 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS4: Generalizable Sparse Splatting Semantic SLAM
Jun 06, 2025Traditional SLAM algorithms are excellent at camera tracking but might generate lower resolution and incomplete 3D maps. Recently, Gaussian Splatting (GS) approaches have emerged as an option for SLAM with accurate, dense 3D map building. However, existing GS-based SLAM methods rely on per-scene optimization which is time-consuming and does not generalize to diverse scenes well. In this work, we introduce the first generalizable GS-based semantic SLAM algorithm that incrementally builds and updates a 3D scene representation from an RGB-D video stream using a learned generalizable network. Our approach starts from an RGB-D image recognition backbone to predict the Gaussian parameters from every downsampled and backprojected image location. Additionally, we seamlessly integrate 3D semantic segmentation into our GS framework, bridging 3D mapping and recognition through a shared backbone. To correct localization drifting and floaters, we propose to optimize the GS for only 1 iteration following global localization. We demonstrate state-of-the-art semantic SLAM performance on the real-world benchmark ScanNet with an order of magnitude fewer Gaussians compared to other recent GS-based methods, and showcase our model's generalization capability through zero-shot transfer to the NYUv2 and TUM RGB-D datasets.
Long-Term 3D Point Tracking By Cost Volume Fusion
Jul 18, 2024



Long-term point tracking is essential to understand non-rigid motion in the physical world better. Deep learning approaches have recently been incorporated into long-term point tracking, but most prior work predominantly functions in 2D. Although these methods benefit from the well-established backbones and matching frameworks, the motions they produce do not always make sense in the 3D physical world. In this paper, we propose the first deep learning framework for long-term point tracking in 3D that generalizes to new points and videos without requiring test-time fine-tuning. Our model contains a cost volume fusion module that effectively integrates multiple past appearances and motion information via a transformer architecture, significantly enhancing overall tracking performance. In terms of 3D tracking performance, our model significantly outperforms simple scene flow chaining and previous 2D point tracking methods, even if one uses ground truth depth and camera pose to backproject 2D point tracks in a synthetic scenario.
Point Cloud Models Improve Visual Robustness in Robotic Learners
Apr 29, 2024



Visual control policies can encounter significant performance degradation when visual conditions like lighting or camera position differ from those seen during training -- often exhibiting sharp declines in capability even for minor differences. In this work, we examine robustness to a suite of these types of visual changes for RGB-D and point cloud based visual control policies. To perform these experiments on both model-free and model-based reinforcement learners, we introduce a novel Point Cloud World Model (PCWM) and point cloud based control policies. Our experiments show that policies that explicitly encode point clouds are significantly more robust than their RGB-D counterparts. Further, we find our proposed PCWM significantly outperforms prior works in terms of sample efficiency during training. Taken together, these results suggest reasoning about the 3D scene through point clouds can improve performance, reduce learning time, and increase robustness for robotic learners. Project Webpage: https://pvskand.github.io/projects/PCWM
Object Dynamics Modeling with Hierarchical Point Cloud-based Representations
Apr 09, 2024



Modeling object dynamics with a neural network is an important problem with numerous applications. Most recent work has been based on graph neural networks. However, physics happens in 3D space, where geometric information potentially plays an important role in modeling physical phenomena. In this work, we propose a novel U-net architecture based on continuous point convolution which naturally embeds information from 3D coordinates and allows for multi-scale feature representations with established downsampling and upsampling procedures. Bottleneck layers in the downsampled point clouds lead to better long-range interaction modeling. Besides, the flexibility of point convolutions allows our approach to generalize to sparsely sampled points from mesh vertices and dynamically generate features on important interaction points on mesh faces. Experimental results demonstrate that our approach significantly improves the state-of-the-art, especially in scenarios that require accurate gravity or collision reasoning.
Out of Sight, Still in Mind: Reasoning and Planning about Unobserved Objects with Video Tracking Enabled Memory Models
Sep 26, 2023



