 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCirca: Stochastic ReLUs for Private Deep Learning
Jun 15, 2021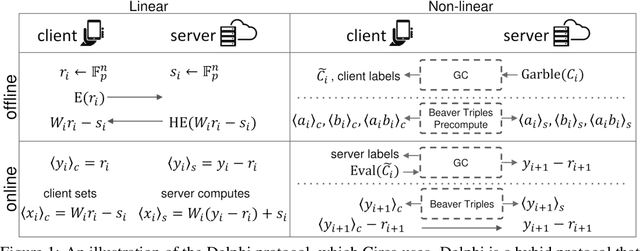
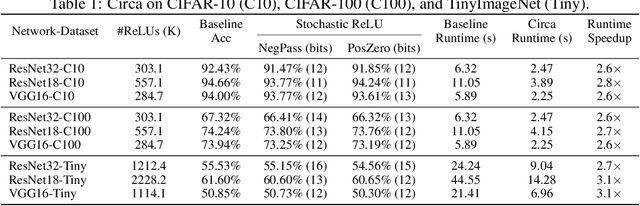
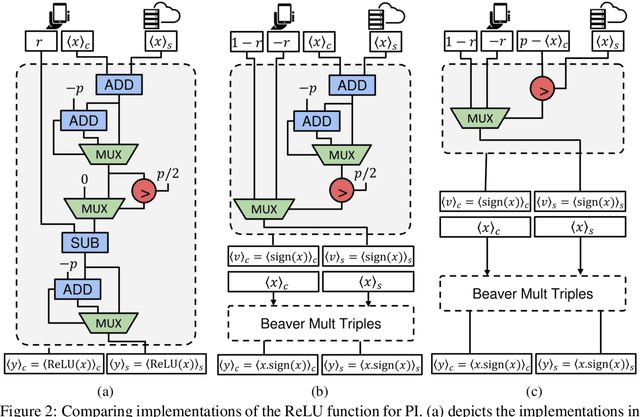
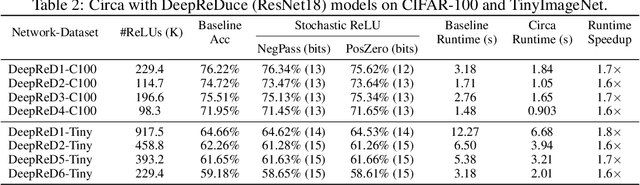
The simultaneous rise of machine learning as a service and concerns over user privacy have increasingly motivated the need for private inference (PI). While recent work demonstrates PI is possible using cryptographic primitives, the computational overheads render it impractical. The community is largely unprepared to address these overheads, as the source of slowdown in PI stems from the ReLU operator whereas optimizations for plaintext inference focus on optimizing FLOPs. In this paper we re-think the ReLU computation and propose optimizations for PI tailored to properties of neural networks. Specifically, we reformulate ReLU as an approximate sign test and introduce a novel truncation method for the sign test that significantly reduces the cost per ReLU. These optimizations result in a specific type of stochastic ReLU. The key observation is that the stochastic fault behavior is well suited for the fault-tolerant properties of neural network inference. Thus, we provide significant savings without impacting accuracy. We collectively call the optimizations Circa and demonstrate improvements of up to 4.7x storage and 3x runtime over baseline implementations; we further show that Circa can be used on top of recent PI optimizations to obtain 1.8x additional speedup.
