 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetro*: Learning Retrosynthetic Planning with Neural Guided A* Search
Jun 29, 2020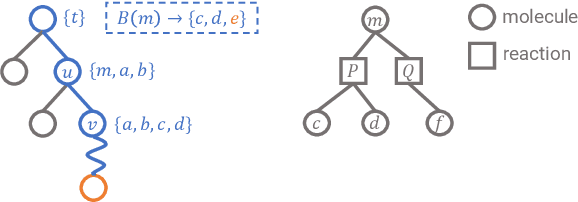

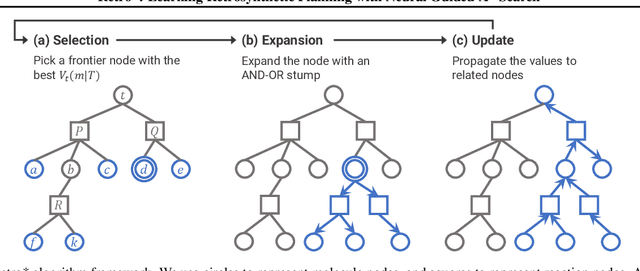
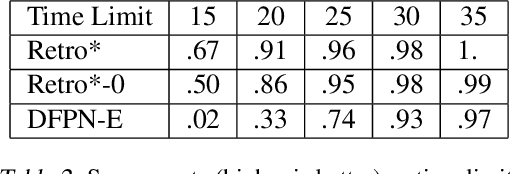
Retrosynthetic planning is a critical task in organic chemistry which identifies a series of reactions that can lead to the synthesis of a target product. The vast number of possible chemical transformations makes the size of the search space very big, and retrosynthetic planning is challenging even for experienced chemists. However, existing methods either require expensive return estimation by rollout with high variance, or optimize for search speed rather than the quality. In this paper, we propose Retro*, a neural-based A*-like algorithm that finds high-quality synthetic routes efficiently. It maintains the search as an AND-OR tree, and learns a neural search bias with off-policy data. Then guided by this neural network, it performs best-first search efficiently during new planning episodes. Experiments on benchmark USPTO datasets show that, our proposed method outperforms existing state-of-the-art with respect to both the success rate and solution quality, while being more efficient at the same time.
GLAD: Learning Sparse Graph Recovery
Jun 01, 2019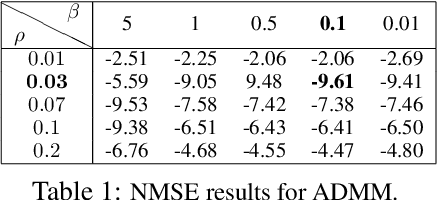
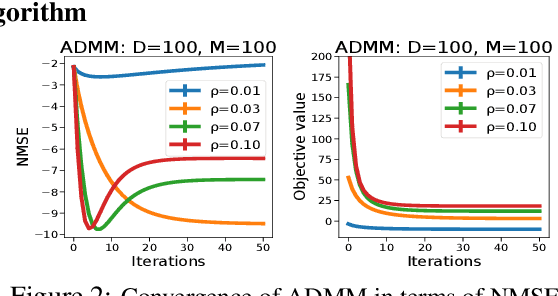
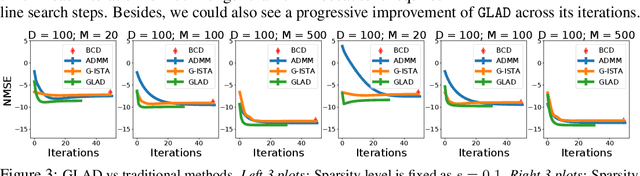
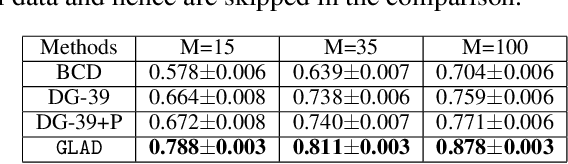
Recovering sparse conditional independence graphs from data is a fundamental problem in machine learning with wide applications. A popular formulation of the problem is an $\ell_1$ regularized maximum likelihood estimation. Many convex optimization algorithms have been designed to solve this formulation to recover the graph structure. Recently, there is a surge of interest to learn algorithms directly based on data, and in this case, learn to map empirical covariance to the sparse precision matrix. However, it is a challenging task in this case, since the symmetric positive definiteness (SPD) and sparsity of the matrix are not easy to enforce in learned algorithms, and a direct mapping from data to precision matrix may contain many parameters. We propose a deep learning architecture, GLAD, which uses an Alternating Minimization (AM) algorithm as our model inductive bias, and learns the model parameters via supervised learning. We show that GLAD learns a very compact and effective model for recovering sparse graph from data.