Robots need to have a memory of previously observed, but currently occluded objects to work reliably in realistic environments. We investigate the problem of encoding object-oriented memory into a multi-object manipulation reasoning and planning framework. We propose DOOM and LOOM, which leverage transformer relational dynamics to encode the history of trajectories given partial-view point clouds and an object discovery and tracking engine. Our approaches can perform multiple challenging tasks including reasoning with occluded objects, novel objects appearance, and object reappearance. Throughout our extensive simulation and real-world experiments, we find that our approaches perform well in terms of different numbers of objects and different numbers of distractor actions. Furthermore, we show our approaches outperform an implicit memory baseline.
Learning Vision-Based Bipedal Locomotion for Challenging Terrain
Sep 26, 2023Reinforcement learning (RL) for bipedal locomotion has recently demonstrated robust gaits over moderate terrains using only proprioceptive sensing. However, such blind controllers will fail in environments where robots must anticipate and adapt to local terrain, which requires visual perception. In this paper, we propose a fully-learned system that allows bipedal robots to react to local terrain while maintaining commanded travel speed and direction. Our approach first trains a controller in simulation using a heightmap expressed in the robot's local frame. Next, data is collected in simulation to train a heightmap predictor, whose input is the history of depth images and robot states. We demonstrate that with appropriate domain randomization, this approach allows for successful sim-to-real transfer with no explicit pose estimation and no fine-tuning using real-world data. To the best of our knowledge, this is the first example of sim-to-real learning for vision-based bipedal locomotion over challenging terrains.
Maximal Cliques on Multi-Frame Proposal Graph for Unsupervised Video Object Segmentation
Jan 29, 2023



Unsupervised Video Object Segmentation (UVOS) aims at discovering objects and tracking them through videos. For accurate UVOS, we observe if one can locate precise segment proposals on key frames, subsequent processes are much simpler. Hence, we propose to reason about key frame proposals using a graph built with the object probability masks initially generated from multiple frames around the key frame and then propagated to the key frame. On this graph, we compute maximal cliques, with each clique representing one candidate object. By making multiple proposals in the clique to vote for the key frame proposal, we obtain refined key frame proposals that could be better than any of the single-frame proposals. A semi-supervised VOS algorithm subsequently tracks these key frame proposals to the entire video. Our algorithm is modular and hence can be used with any instance segmentation and semi-supervised VOS algorithm. We achieve state-of-the-art performance on the DAVIS-2017 validation and test-dev dataset. On the related problem of video instance segmentation, our method shows competitive performance with the previous best algorithm that requires joint training with the VOS algorithm.
Discriminative Appearance Modeling with Multi-track Pooling for Real-time Multi-object Tracking
Jan 28, 2021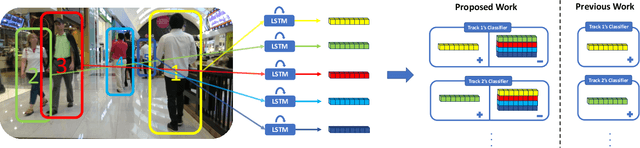