Analysis and Mitigations of Reverse Engineering Attacks on Local Feature Descriptors
May 09, 2021
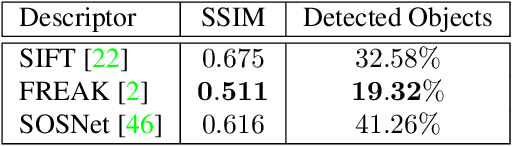
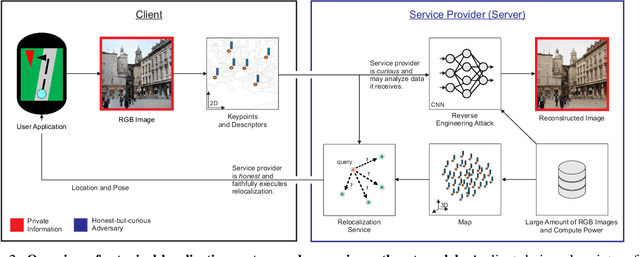
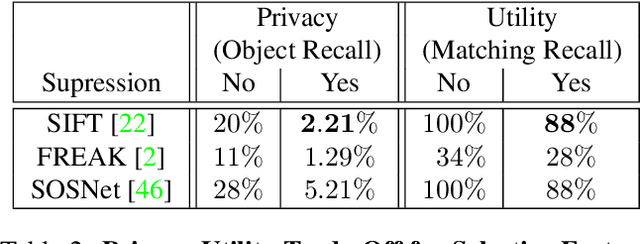
As autonomous driving and augmented reality evolve, a practical concern is data privacy. In particular, these applications rely on localization based on user images. The widely adopted technology uses local feature descriptors, which are derived from the images and it was long thought that they could not be reverted back. However, recent work has demonstrated that under certain conditions reverse engineering attacks are possible and allow an adversary to reconstruct RGB images. This poses a potential risk to user privacy. We take this a step further and model potential adversaries using a privacy threat model. Subsequently, we show under controlled conditions a reverse engineering attack on sparse feature maps and analyze the vulnerability of popular descriptors including FREAK, SIFT and SOSNet. Finally, we evaluate potential mitigation techniques that select a subset of descriptors to carefully balance privacy reconstruction risk while preserving image matching accuracy; our results show that similar accuracy can be obtained when revealing less information.
DeepReDuce: ReLU Reduction for Fast Private Inference
Mar 02, 2021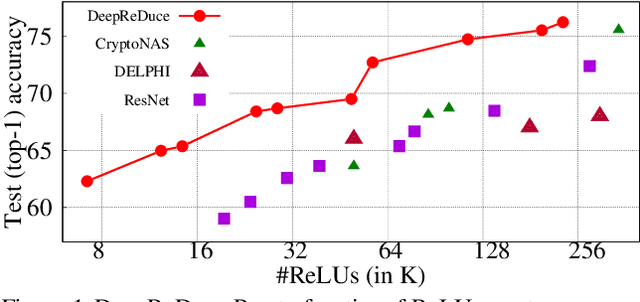
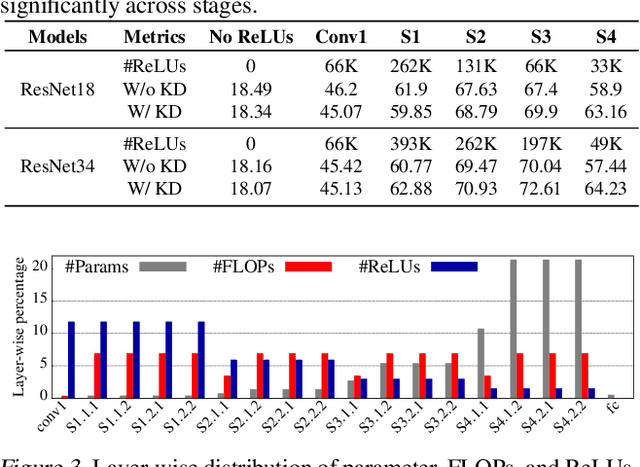
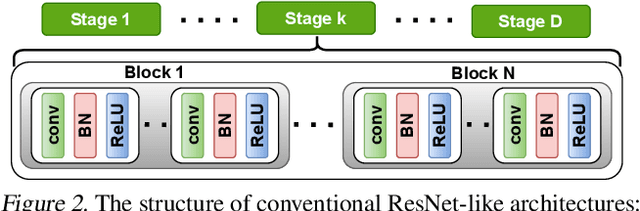
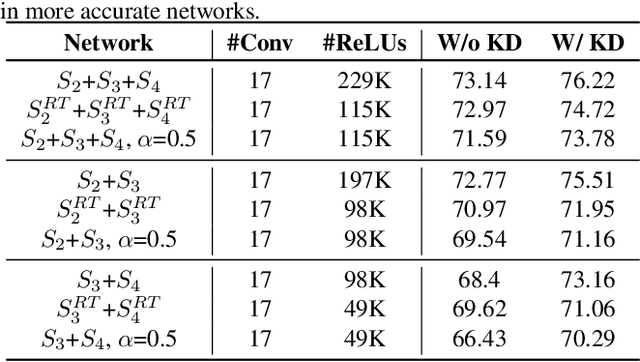
The recent rise of privacy concerns has led researchers to devise methods for private neural inference -- where inferences are made directly on encrypted data, never seeing inputs. The primary challenge facing private inference is that computing on encrypted data levies an impractically-high latency penalty, stemming mostly from non-linear operators like ReLU. Enabling practical and private