 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTF-GNN: Graph Neural Networks in TensorFlow
Jul 07, 2022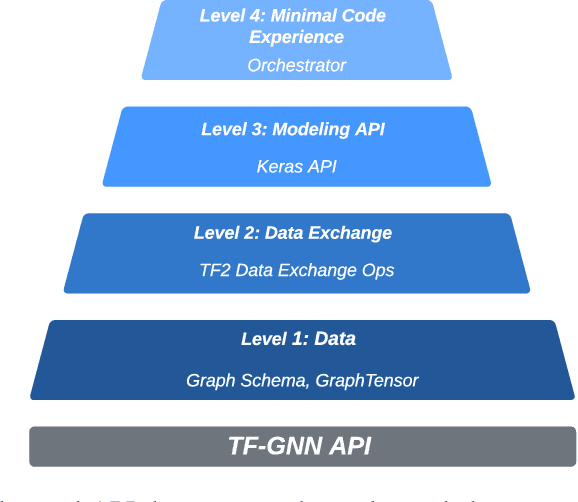
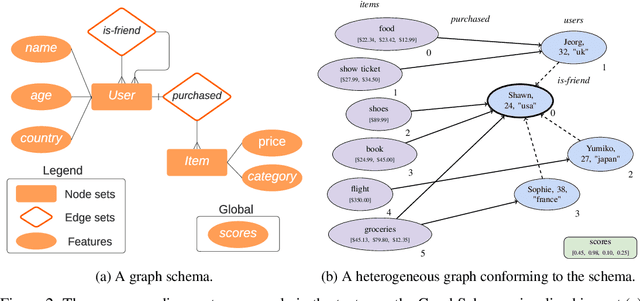
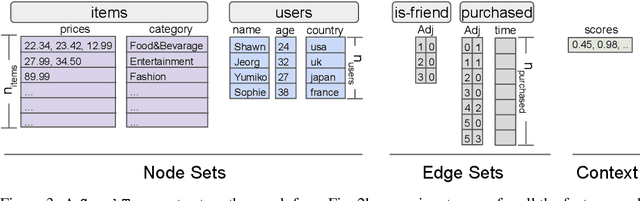
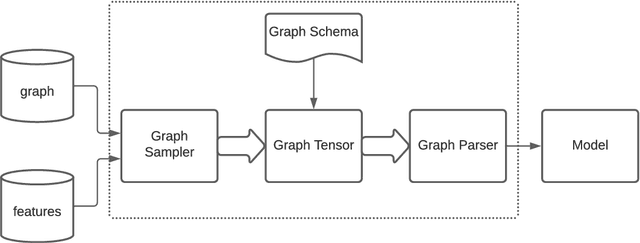
TensorFlow GNN (TF-GNN) is a scalable library for Graph Neural Networks in TensorFlow. It is designed from the bottom up to support the kinds of rich heterogeneous graph data that occurs in today's information ecosystems. Many production models at Google use TF-GNN and it has been recently released as an open source project. In this paper, we describe the TF-GNN data model, its Keras modeling API, and relevant capabilities such as graph sampling, distributed training, and accelerator support.
