 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepRepair: Style-Guided Repairing for DNNs in the Real-world Operational Environment
Nov 19, 2020
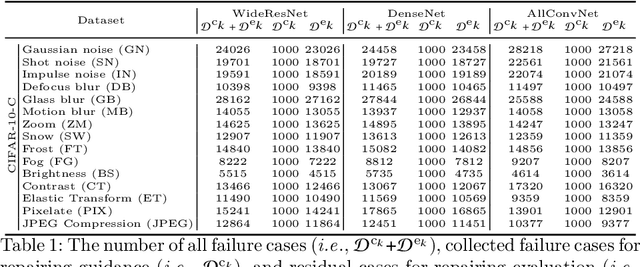
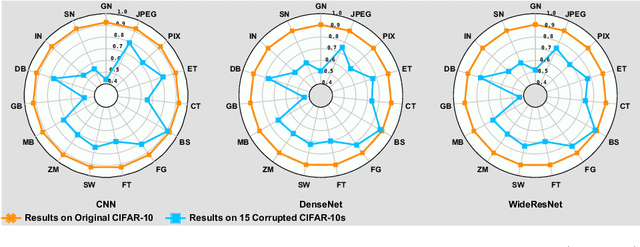
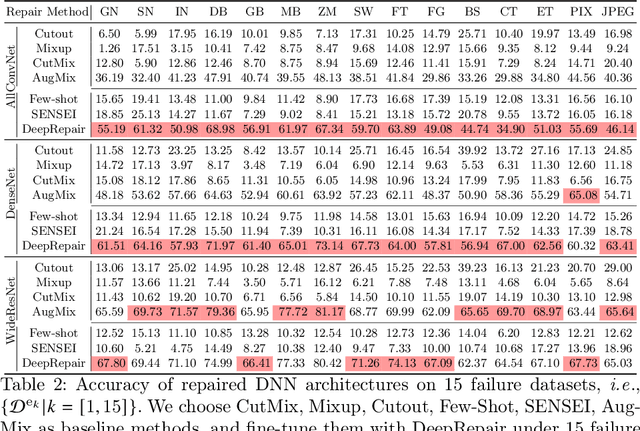
Deep neural networks (DNNs) are being widely applied for various real-world applications across domains due to their high performance (e.g., high accuracy on image classification). Nevertheless, a well-trained DNN after deployment could oftentimes raise errors during practical use in the operational environment due to the mismatching between distributions of the training dataset and the potential unknown noise factors in the operational environment, e.g., weather, blur, noise etc. Hence, it poses a rather important problem for the DNNs' real-world applications: how to repair the deployed DNNs for correcting the failure samples (i.e., incorrect prediction) under the deployed operational environment while not harming their capability of handling normal or clean data. The number of failure samples we can collect in practice, caused by the noise factors in the operational environment, is often limited. Therefore, It is rather challenging how to repair more similar failures based on the limited failure samples we can collect. In this paper, we propose a style-guided data augmentation for repairing DNN in the operational environment. We propose a style transfer method to learn and introduce the unknown failure patterns within the failure data into the training data via data augmentation. Moreover, we further propose the clustering-based failure data generation for much more effective style-guided data augmentation. We conduct a large-scale evaluation with fifteen degradation factors that may happen in the real world and compare with four state-of-the-art data augmentation methods and two DNN repairing methods, demonstrating that our method can significantly enhance the deployed DNNs on the corrupted data in the operational environment, and with even better accuracy on clean datasets.