inference requires new optimization methods that minimize network ReLU counts while preserving accuracy. This paper proposes DeepReDuce: a set of optimizations for the judicious removal of ReLUs to reduce private inference latency. The key insight is that not all ReLUs contribute equally to accuracy. We leverage this insight to drop, or remove, ReLUs from classic networks to significantly reduce inference latency and maintain high accuracy. Given a target network, DeepReDuce outputs a Pareto frontier of networks that tradeoff the number of ReLUs and accuracy. Compared to the state-of-the-art for private inference DeepReDuce improves accuracy and reduces ReLU count by up to 3.5% (iso-ReLU count) and 3.5$\times$ (iso-accuracy), respectively.
CryptoNAS: Private Inference on a ReLU Budget
Jun 15, 2020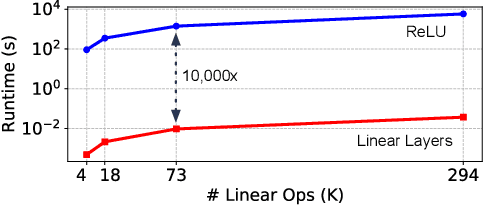
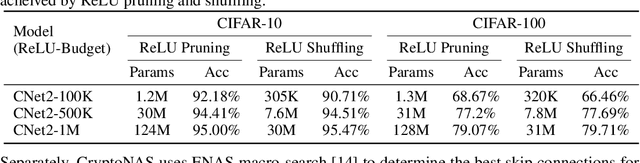
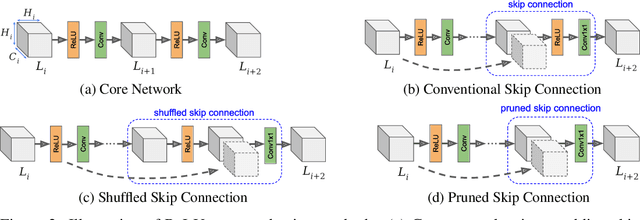
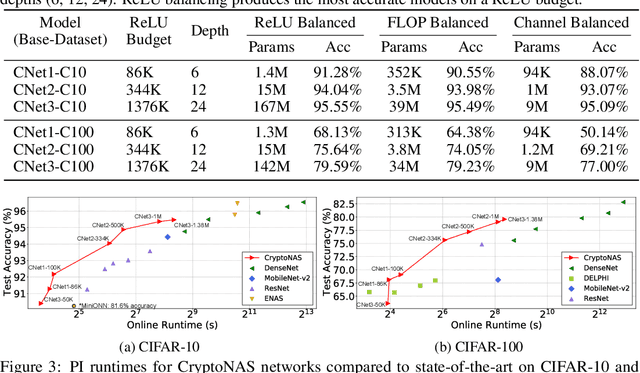
Machine learning as a service has given raise to privacy concerns surrounding clients' data and providers' models and has catalyzed research in private inference (PI): methods to process inferences without disclosing inputs. Recently, researchers have adapted cryptographic techniques to show PI is possible, however all solutions increase inference latency beyond practical limits. This paper makes the observation that existing models are ill-suited for PI and proposes a novel NAS method, named CryptoNAS, for finding and tailoring models to the needs of PI. The key insight is that in PI operator latency cost are non-linear operations (e.g., ReLU) dominate latency, while linear layers become effectively free. We develop the idea of a ReLU budget as a proxy for inference latency and use CryptoNAS to build models that maximize accuracy within a given budget. CryptoNAS improves accuracy by 3.4% and latency by 2.4x over the state-of-the-art.