Tackling Provably Hard Representative Selection via Graph Neural Networks
May 20, 2022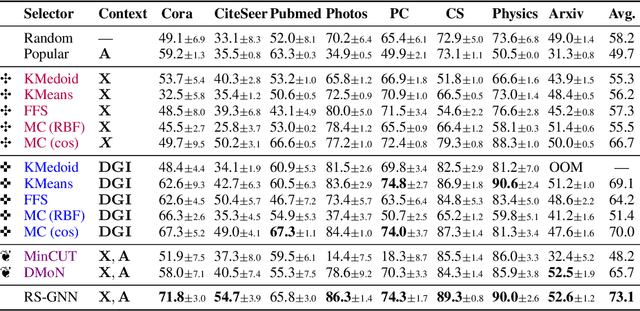
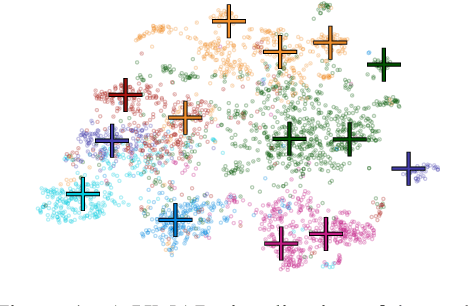
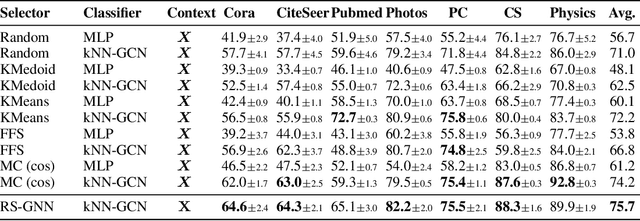
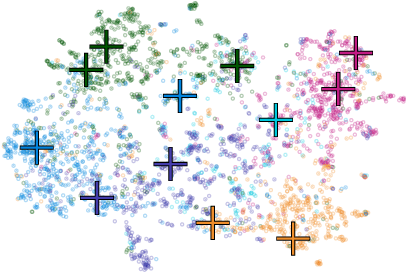
Representative selection (RS) is the problem of finding a small subset of exemplars from an unlabeled dataset, and has numerous applications in summarization, active learning, data compression and many other domains. In this paper, we focus on finding representatives that optimize the accuracy of a model trained on the selected representatives. We study RS for data represented as attributed graphs. We develop RS-GNN, a representation learning-based RS model based on Graph Neural Networks. Empirically, we demonstrate the effectiveness of RS-GNN on problems with predefined graph structures as well as problems with graphs induced from node feature similarities, by showing that RS-GNN achieves significant improvements over established baselines that optimize surrogate functions. Theoretically, we establish a new hardness result for RS by proving that RS is hard to approximate in polynomial time within any reasonable factor, which implies a significant gap between the optimum solution of widely-used surrogate functions and the actual accuracy of the model, and provides justification for the superiority of representation learning-based approaches such as RS-GNN over surrogate functions.
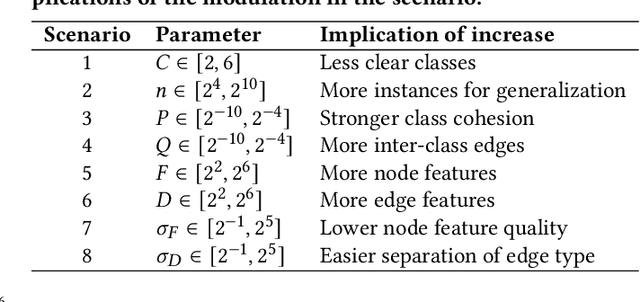
Synthetic Graph Generation to Benchmark Graph Learning
Apr 04, 2022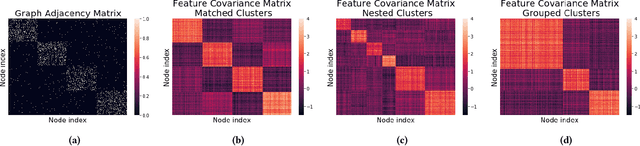
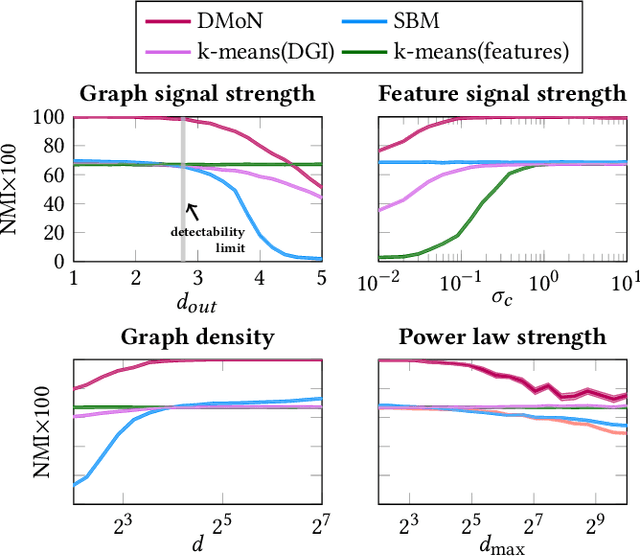
Graph learning algorithms have attained state-of-the-art performance on many graph analysis tasks such as node classification, link prediction, and clustering. It has, however, become hard to track the field's burgeoning progress. One reason is due to the very small number of datasets used in practice to benchmark the performance of graph learning algorithms. This shockingly small sample size (~10) allows for only limited scientific insight into the problem. In this work, we aim to address this deficiency. We propose to generate synthetic graphs, and study the behaviour of graph learning algorithms in a controlled scenario. We develop a fully-featured synthetic graph generator that allows deep inspection of different models. We argue that synthetic graph generations allows for thorough investigation of algorithms and provides more insights than overfitting on three citation datasets. In the case study, we show how our framework provides insight into unsupervised and supervised graph neural network models.
