 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABC-LMPC: Safe Sample-Based Learning MPC for Stochastic Nonlinear Dynamical Systems with Adjustable Boundary Conditions
Mar 03, 2020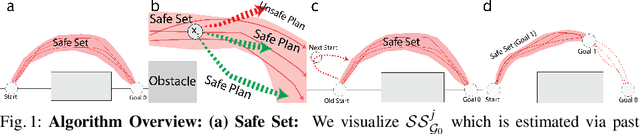

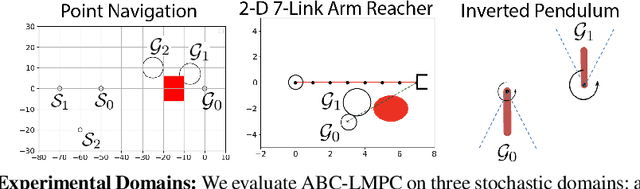
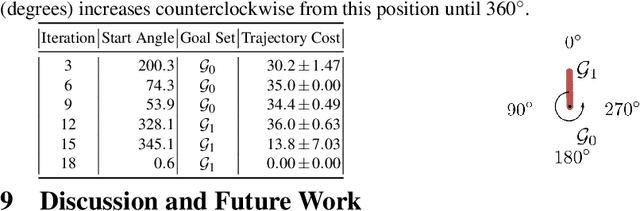
Sample-based learning model predictive control (LMPC) strategies have recently attracted attention due to their desirable theoretical properties and their good empirical performance on robotic tasks. However, prior analysis of LMPC controllers for stochastic systems has mainly focused on linear systems in the iterative learning control setting. We present a novel LMPC algorithm, Adjustable Boundary Condition LMPC (ABC-LMPC), which enables rapid adaptation to novel start and goal configurations and theoretically show that the resulting controller guarantees iterative improvement in expectation for stochastic nonlinear systems. We present results with a practical instantiation of this algorithm and experimentally demonstrate that the resulting controller adapts to a variety of initial and terminal conditions on 3 stochastic continuous control tasks.
Applying Depth-Sensing to Automated Surgical Manipulation with a da Vinci Robot
Feb 15, 2020



Recent advances in depth-sensing have significantly increased accuracy, resolution, and frame rate, as shown in the 1920x1200 resolution and 13 frames per second Zivid RGBD camera. In this study, we explore the potential of depth sensing for efficient and reliable automation of surgical subtasks. We consider a monochrome (all red) version of the peg transfer task from the Fundamentals of Laparoscopic Surgery training suite implemented with the da Vinci Research Kit (dVRK). We use calibration techniques that allow the imprecise, cable-driven da Vinci to reduce error from 4-5 mm to 1-2 mm in the task space. We report experimental results for a handover-free version of the peg transfer task, performing 20 and 5 physical episodes with single- and bilateral-arm setups, respectively. Results over 236 and 49 total block transfer attempts for the single- and bilateral-arm peg transfer cases suggest that reliability can be attained with 86.9 % and 78.0 % for each individual block, with respective block transfer speeds of 10.02 and 5.72 seconds. Supplementary material is available at https://sites.google.com/view/peg-transfer.
Deep Imitation Learning of Sequential Fabric Smoothing Policies
Sep 23, 2019



Sequential pulling policies to flatten and smooth fabrics have applications from surgery to manufacturing to home tasks such as bed making and folding clothes. Due to the complexity of fabric states and dynamics, we apply deep imitation learning to learn policies that, given color or depth images of a rectangular fabric sample, estimate pick points and pull vectors to spread the fabric to maximize coverage. To generate data, we develop a fabric simulator and an algorithmic demonstrator that has access to complete state information. We train policies in simulation using domain randomization and dataset aggregation (DAgger) on three tiers of difficulty in the initial randomized configuration. We present results comparing five baseline policies to learned policies and report systematic comparisons of color vs. depth images as inputs. In simulation, learned policies achieve comparable or superior performance to analytic baselines. In 120 physical experiments with the da Vinci Research Kit (dVRK) surgical robot, policies trained in simulation attain 86% and 69% final coverage for color and depth inputs, respectively, suggesting the feasibility of learning fabric smoothing policies from simulation. Supplementary material is available at https://sites.google.com/view/ fabric-smoothing.
On-Policy Robot Imitation Learning from a Converging Supervisor
Jul 08, 2019


Existing on-policy imitation learning algorithms, such as DAgger, assume access to a fixed supervisor. However, there are many settings where the supervisor may converge during policy learning, such as a human performing a novel task or an improving algorithmic controller. We formalize imitation learning from a "converging supervisor" and provide sublinear static and dynamic regret guarantees against the best policy in hindsight with labels from the converged supervisor, even when labels during learning are only from intermediate supervisors. We then show that this framework is closely connected to a recent class of reinforcement learning (RL) algorithms known as dual policy iteration (DPI), which alternate between training a reactive learner with imitation learning and a model-based supervisor with data from the learner. Experiments suggest that when this framework is applied with the state-of-the-art deep model-based RL algorithm PETS as an improving supervisor, it outperforms deep RL baselines on continuous control tasks and provides up to an 80-fold speedup in policy evaluation.
Extending Deep Model Predictive Control with Safety Augmented Value Estimation from Demonstrations
Jun 03, 2019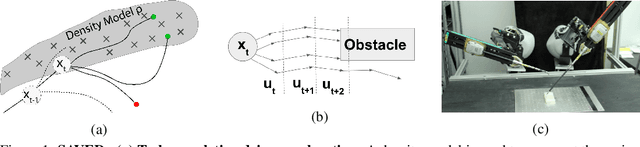
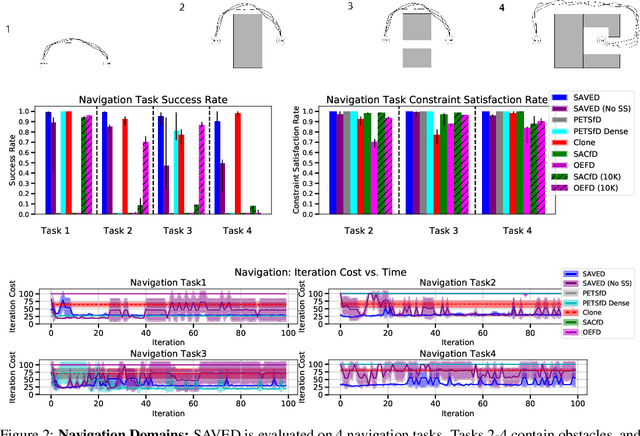