Learning to Plan via Neural Exploration-Exploitation Trees
Mar 26, 2019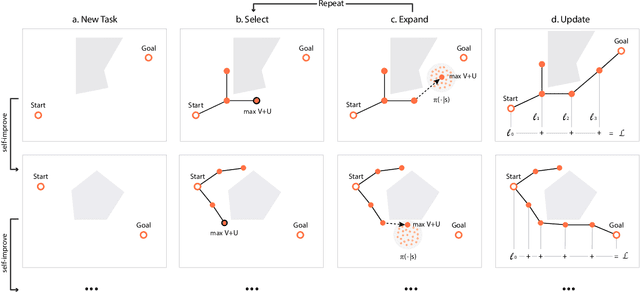
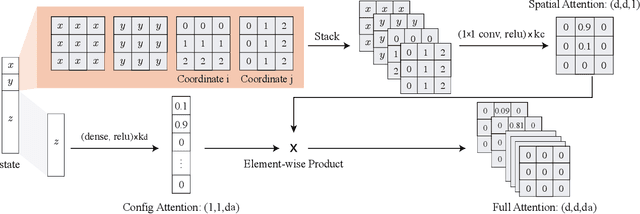
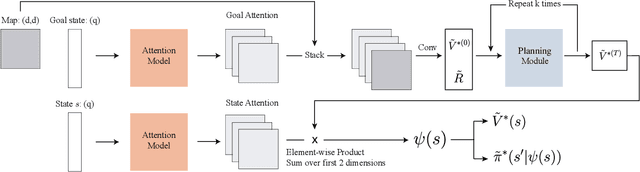

Sampling-based planning algorithms such as RRT and its variants are powerful tools for path planning problems in high-dimensional continuous state and action spaces. While these algorithms perform systematic exploration of the state space, they do not fully exploit past planning experiences from similar environments. In this paper, we design a meta path planning algorithm, called Neural Exploration-Exploitation Trees (NEXT), which can utilize prior experience to drastically reduce the sample requirement for solving new path planning problems. More specifically, NEXT contains a novel neural architecture which can learn from experiences the dependency between task structures and promising path search directions. Then this learned prior is integrated with a UCB-type algorithm to achieve an online balance between exploration and exploitation when solving a new problem. Empirically, we show that NEXT can complete the planning tasks with very small search trees and significantly outperforms previous state-of-the-arts on several benchmark problems.
A Communication-Efficient Parallel Method for Group-Lasso
Dec 07, 2016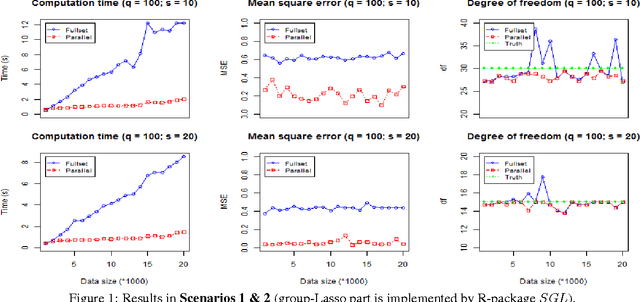
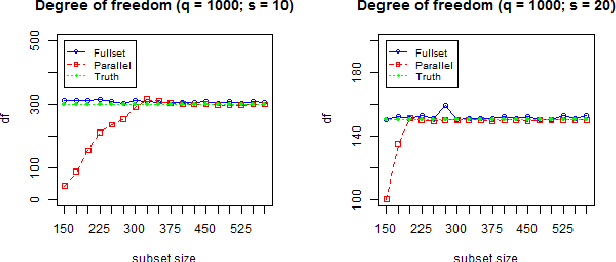
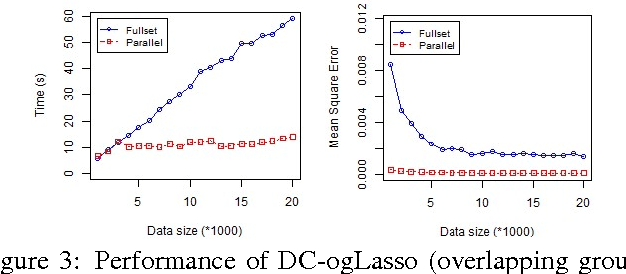
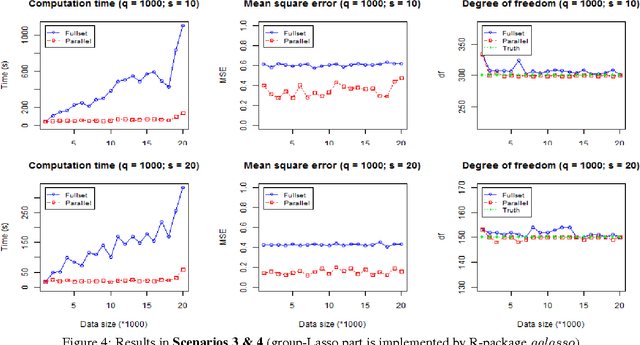
Group-Lasso (gLasso) identifies important explanatory factors in predicting the response variable by considering the grouping structure over input variables. However, most existing algorithms for gLasso are not scalable to deal with large-scale datasets, which are becoming a norm in many applications. In this paper, we present a divide-and-conquer based parallel algorithm (DC-gLasso) to scale up gLasso in the tasks of regression with grouping structures. DC-gLasso only needs two iterations to collect and aggregate the local estimates on subsets of the data, and is provably correct to recover the true model under certain conditions. We further extend it to deal with overlappings between groups. Empirical results on a wide range of synthetic and real-world datasets show that DC-gLasso can significantly improve the time efficiency without sacrificing regression accuracy.