Zero-shot Domain Adaptation of Heterogeneous Graphs via Knowledge Transfer Networks
Mar 03, 2022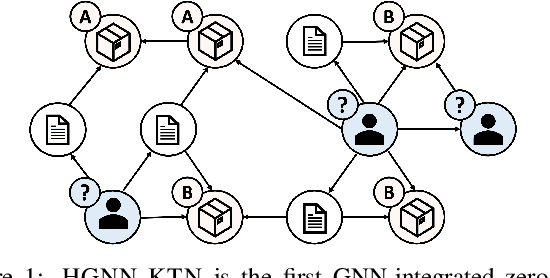
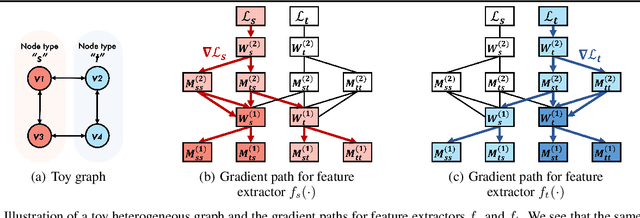
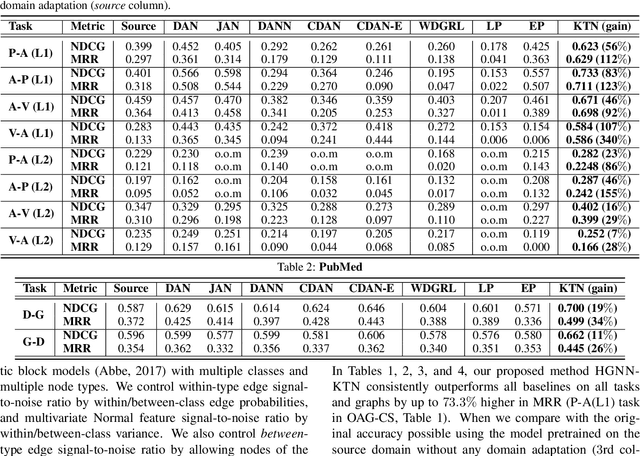
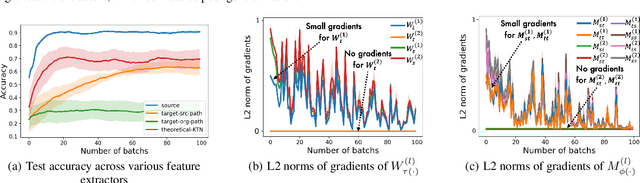
How can we make predictions for nodes in a heterogeneous graph when an entire type of node (e.g. user) has no labels (perhaps due to privacy issues) at all? Although heterogeneous graph neural networks (HGNNs) have shown superior performance as powerful representation learning techniques, there is no direct way to learn using labels rooted at different node types. Domain adaptation (DA) targets this setting, however, existing DA can not be applied directly to HGNNs. In heterogeneous graphs, the source and target domains have different modalities, thus HGNNs provide different feature extractors to them, while most of DA assumes source and target domains share a common feature extractor. In this work, we address the issue of zero-shot domain adaptation in HGNNs. We first theoretically induce a relationship between source and target domain features extracted from HGNNs, then propose a novel domain adaptation method, Knowledge Transfer Networks for HGNNs (HGNN-KTN). HGNN-KTN learns the relationship between source and target features, then maps the target distributions into the source domain. HGNN-KTN outperforms state-of-the-art baselines, showing up to 73.3% higher in MRR on 18 different domain adaptation tasks running on real-world benchmark graphs.
