 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveillance Video Parsing with Single Frame Supervision
Nov 29, 2016
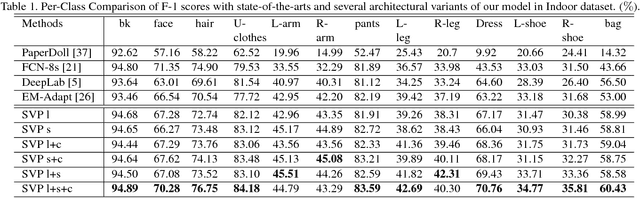
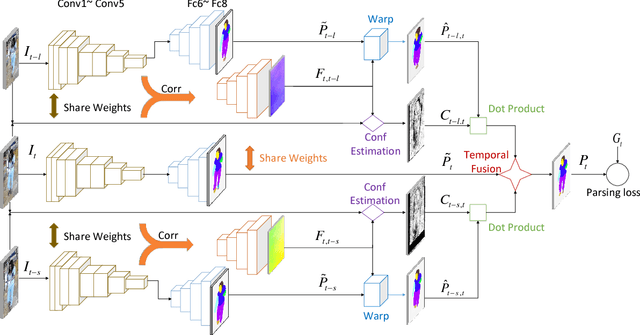
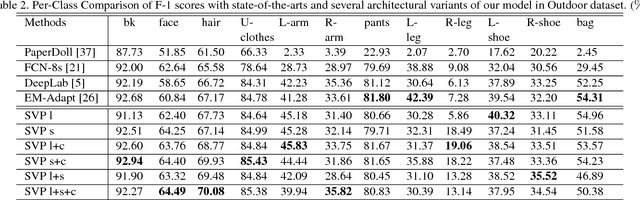
Surveillance video parsing, which segments the video frames into several labels, e.g., face, pants, left-leg, has wide applications. However,pixel-wisely annotating all frames is tedious and inefficient. In this paper, we develop a Single frame Video Parsing (SVP) method which requires only one labeled frame per video in training stage. To parse one particular frame, the video segment preceding the frame is jointly considered. SVP (1) roughly parses the frames within the video segment, (2) estimates the optical flow between frames and (3) fuses the rough parsing results warped by optical flow to produce the refined parsing result. The three components of SVP, namely frame parsing, optical flow estimation and temporal fusion are integrated in an end-to-end manner. Experimental results on two surveillance video datasets show the superiority of SVP over state-of-the-arts.
Network Morphism
Mar 08, 2016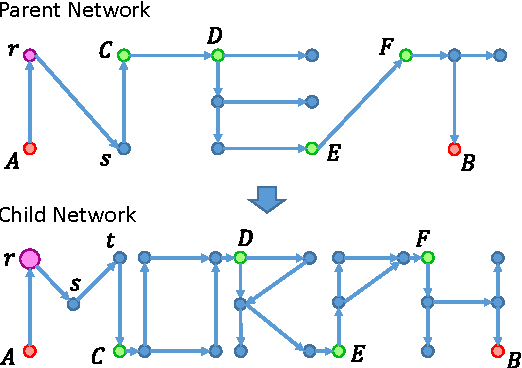
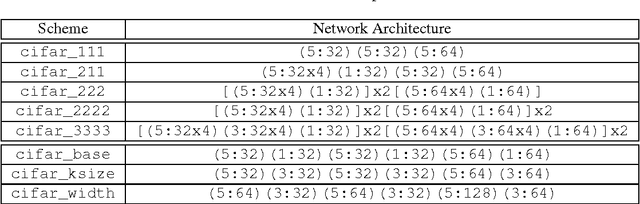
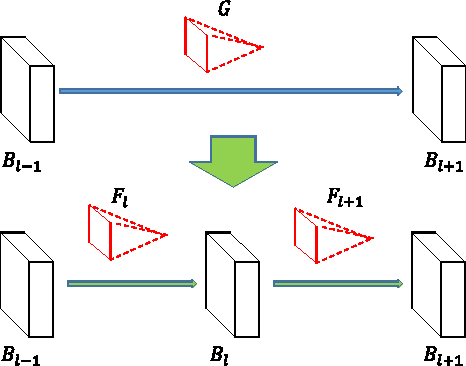

We present in this paper a systematic study on how to morph a well-trained neural network to a new one so that its network function can be completely preserved. We define this as \emph{network morphism} in this research. After morphing a parent network, the child network is expected to inherit the knowledge from its parent network and also has the potential to continue growing into a more powerful one with much shortened training time. The first requirement for this network morphism is its ability to handle diverse morphing types of networks, including changes of depth, width, kernel size, and even subnet. To meet this requirement, we first introduce the network morphism equations, and then develop novel morphing algorithms for all these morphing types for both classic and convolutional neural networks. The second requirement for this network morphism is its ability to deal with non-linearity in a network. We propose a family of parametric-activation functions to facilitate the morphing of any continuous non-linear activation neurons. Experimental results on benchmark datasets and typical neural networks demonstrate the effectiveness of the proposed network morphism scheme.