 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurveillance Video Parsing with Single Frame Supervision
Paper and Code
Nov 29, 2016
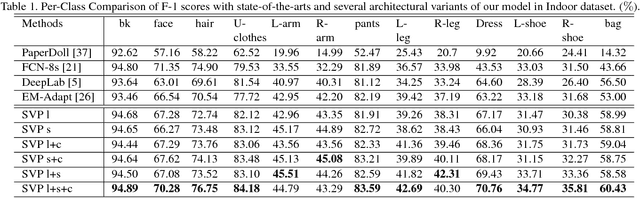
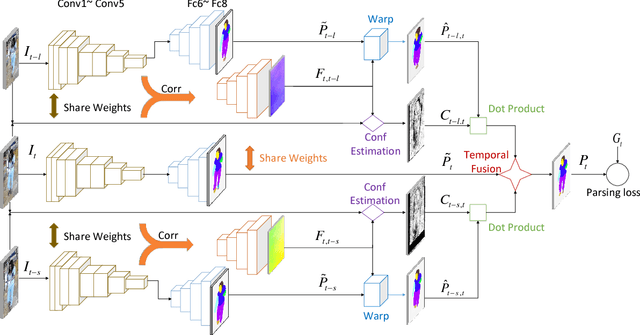
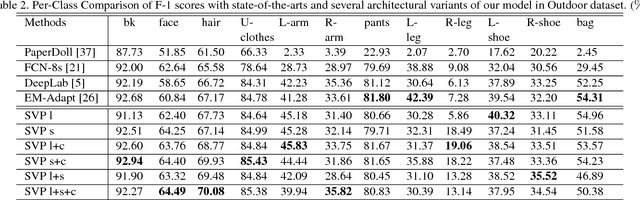
Surveillance video parsing, which segments the video frames into several labels, e.g., face, pants, left-leg, has wide applications. However,pixel-wisely annotating all frames is tedious and inefficient. In this paper, we develop a Single frame Video Parsing (SVP) method which requires only one labeled frame per video in training stage. To parse one particular frame, the video segment preceding the frame is jointly considered. SVP (1) roughly parses the frames within the video segment, (2) estimates the optical flow between frames and (3) fuses the rough parsing results warped by optical flow to produce the refined parsing result. The three components of SVP, namely frame parsing, optical flow estimation and temporal fusion are integrated in an end-to-end manner. Experimental results on two surveillance video datasets show the superiority of SVP over state-of-the-arts.