Classify and Generate Reciprocally: Simultaneous Positive-Unlabelled Learning and Conditional Generation with Extra Data
Jun 14, 2020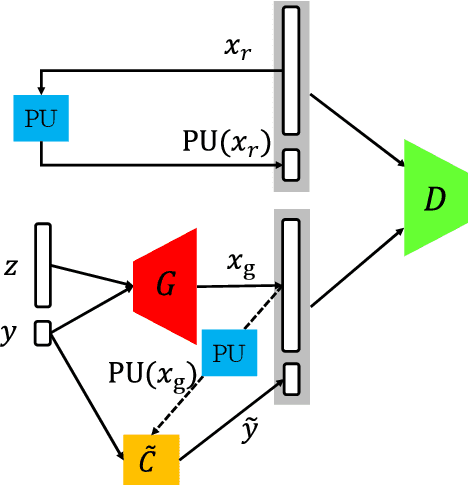
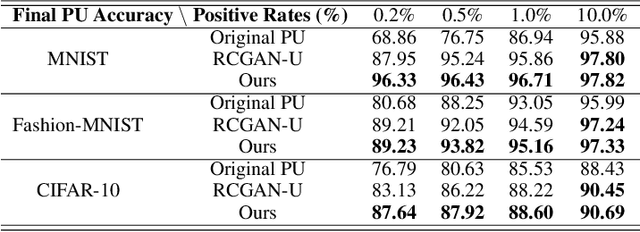
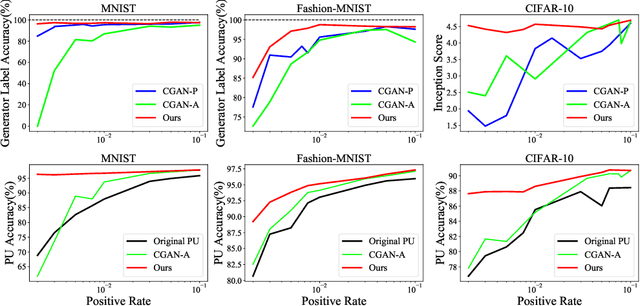

The scarcity of class-labeled data is a ubiquitous bottleneck in a wide range of machine learning problems. While abundant unlabeled data normally exist and provide a potential solution, it is extremely challenging to exploit them. In this paper, we address this problem by leveraging Positive-Unlabeled~(PU) classification and conditional generation with extra unlabeled data \emph{simultaneously}, both of which aim to make full use of agnostic unlabeled data to improve classification and generation performances. In particular, we present a novel training framework to jointly target both PU classification and conditional generation when exposing to extra data, especially out-of-distribution unlabeled data, by exploring the interplay between them: 1) enhancing the performance of PU classifiers with the assistance of a novel Conditional Generative Adversarial Network~(CGAN) that is robust to noisy labels, 2) leveraging extra data with predicted labels from a PU classifier to help the generation. Our key contribution is a Classifier-Noise-Invariant Conditional GAN~(CNI-CGAN) that can learn the clean data distribution from noisy labels predicted by a PU classifier. Theoretically, we proved the optimal condition of CNI-CGAN and experimentally, we conducted extensive evaluations on diverse datasets, verifying the simultaneous improvements on both classification and generation.
Patch-level Neighborhood Interpolation: A General and Effective Graph-based Regularization Strategy