GraphWorld: Fake Graphs Bring Real Insights for GNNs
Feb 28, 2022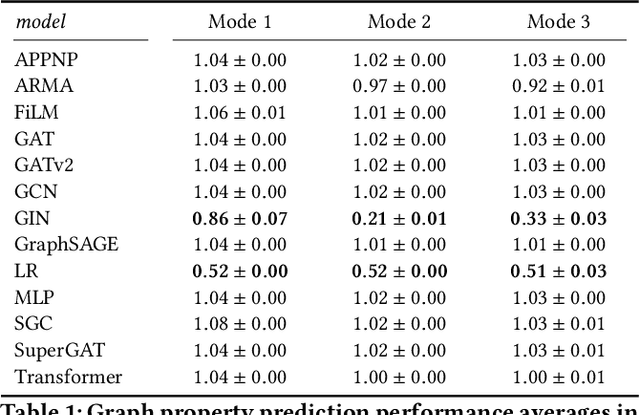
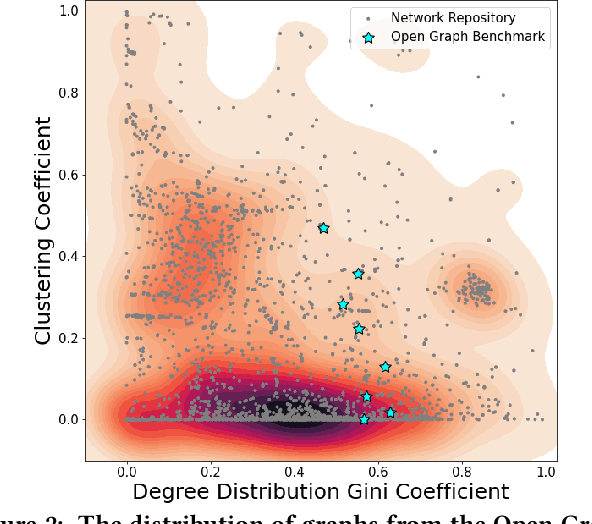
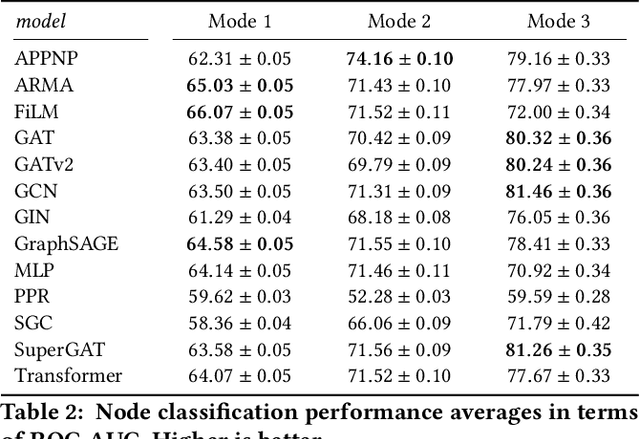
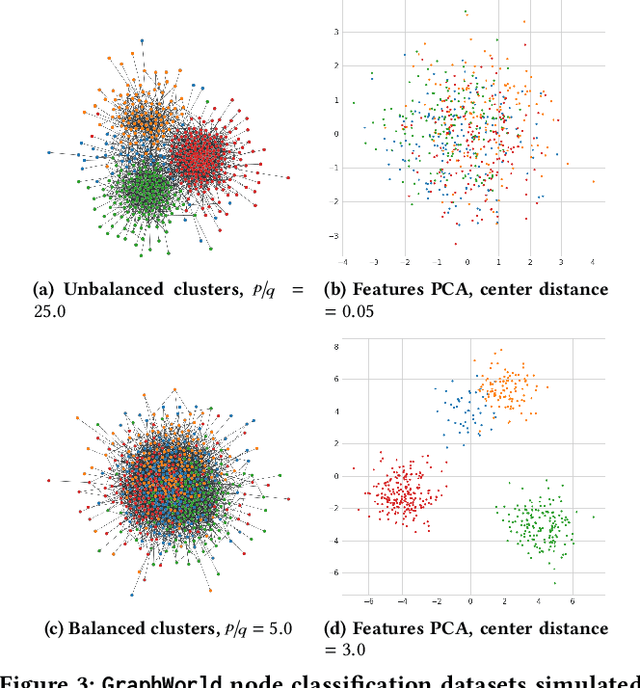
Despite advances in the field of Graph Neural Networks (GNNs), only a small number (~5) of datasets are currently used to evaluate new models. This continued reliance on a handful of datasets provides minimal insight into the performance differences between models, and is especially challenging for industrial practitioners who are likely to have datasets which look very different from those used as academic benchmarks. In the course of our work on GNN infrastructure and open-source software at Google, we have sought to develop improved benchmarks that are robust, tunable, scalable,and generalizable. In this work we introduce GraphWorld, a novel methodology and system for benchmarking GNN models on an arbitrarily-large population of synthetic graphs for any conceivable GNN task. GraphWorld allows a user to efficiently generate a world with millions of statistically diverse datasets. It is accessible, scalable, and easy to use. GraphWorld can be run on a single machine without specialized hardware, or it can be easily scaled up to run on arbitrary clusters or cloud frameworks. Using GraphWorld, a user has fine-grained control over graph generator parameters, and can benchmark arbitrary GNN models with built-in hyperparameter tuning. We present insights from GraphWorld experiments regarding the performance characteristics of tens of thousands of GNN models over millions of benchmark datasets. We further show that GraphWorld efficiently explores regions of benchmark dataset space uncovered by standard benchmarks, revealing comparisons between models that have not been historically obtainable. Using GraphWorld, we also are able to study in-detail the relationship between graph properties and task performance metrics, which is nearly impossible with the classic collection of real-world benchmarks.