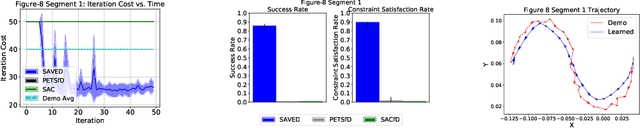
Reinforcement learning (RL) for robotics is challenging due to the difficulty in hand-engineering a dense cost function, which can lead to unintended behavior, and dynamical uncertainty, which makes it hard to enforce constraints during learning. We address these issues with a new model-based reinforcement learning algorithm, safety augmented value estimation from demonstrations (SAVED), which uses supervision that only identifies task completion and a modest set of suboptimal demonstrations to constrain exploration and learn efficiently while handling complex constraints. We derive iterative improvement guarantees for SAVED under known stochastic nonlinear systems. We then compare SAVED with 3 state-of-the-art model-based and model-free RL algorithms on 6 standard simulation benchmarks involving navigation and manipulation and 2 real-world tasks on the da Vinci surgical robot. Results suggest that SAVED outperforms prior methods in terms of success rate, constraint satisfaction, and sample efficiency, making it feasible to safely learn complex maneuvers directly on a real robot in less than an hour. For tasks on the robot, baselines succeed less than 5% of the time while SAVED has a success rate of over 75% in the first 50 training iterations.
Generalizing Robot Imitation Learning with Invariant Hidden Semi-Markov Models
Nov 19, 2018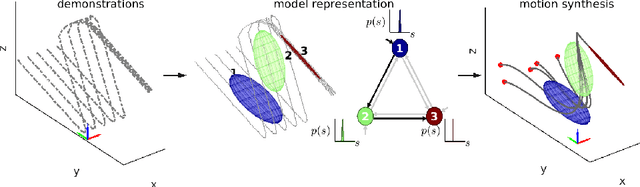
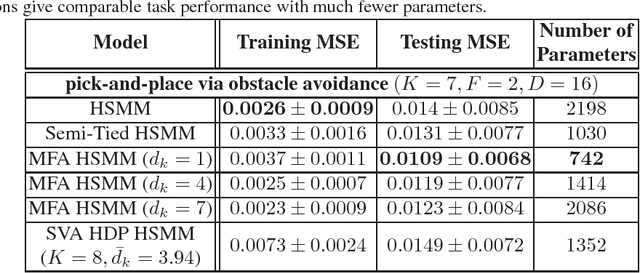
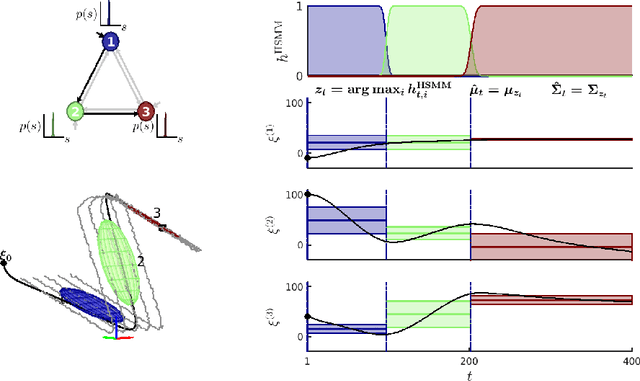
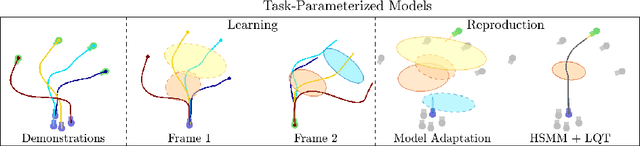
Generalizing manipulation skills to new situations requires extracting invariant patterns from demonstrations. For example, the robot needs to understand the demonstrations at a higher level while being invariant to the appearance of the objects, geometric aspects of objects such as its position, size, orientation and viewpoint of the observer in the demonstrations. In this paper, we propose an algorithm that learns a joint probability density function of the demonstrations with invariant formulations of hidden semi-Markov models to extract invariant segments (also termed as sub-goals or options), and smoothly follow the generated sequence of states with a linear quadratic tracking controller. The algorithm takes as input the demonstrations with respect to different coordinate systems describing virtual landmarks or objects of interest with a task-parameterized formulation, and adapt the segments according to the environmental changes in a systematic manner. We present variants of this algorithm in latent space with low-rank covariance decompositions, semi-tied covariances, and non-parametric online estimation of model parameters under small variance asymptotics; yielding considerably low sample and model complexity for acquiring new manipulation skills. The algorithm allows a Baxter robot to learn a pick-and-place task while avoiding a movable obstacle based on only 4 kinesthetic demonstrations.