Nov 21, 2019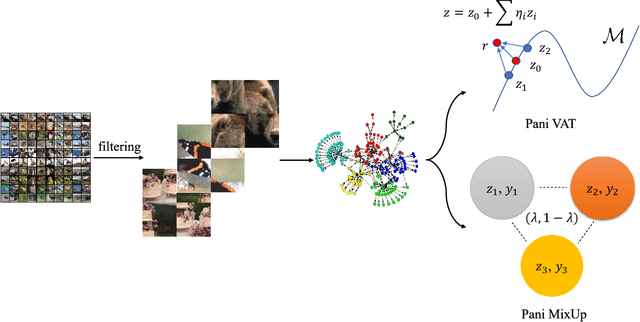

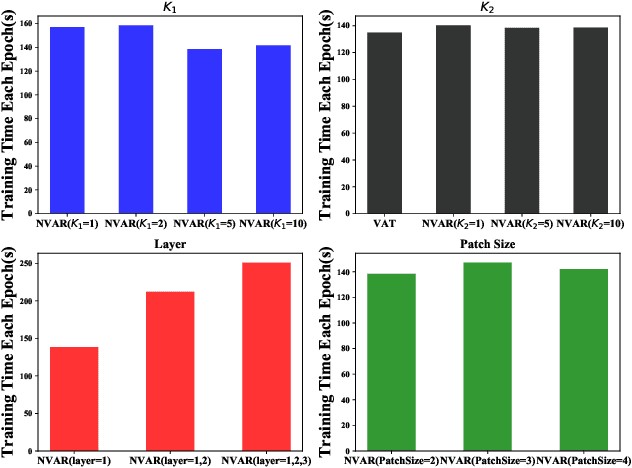
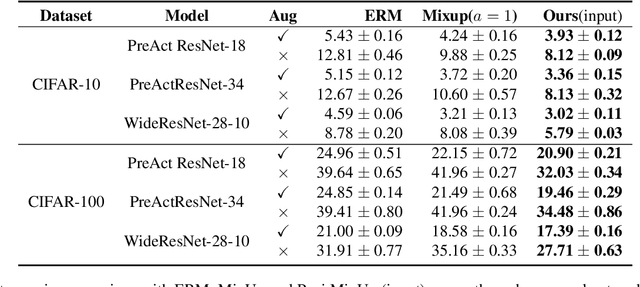
Regularization plays a crucial role in machine learning models, especially for deep neural networks. The existing regularization techniques mainly reply on the i.i.d. assumption and only employ the information of the current sample, without the leverage of neighboring information between samples. In this work, we propose a general regularizer called Patch-level Neighborhood Interpolation~(\textbf{Pani}) that fully exploits the relationship between samples. Furthermore, by explicitly constructing a patch-level graph in the different network layers and interpolating the neighborhood features to refine the representation of the current sample, our Patch-level Neighborhood Interpolation can then be applied to enhance two popular regularization strategies, namely Virtual Adversarial Training (VAT) and MixUp, yielding their neighborhood versions. The first derived \textbf{Pani VAT} presents a novel way to construct non-local adversarial smoothness by incorporating patch-level interpolated perturbations. In addition, the \textbf{Pani MixUp} method extends the original MixUp regularization to the patch level and then can be developed to MixMatch, achieving the state-of-the-art performance. Finally, extensive experiments are conducted to verify the effectiveness of the Patch-level Neighborhood Interpolation in both supervised and semi-supervised settings.
MLPerf Inference Benchmark
Nov 06, 2019
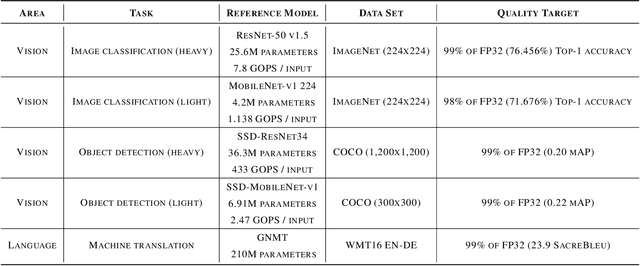
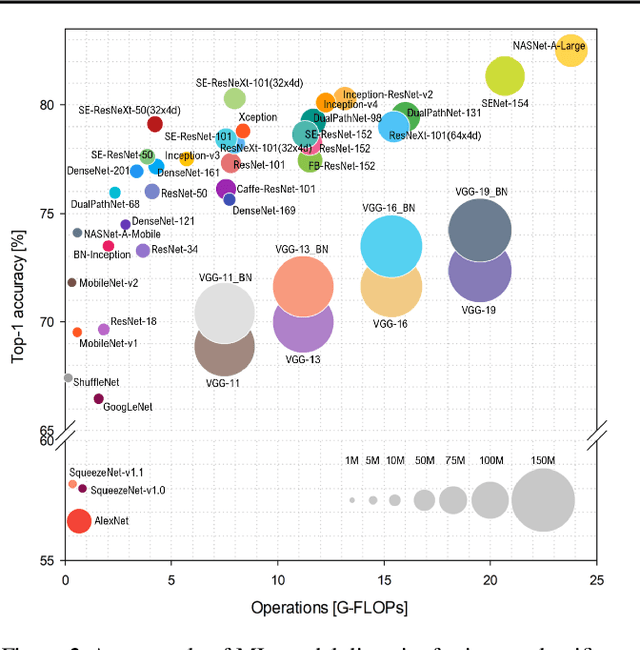
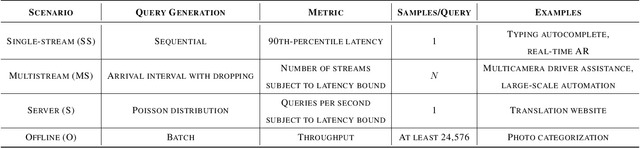
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.
