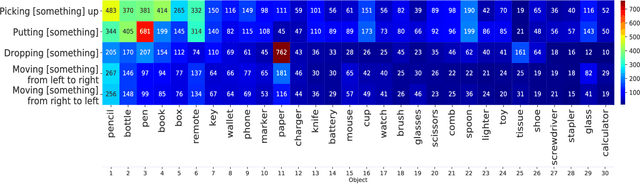
Machine learning models of visual action recognition are typically trained and tested on data from specific situations where actions are associated with certain objects. It is an open question how action-object associations in the training set influence a model's ability to generalize beyond trained situations. We set out to identify properties of training data that lead to action recognition models with greater generalization ability. To do this, we take inspiration from a cognitive mechanism called cross-situational learning, which states that human learners extract the meaning of concepts by observing instances of the same concept across different situations. We perform controlled experiments with various types of action-object associations, and identify key properties of action-object co-occurrence in training data that lead to better classifiers. Given that these properties are missing in the datasets that are typically used to train action classifiers in the computer vision literature, our work provides useful insights on how we should best construct datasets for efficiently training for better generalization.
OmniWheg: An Omnidirectional Wheel-Leg Transformable Robot
Mar 04, 2022
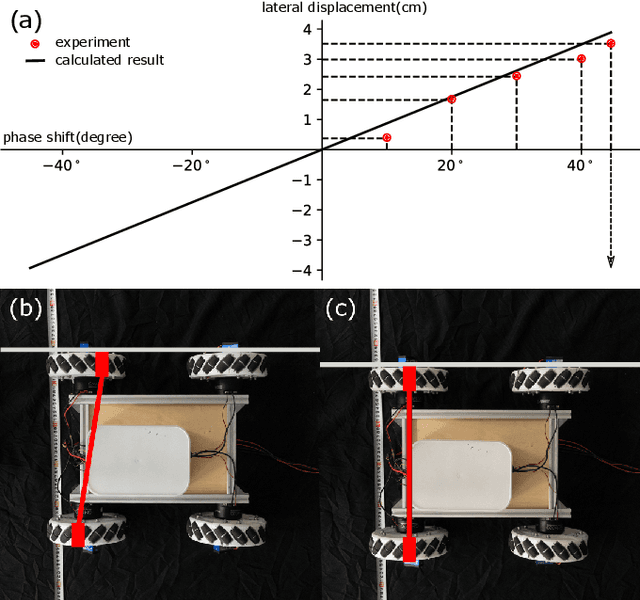
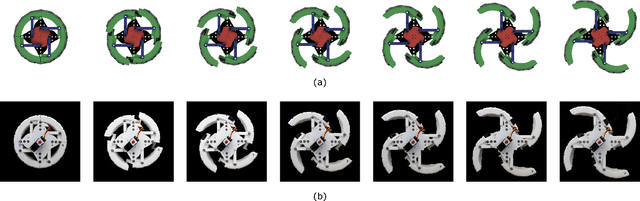
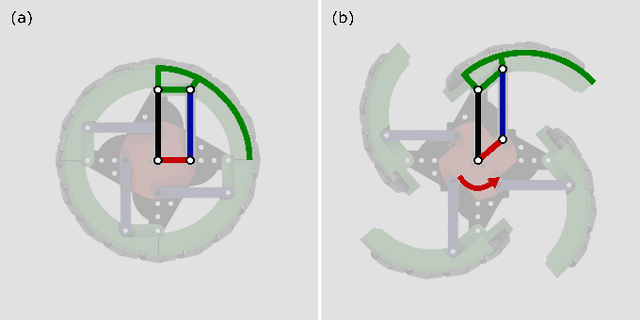
This paper presents the design, analysis, and performance evaluation of an omnidirectional transformable wheel-leg robot called OmniWheg. We design a novel mechanism consisting of a separable Omni-wheel and 4-bar linkages, allowing the robot to transform between Omni-wheeled and legged modes smoothly. On wheeled mode, the robot can move in all directions and efficiently adjust the relative position of its wheels, while it can overcome common obstacles in legged mode, such as stairs and steps. Unlike other articles studying whegs, this implementation with omnidirectional wheels allows the correction of misalignments between right and left wheels before traversing obstacles, which effectively improves the success rate and simplifies the preparation process before the wheel-leg transformation. We describe the design concept, mechanism, and the dynamic characteristic of the wheel-leg structure. We then evaluate its performance in various scenarios, including passing obstacles, climbing steps of different heights, and turning/moving omnidirectionally. Our results confirm that this mobile platform can overcome common indoor obstacles and move flexibly on the flat ground with the new transformable wheel-leg mechanism, while keeping a high degree of stability.
Multi-Modal Legged Locomotion Framework with Automated Residual Reinforcement Learning
Feb 24, 2022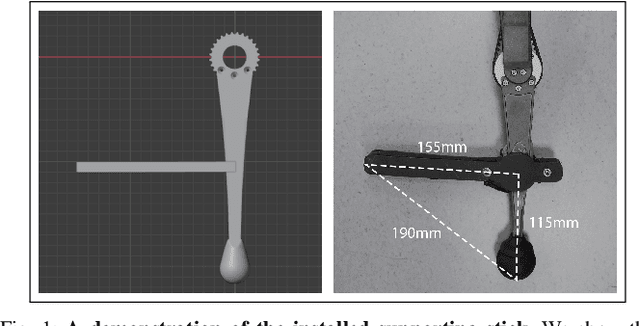