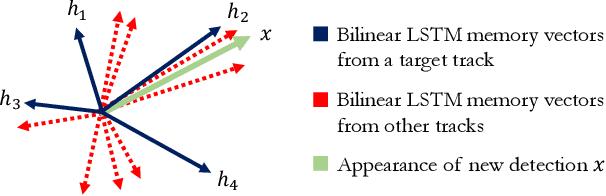

In multi-object tracking, the tracker maintains in its memory the appearance and motion information for each object in the scene. This memory is utilized for finding matches between tracks and detections and is updated based on the matching result. Many approaches model each target in isolation and lack the ability to use all the targets in the scene to jointly update the memory. This can be problematic when there are similar looking objects in the scene. In this paper, we solve the problem of simultaneously considering all tracks during memory updating, with only a small spatial overhead, via a novel multi-track pooling module. We additionally propose a training strategy adapted to multi-track pooling which generates hard tracking episodes online. We show that the combination of these innovations results in a strong discriminative appearance model, enabling the use of greedy data association to achieve online tracking performance. Our experiments demonstrate real-time, state-of-the-art performance on public multi-object tracking (MOT) datasets.
2018 Robotic Scene Segmentation Challenge
Feb 03, 2020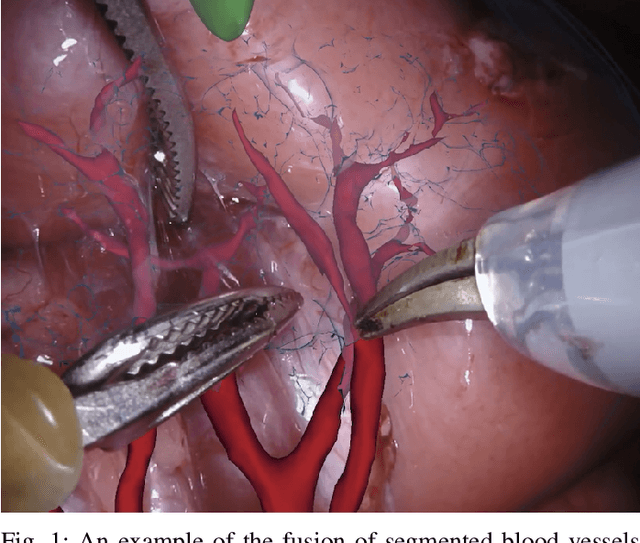
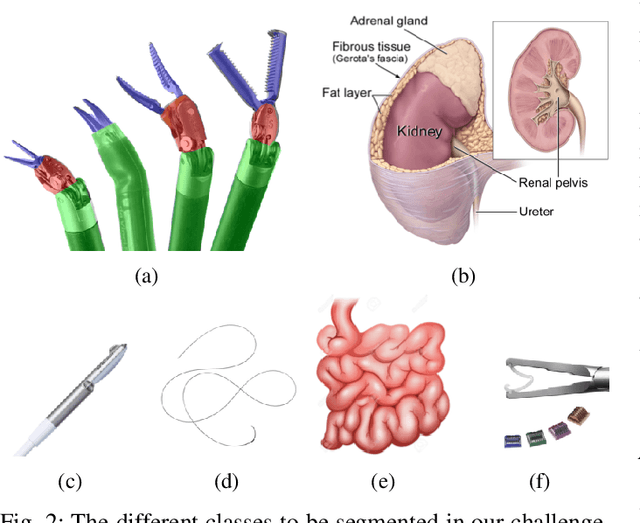
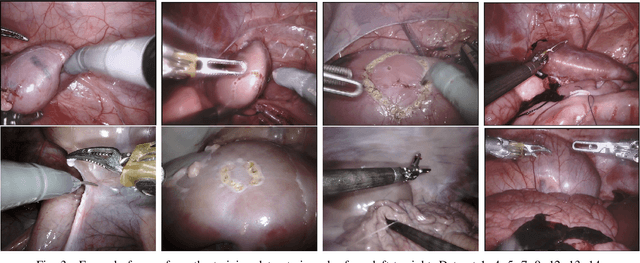
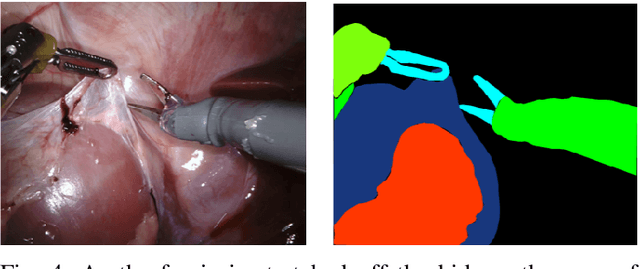
In 2015 we began a sub-challenge at the EndoVis workshop at MICCAI in Munich using endoscope images of ex-vivo tissue with automatically generated annotations from robot forward kinematics and instrument CAD models. However, the limited background variation and simple motion rendered the dataset uninformative in learning about which techniques would be suitable for segmentation in real surgery. In 2017, at the same workshop in Quebec we introduced the robotic instrument segmentation dataset with 10 teams participating in the challenge to perform binary, articulating parts and type segmentation of da Vinci instruments. This challenge included realistic instrument motion and more complex porcine tissue as background and was widely addressed with modifications on U-Nets and other popular CNN architectures. In 2018 we added to the complexity by introducing a set of anatomical objects and medical devices to the segmented classes. To avoid over-complicating the challenge, we continued with porcine data which is dramatically simpler than human tissue due to the lack of fatty tissue occluding many organs.