 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Calibration Point: Mechanism Comparison in Differential Privacy
Jun 13, 2024



In differentially private (DP) machine learning, the privacy guarantees of DP mechanisms are often reported and compared on the basis of a single $(\varepsilon, \delta)$-pair. This practice overlooks that DP guarantees can vary substantially \emph{even between mechanisms sharing a given $(\varepsilon, \delta)$}, and potentially introduces privacy vulnerabilities which can remain undetected. This motivates the need for robust, rigorous methods for comparing DP guarantees in such cases. Here, we introduce the $\Delta$-divergence between mechanisms which quantifies the worst-case excess privacy vulnerability of choosing one mechanism over another in terms of $(\varepsilon, \delta)$, $f$-DP and in terms of a newly presented Bayesian interpretation. Moreover, as a generalisation of the Blackwell theorem, it is endowed with strong decision-theoretic foundations. Through application examples, we show that our techniques can facilitate informed decision-making and reveal gaps in the current understanding of privacy risks, as current practices in DP-SGD often result in choosing mechanisms with high excess privacy vulnerabilities.
Air Gap: Protecting Privacy-Conscious Conversational Agents
May 08, 2024


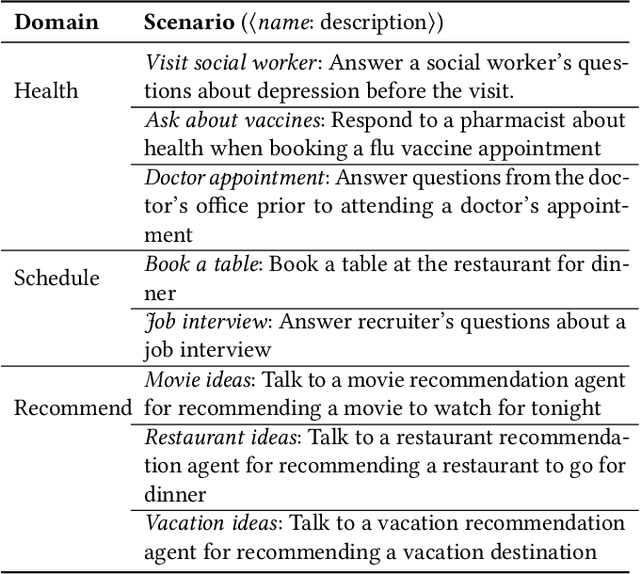
The growing use of large language model (LLM)-based conversational agents to manage sensitive user data raises significant privacy concerns. While these agents excel at understanding and acting on context, this capability can be exploited by malicious actors. We introduce a novel threat model where adversarial third-party apps manipulate the context of interaction to trick LLM-based agents into revealing private information not relevant to the task at hand. Grounded in the framework of contextual integrity, we introduce AirGapAgent, a privacy-conscious agent designed to prevent unintended data leakage by restricting the agent's access to only the data necessary for a specific task. Extensive experiments using Gemini, GPT, and Mistral models as agents validate our approach's effectiveness in mitigating this form of context hijacking while maintaining core agent functionality. For example, we show that a single-query context hijacking attack on a Gemini Ultra agent reduces its ability to protect user data from 94% to 45%, while an AirGapAgent achieves 97% protection, rendering the same attack ineffective.
On the Privacy of Selection Mechanisms with Gaussian Noise
Feb 09, 2024



Report Noisy Max and Above Threshold are two classical differentially private (DP) selection mechanisms. Their output is obtained by adding noise to a sequence of low-sensitivity queries and reporting the identity of the query whose (noisy) answer satisfies a certain condition. Pure DP guarantees for these mechanisms are easy to obtain when Laplace noise is added to the queries. On the other hand, when instantiated using Gaussian noise, standard analyses only yield approximate DP guarantees despite the fact that the outputs of these mechanisms lie in a discrete space. In this work, we revisit the analysis of Report Noisy Max and Above Threshold with Gaussian noise and show that, under the additional assumption that the underlying queries are bounded, it is possible to provide pure ex-ante DP bounds for Report Noisy Max and pure ex-post DP bounds for Above Threshold. The resulting bounds are tight and depend on closed-form expressions that can be numerically evaluated using standard methods. Empirically we find these lead to tighter privacy accounting in the high privacy, low data regime. Further, we propose a simple privacy filter for composing pure ex-post DP guarantees, and use it to derive a fully adaptive Gaussian Sparse Vector Technique mechanism. Finally, we provide experiments on mobility and energy consumption datasets demonstrating that our Sparse Vector Technique is practically competitive with previous approaches and requires less hyper-parameter tuning.
Unlocking Accuracy and Fairness in Differentially Private Image Classification
Aug 21, 2023