Shift-Robust GNNs: Overcoming the Limitations of Localized Graph Training data
Aug 02, 2021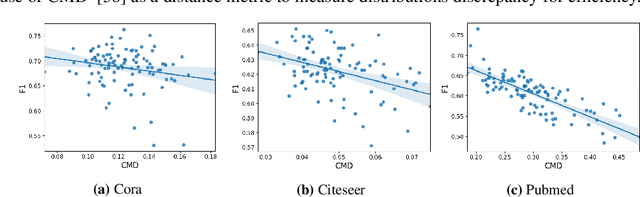
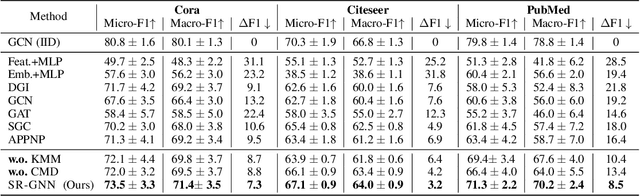
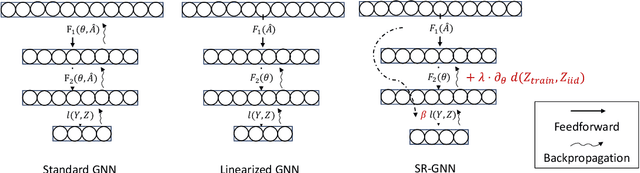
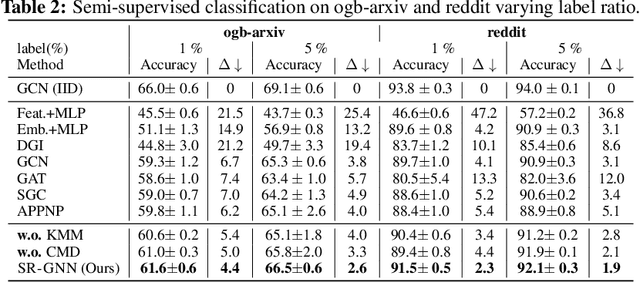
There has been a recent surge of interest in designing Graph Neural Networks (GNNs) for semi-supervised learning tasks. Unfortunately this work has assumed that the nodes labeled for use in training were selected uniformly at random (i.e. are an IID sample). However in many real world scenarios gathering labels for graph nodes is both expensive and inherently biased -- so this assumption can not be met. GNNs can suffer poor generalization when this occurs, by overfitting to superfluous regularities present in the training data. In this work we present a method, Shift-Robust GNN (SR-GNN), designed to account for distributional differences between biased training data and the graph's true inference distribution. SR-GNN adapts GNN models for the presence of distributional shifts between the nodes which have had labels provided for training and the rest of the dataset. We illustrate the effectiveness of SR-GNN in a variety of experiments with biased training datasets on common GNN benchmark datasets for semi-supervised learning, where we see that SR-GNN outperforms other GNN baselines by accuracy, eliminating at least (~40%) of the negative effects introduced by biased training data. On the largest dataset we consider, ogb-arxiv, we observe an 2% absolute improvement over the baseline and reduce 30% of the negative effects.