The Architectural Implications of Facebook's DNN-based Personalized Recommendation
Jun 18, 2019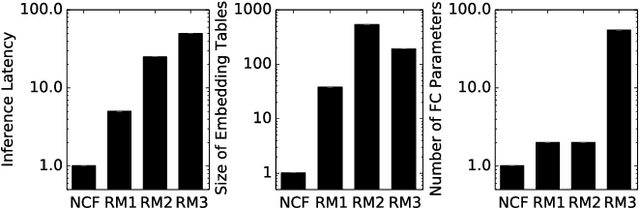
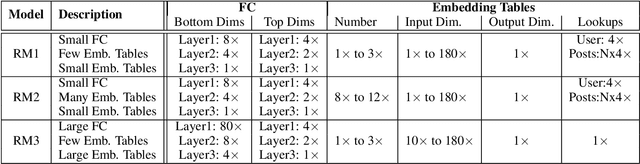
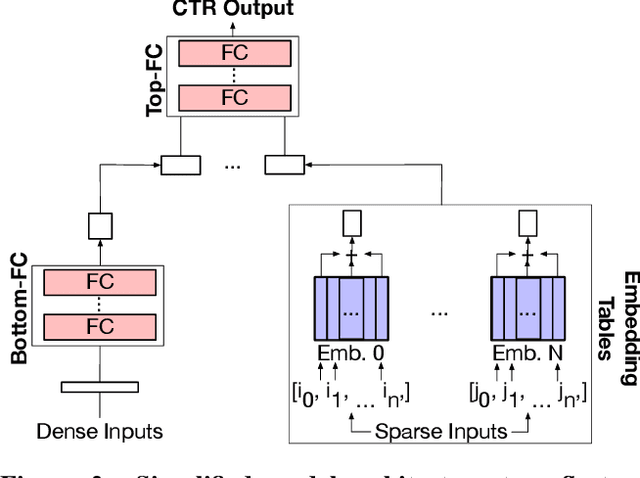
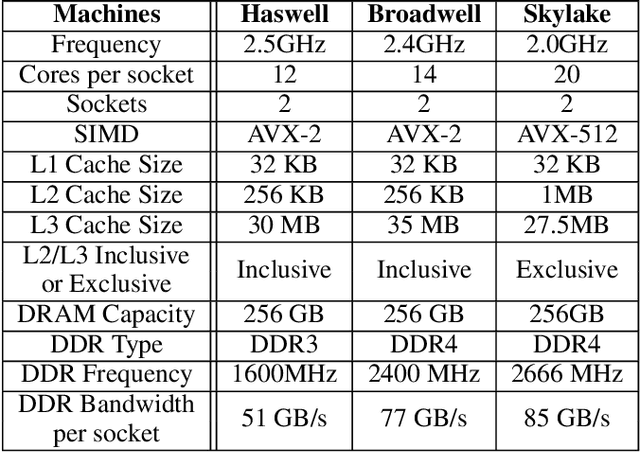
The widespread application of deep learning has changed the landscape of computation in the data center. In particular, personalized recommendation for content ranking is now largely accomplished leveraging deep neural networks. However, despite the importance of these models and the amount of compute cycles they consume, relatively little research attention has been devoted to systems for recommendation. To facilitate research and to advance the understanding of these workloads, this paper presents a set of real-world, production-scale DNNs for personalized recommendation coupled with relevant performance metrics for evaluation. In addition to releasing a set of open-source workloads, we conduct in-depth analysis that underpins future system design and optimization for at-scale recommendation: Inference latency varies by 60% across three Intel server generations, batching and co-location of inferences can drastically improve latency-bounded throughput, and the diverse composition of recommendation models leads to different optimization strategies.