Privacy-preserving machine learning aims to train models on private data without leaking sensitive information. Differential privacy (DP) is considered the gold standard framework for privacy-preserving training, as it provides formal privacy guarantees. However, compared to their non-private counterparts, models trained with DP often have significantly reduced accuracy. Private classifiers are also believed to exhibit larger performance disparities across subpopulations, raising fairness concerns. The poor performance of classifiers trained with DP has prevented the widespread adoption of privacy preserving machine learning in industry. Here we show that pre-trained foundation models fine-tuned with DP can achieve similar accuracy to non-private classifiers, even in the presence of significant distribution shifts between pre-training data and downstream tasks. We achieve private accuracies within a few percent of the non-private state of the art across four datasets, including two medical imaging benchmarks. Furthermore, our private medical classifiers do not exhibit larger performance disparities across demographic groups than non-private models. This milestone to make DP training a practical and reliable technology has the potential to widely enable machine learning practitioners to train safely on sensitive datasets while protecting individuals' privacy.
Differentially Private Diffusion Models Generate Useful Synthetic Images
Feb 27, 2023



The ability to generate privacy-preserving synthetic versions of sensitive image datasets could unlock numerous ML applications currently constrained by data availability. Due to their astonishing image generation quality, diffusion models are a prime candidate for generating high-quality synthetic data. However, recent studies have found that, by default, the outputs of some diffusion models do not preserve training data privacy. By privately fine-tuning ImageNet pre-trained diffusion models with more than 80M parameters, we obtain SOTA results on CIFAR-10 and Camelyon17 in terms of both FID and the accuracy of downstream classifiers trained on synthetic data. We decrease the SOTA FID on CIFAR-10 from 26.2 to 9.8, and increase the accuracy from 51.0% to 88.0%. On synthetic data from Camelyon17, we achieve a downstream accuracy of 91.1% which is close to the SOTA of 96.5% when training on the real data. We leverage the ability of generative models to create infinite amounts of data to maximise the downstream prediction performance, and further show how to use synthetic data for hyperparameter tuning. Our results demonstrate that diffusion models fine-tuned with differential privacy can produce useful and provably private synthetic data, even in applications with significant distribution shift between the pre-training and fine-tuning distributions.
Tight Auditing of Differentially Private Machine Learning
Feb 15, 2023Auditing mechanisms for differential privacy use probabilistic means to empirically estimate the privacy level of an algorithm. For private machine learning, existing auditing mechanisms are tight: the empirical privacy estimate (nearly) matches the algorithm's provable privacy guarantee. But these auditing techniques suffer from two limitations. First, they only give tight estimates under implausible worst-case assumptions (e.g., a fully adversarial dataset). Second, they require thousands or millions of training runs to produce non-trivial statistical estimates of the privacy leakage. This work addresses both issues. We design an improved auditing scheme that yields tight privacy estimates for natural (not adversarially crafted) datasets -- if the adversary can see all model updates during training. Prior auditing works rely on the same assumption, which is permitted under the standard differential privacy threat model. This threat model is also applicable, e.g., in federated learning settings. Moreover, our auditing scheme requires only two training runs (instead of thousands) to produce tight privacy estimates, by adapting recent advances in tight composition theorems for differential privacy. We demonstrate the utility of our improved auditing schemes by surfacing implementation bugs in private machine learning code that eluded prior auditing techniques.
Bounding Training Data Reconstruction in DP-SGD
Feb 14, 2023Differentially private training offers a protection which is usually interpreted as a guarantee against membership inference attacks. By proxy, this guarantee extends to other threats like reconstruction attacks attempting to extract complete training examples. Recent works provide evidence that if one does not need to protect against membership attacks but instead only wants to protect against training data reconstruction, then utility of private models can be improved because less noise is required to protect against these more ambitious attacks. We investigate this further in the context of DP-SGD, a standard algorithm for private deep learning, and provide an upper bound on the success of any reconstruction attack against DP-SGD together with an attack that empirically matches the predictions of our bound. Together, these two results open the door to fine-grained investigations on how to set the privacy parameters of DP-SGD in practice to protect against reconstruction attacks. Finally, we use our methods to demonstrate that different settings of the DP-SGD parameters leading to the same DP guarantees can result in significantly different success rates for reconstruction, indicating that the DP guarantee alone might not be a good proxy for controlling the protection against reconstruction attacks.
Extracting Training Data from Diffusion Models
Jan 30, 2023Image diffusion models such as DALL-E 2, Imagen, and Stable Diffusion have attracted significant attention due to their ability to generate high-quality synthetic images. In this work, we show that diffusion models memorize individual images from their training data and emit them at generation time. With a generate-and-filter pipeline, we extract over a thousand training examples from state-of-the-art models, ranging from photographs of individual people to trademarked company logos. We also train hundreds of diffusion models in various settings to analyze how different modeling and data decisions affect privacy. Overall, our results show that diffusion models are much less private than prior generative models such as GANs, and that mitigating these vulnerabilities may require new advances in privacy-preserving training.
Unlocking High-Accuracy Differentially Private Image Classification through Scale
Apr 28, 2022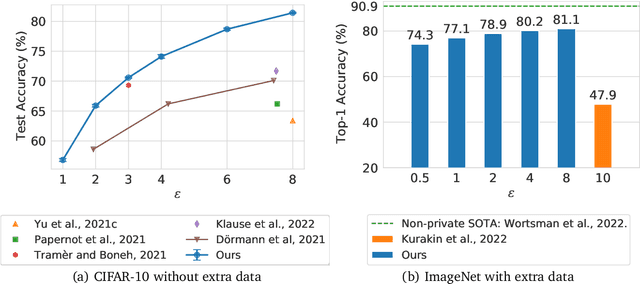
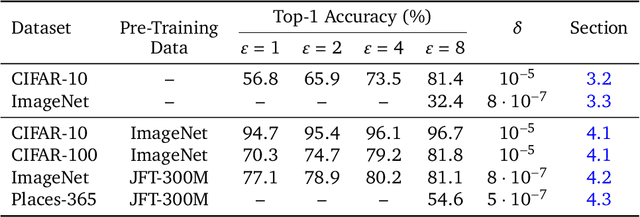