Graph Traversal with Tensor Functionals: A Meta-Algorithm for Scalable Learning
Feb 08, 2021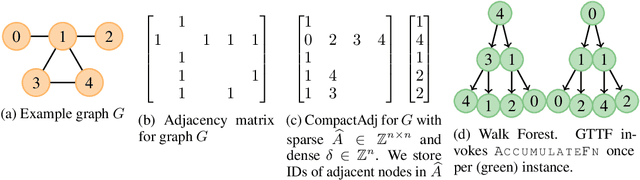


Graph Representation Learning (GRL) methods have impacted fields from chemistry to social science. However, their algorithmic implementations are specialized to specific use-cases e.g.message passing methods are run differently from node embedding ones. Despite their apparent differences, all these methods utilize the graph structure, and therefore, their learning can be approximated with stochastic graph traversals. We propose Graph Traversal via Tensor Functionals(GTTF), a unifying meta-algorithm framework for easing the implementation of diverse graph algorithms and enabling transparent and efficient scaling to large graphs. GTTF is founded upon a data structure (stored as a sparse tensor) and a stochastic graph traversal algorithm (described using tensor operations). The algorithm is a functional that accept two functions, and can be specialized to obtain a variety of GRL models and objectives, simply by changing those two functions. We show for a wide class of methods, our algorithm learns in an unbiased fashion and, in expectation, approximates the learning as if the specialized implementations were run directly. With these capabilities, we scale otherwise non-scalable methods to set state-of-the-art on large graph datasets while being more efficient than existing GRL libraries - with only a handful of lines of code for each method specialization. GTTF and its various GRL implementations are on: https://github.com/isi-usc-edu/gttf.
Pathfinder Discovery Networks for Neural Message Passing
Oct 24, 2020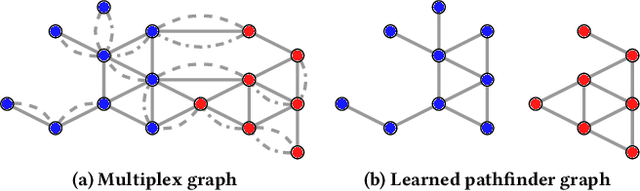
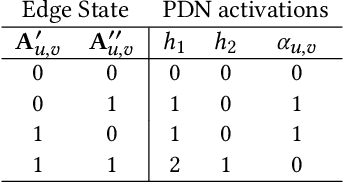
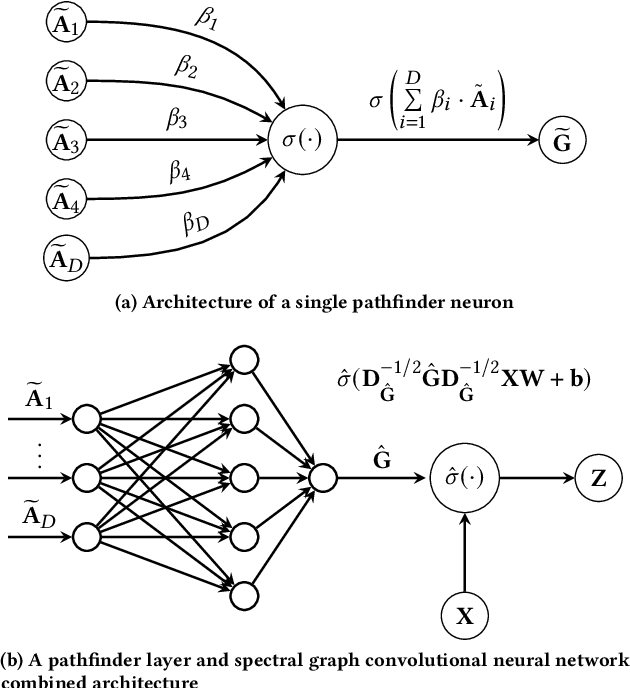
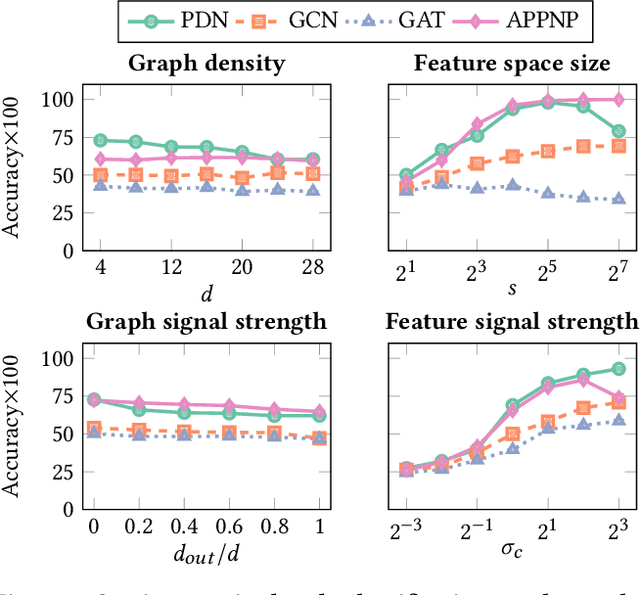