Weightless: Lossy Weight Encoding For Deep Neural Network Compression
Nov 13, 2017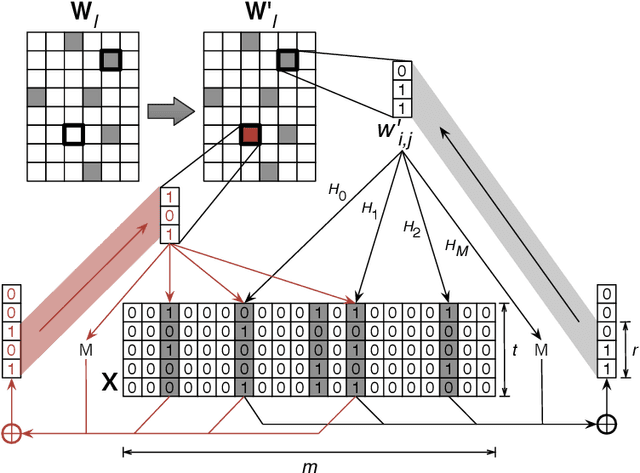
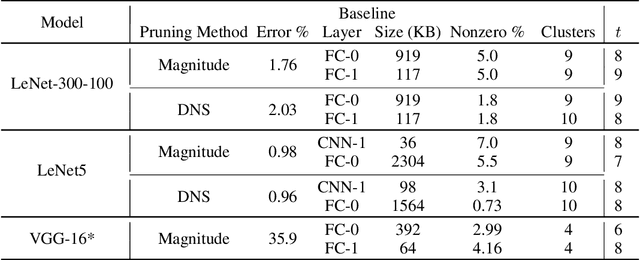
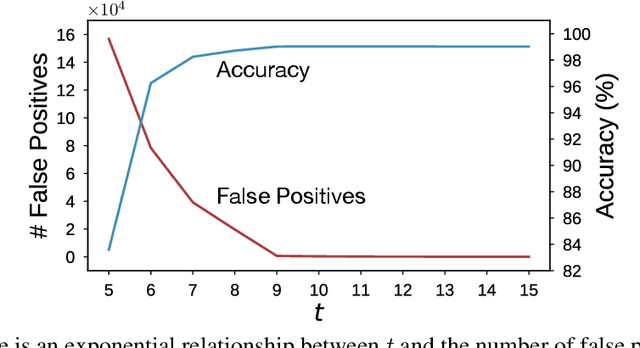
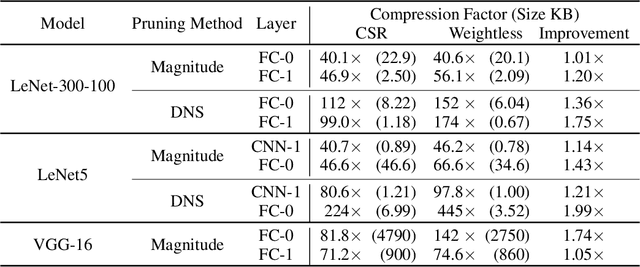
The large memory requirements of deep neural networks limit their deployment and adoption on many devices. Model compression methods effectively reduce the memory requirements of these models, usually through applying transformations such as weight pruning or quantization. In this paper, we present a novel scheme for lossy weight encoding which complements conventional compression techniques. The encoding is based on the Bloomier filter, a probabilistic data structure that can save space at the cost of introducing random errors. Leveraging the ability of neural networks to tolerate these imperfections and by re-training around the errors, the proposed technique, Weightless, can compress DNN weights by up to 496x with the same model accuracy. This results in up to a 1.51x improvement over the state-of-the-art.