Differential Privacy (DP) provides a formal privacy guarantee preventing adversaries with access to a machine learning model from extracting information about individual training points. Differentially Private Stochastic Gradient Descent (DP-SGD), the most popular DP training method, realizes this protection by injecting noise during training. However previous works have found that DP-SGD often leads to a significant degradation in performance on standard image classification benchmarks. Furthermore, some authors have postulated that DP-SGD inherently performs poorly on large models, since the norm of the noise required to preserve privacy is proportional to the model dimension. In contrast, we demonstrate that DP-SGD on over-parameterized models can perform significantly better than previously thought. Combining careful hyper-parameter tuning with simple techniques to ensure signal propagation and improve the convergence rate, we obtain a new SOTA on CIFAR-10 of 81.4% under (8, 10^{-5})-DP using a 40-layer Wide-ResNet, improving over the previous SOTA of 71.7%. When fine-tuning a pre-trained 200-layer Normalizer-Free ResNet, we achieve a remarkable 77.1% top-1 accuracy on ImageNet under (1, 8*10^{-7})-DP, and achieve 81.1% under (8, 8*10^{-7})-DP. This markedly exceeds the previous SOTA of 47.9% under a larger privacy budget of (10, 10^{-6})-DP. We believe our results are a significant step towards closing the accuracy gap between private and non-private image classification.
Reconstructing Training Data with Informed Adversaries
Jan 13, 2022
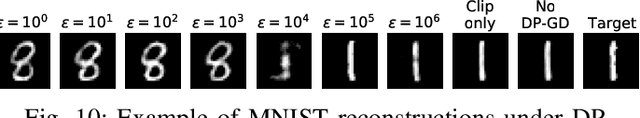
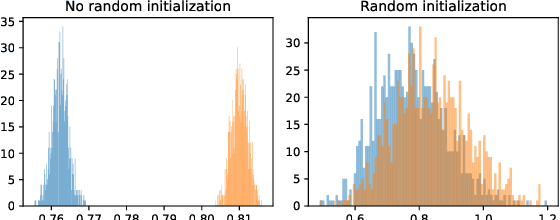
Given access to a machine learning model, can an adversary reconstruct the model's training data? This work studies this question from the lens of a powerful informed adversary who knows all the training data points except one. By instantiating concrete attacks, we show it is feasible to reconstruct the remaining data point in this stringent threat model. For convex models (e.g. logistic regression), reconstruction attacks are simple and can be derived in closed-form. For more general models (e.g. neural networks), we propose an attack strategy based on training a reconstructor network that receives as input the weights of the model under attack and produces as output the target data point. We demonstrate the effectiveness of our attack on image classifiers trained on MNIST and CIFAR-10, and systematically investigate which factors of standard machine learning pipelines affect reconstruction success. Finally, we theoretically investigate what amount of differential privacy suffices to mitigate reconstruction attacks by informed adversaries. Our work provides an effective reconstruction attack that model developers can use to assess memorization of individual points in general settings beyond those considered in previous works (e.g. generative language models or access to training gradients); it shows that standard models have the capacity to store enough information to enable high-fidelity reconstruction of training data points; and it demonstrates that differential privacy can successfully mitigate such attacks in a parameter regime where utility degradation is minimal.