In this work we propose Pathfinder Discovery Networks (PDNs), a method for jointly learning a message passing graph over a multiplex network with a downstream semi-supervised model. PDNs inductively learn an aggregated weight for each edge, optimized to produce the best outcome for the downstream learning task. PDNs are a generalization of attention mechanisms on graphs which allow flexible construction of similarity functions between nodes, edge convolutions, and cheap multiscale mixing layers. We show that PDNs overcome weaknesses of existing methods for graph attention (e.g. Graph Attention Networks), such as the diminishing weight problem. Our experimental results demonstrate competitive predictive performance on academic node classification tasks. Additional results from a challenging suite of node classification experiments show how PDNs can learn a wider class of functions than existing baselines. We analyze the relative computational complexity of PDNs, and show that PDN runtime is not considerably higher than static-graph models. Finally, we discuss how PDNs can be used to construct an easily interpretable attention mechanism that allows users to understand information propagation in the graph.
InstantEmbedding: Efficient Local Node Representations
Oct 14, 2020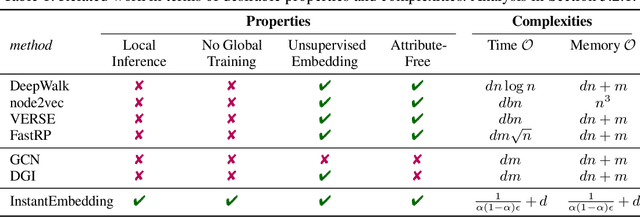
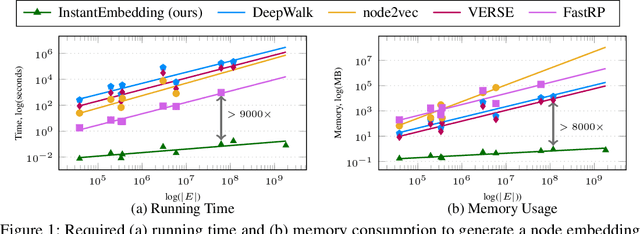
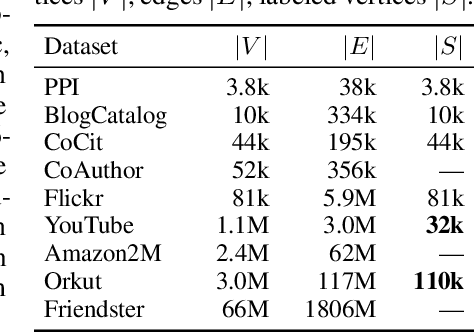
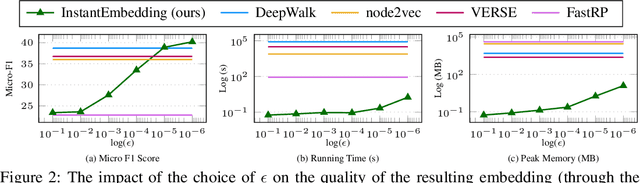
In this paper, we introduce InstantEmbedding, an efficient method for generating single-node representations using local PageRank computations. We theoretically prove that our approach produces globally consistent representations in sublinear time. We demonstrate this empirically by conducting extensive experiments on real-world datasets with over a billion edges. Our experiments confirm that InstantEmbedding requires drastically less computation time (over 9,000 times faster) and less memory (by over 8,000 times) to produce a single node's embedding than traditional methods including DeepWalk, node2vec, VERSE, and FastRP. We also show that our method produces high quality representations, demonstrating results that meet or exceed the state of the art for unsupervised representation learning on tasks like node classification and link prediction.