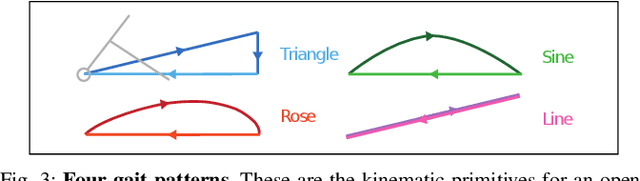

While quadruped robots usually have good stability and load capacity, bipedal robots offer a higher level of flexibility / adaptability to different tasks and environments. A multi-modal legged robot can take the best of both worlds. In this paper, we propose a multi-modal locomotion framework that is composed of a hand-crafted transition motion and a learning-based bipedal controller -- learnt by a novel algorithm called Automated Residual Reinforcement Learning. This framework aims to endow arbitrary quadruped robots with the ability to walk bipedally. In particular, we 1) design an additional supporting structure for a quadruped robot and a sequential multi-modal transition strategy; 2) propose a novel class of Reinforcement Learning algorithms for bipedal control and evaluate their performances in both simulation and the real world. Experimental results show that our proposed algorithms have the best performance in simulation and maintain a good performance in a real-world robot. Overall, our multi-modal robot could successfully switch between biped and quadruped, and walk in both modes. Experiment videos and code are available at https://chenaah.github.io/multimodal/.
Clairvoyance: Intelligent Route Planning for Electric Buses Based on Urban Big Data
Dec 09, 2021Nowadays many cities around the world have introduced electric buses to optimize urban traffic and reduce local carbon emissions. In order to cut carbon emissions and maximize the utility of electric buses, it is important to choose suitable routes for them. Traditionally, route selection is on the basis of dedicated surveys, which are costly in time and labor. In this paper, we mainly focus attention on planning electric bus routes intelligently, depending on the unique needs of each region throughout the city. We propose Clairvoyance, a route planning system that leverages a deep neural network and a multilayer perceptron to predict the future people's trips and the future transportation carbon emission in the whole city, respectively. Given the future information of people's trips and transportation carbon emission, we utilize a greedy mechanism to recommend bus routes for electric buses that will depart in an ideal state. Furthermore, representative features of the two neural networks are extracted from the heterogeneous urban datasets. We evaluate our approach through extensive experiments on real-world data sources in Zhuhai, China. The results show that our designed neural network-based algorithms are consistently superior to the typical baselines. Additionally, the recommended routes for electric buses are helpful in reducing the peak value of carbon emissions and making full use of electric buses in the city.
Rearranging the Environment to Maximize Energy with a Robotic Circuit Drawing
Nov 15, 2021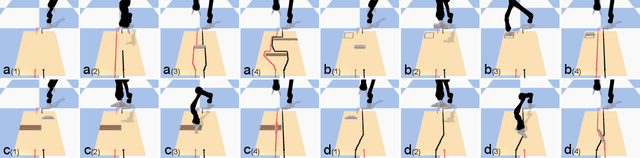
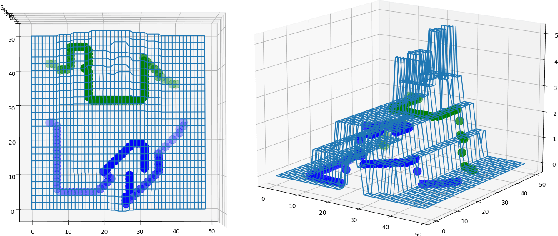

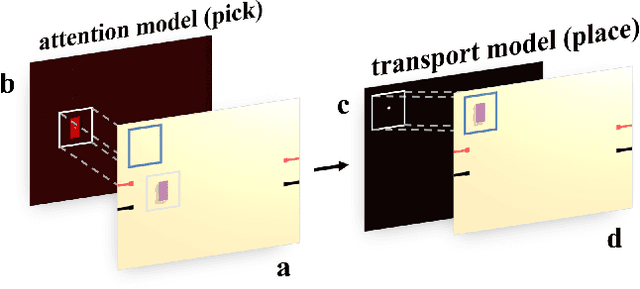
Robots with the ability to actively acquire power from surroundings will be greatly beneficial for long-term autonomy and to survive in uncertain environments. In this work, we present a robot capable of drawing circuits with conductive ink while also rearranging the visual world to receive maximum energy from a power source. A range of circuit drawing tasks is designed to simulate real-world scenarios, including avoiding physical obstacles and regions that would discontinue drawn circuits. We adopt the state-of-the-art Transporter networks for pick-and-place manipulation from visual observation. We conduct experiments in both simulation and real-world settings, and our results show that, with a small number of demonstrations, the robot learns to rearrange the placement of objects (removing obstacles and bridging areas unsuitable for drawing) and to connect a power source with a minimum amount of conductive ink. As autonomous robots become more present, in our houses and other planets, our proposed method brings a novel way for machines to keep themselves functional by rearranging their surroundings to create their own electric circuits.