Fathom: Reference Workloads for Modern Deep Learning Methods
Aug 23, 2016
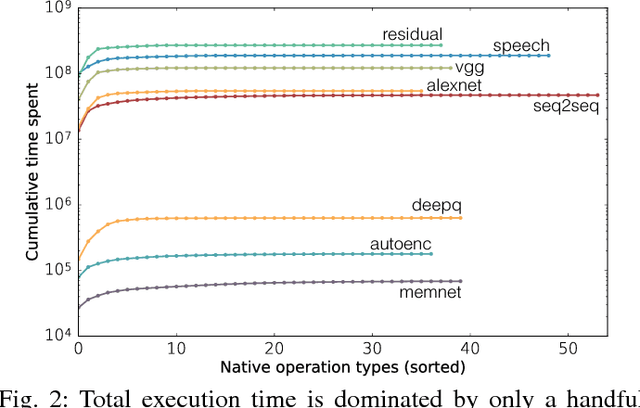
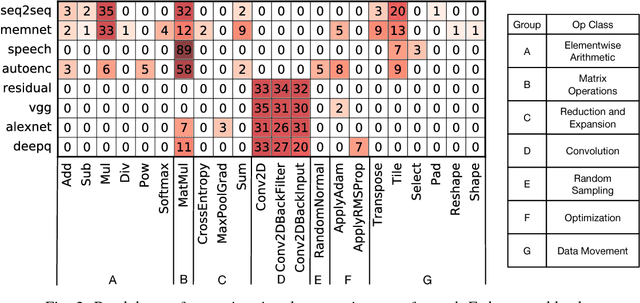
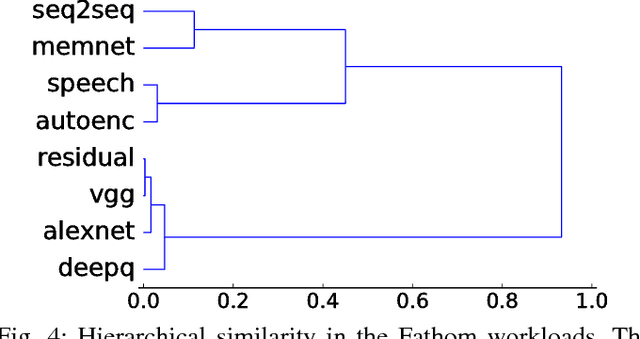
Deep learning has been popularized by its recent successes on challenging artificial intelligence problems. One of the reasons for its dominance is also an ongoing challenge: the need for immense amounts of computational power. Hardware architects have responded by proposing a wide array of promising ideas, but to date, the majority of the work has focused on specific algorithms in somewhat narrow application domains. While their specificity does not diminish these approaches, there is a clear need for more flexible solutions. We believe the first step is to examine the characteristics of cutting edge models from across the deep learning community. Consequently, we have assembled Fathom: a collection of eight archetypal deep learning workloads for study. Each of these models comes from a seminal work in the deep learning community, ranging from the familiar deep convolutional neural network of Krizhevsky et al., to the more exotic memory networks from Facebook's AI research group. Fathom has been released online, and this paper focuses on understanding the fundamental performance characteristics of each model. We use a set of application-level modeling tools built around the TensorFlow deep learning framework in order to analyze the behavior of the Fathom workloads. We present a breakdown of where time is spent, the similarities between the performance profiles of our models, an analysis of behavior in inference and training, and the effects of parallelism on scaling.