Grale: Designing Networks for Graph Learning
Jul 23, 2020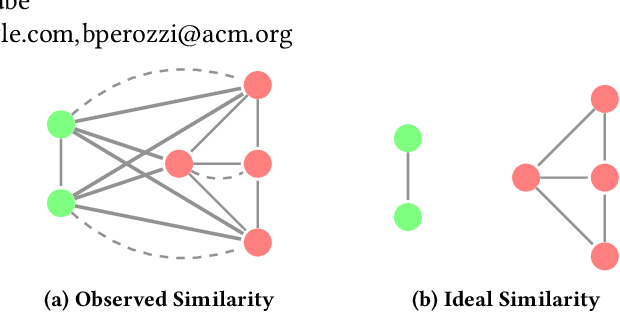
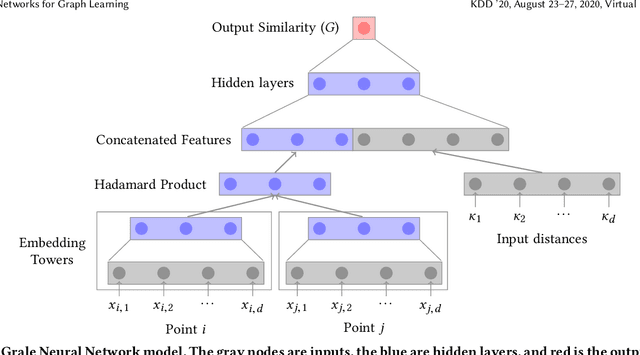

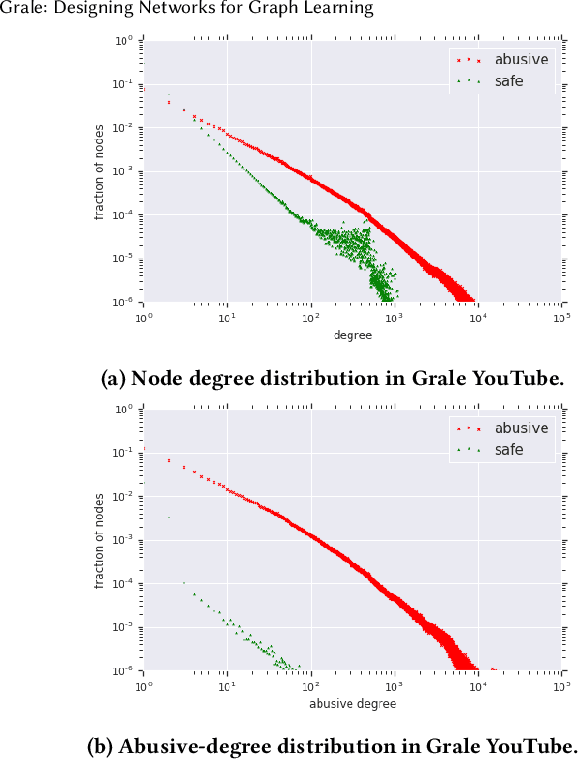
How can we find the right graph for semi-supervised learning? In real world applications, the choice of which edges to use for computation is the first step in any graph learning process. Interestingly, there are often many types of similarity available to choose as the edges between nodes, and the choice of edges can drastically affect the performance of downstream semi-supervised learning systems. However, despite the importance of graph design, most of the literature assumes that the graph is static. In this work, we present Grale, a scalable method we have developed to address the problem of graph design for graphs with billions of nodes. Grale operates by fusing together different measures of(potentially weak) similarity to create a graph which exhibits high task-specific homophily between its nodes. Grale is designed for running on large datasets. We have deployed Grale in more than 20 different industrial settings at Google, including datasets which have tens of billions of nodes, and hundreds of trillions of potential edges to score. By employing locality sensitive hashing techniques,we greatly reduce the number of pairs that need to be scored, allowing us to learn a task specific model and build the associated nearest neighbor graph for such datasets in hours, rather than the days or even weeks that might be required otherwise. We illustrate this through a case study where we examine the application of Grale to an abuse classification problem on YouTube with hundreds of million of items. In this application, we find that Grale detects a large number of malicious actors on top of hard-coded rules and content classifiers, increasing the total recall by 89% over those approaches alone.