On the Learning Dynamics of Two-layer Nonlinear Convolutional Neural Networks
May 24, 2019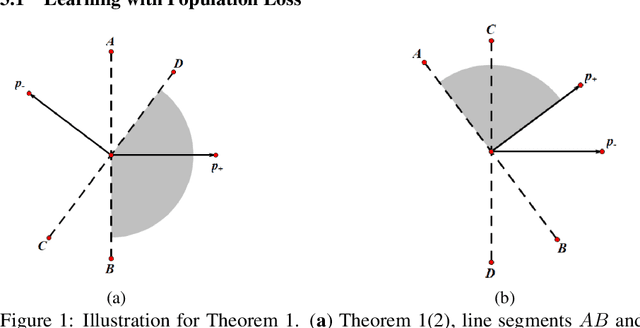
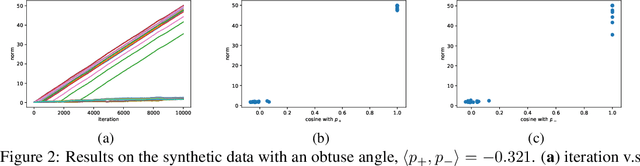
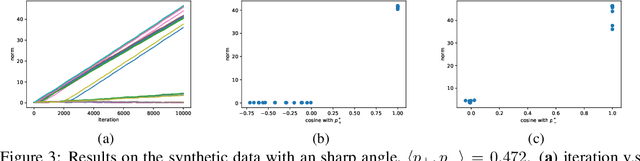

Convolutional neural networks (CNNs) have achieved remarkable performance in various fields, particularly in the domain of computer vision. However, why this architecture works well remains to be a mystery. In this work we move a small step toward understanding the success of CNNs by investigating the learning dynamics of a two-layer nonlinear convolutional neural network over some specific data distributions. Rather than the typical Gaussian assumption for input data distribution, we consider a more realistic setting that each data point (e.g. image) contains a specific pattern determining its class label. Within this setting, we both theoretically and empirically show that some convolutional filters will learn the key patterns in data and the norm of these filters will dominate during the training process with stochastic gradient descent. And with any high probability, when the number of iterations is sufficiently large, the CNN model could obtain 100% accuracy over the considered data distributions. Our experiments demonstrate that for practical image classification tasks our findings still hold to some extent.
ST-UNet: A Spatio-Temporal U-Network for Graph-structured Time Series Modeling
Mar 13, 2019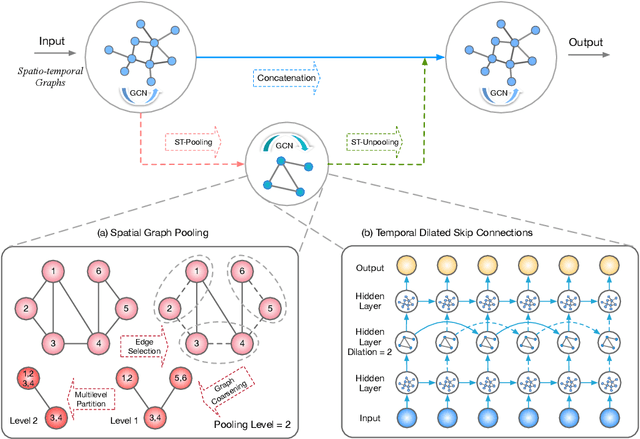
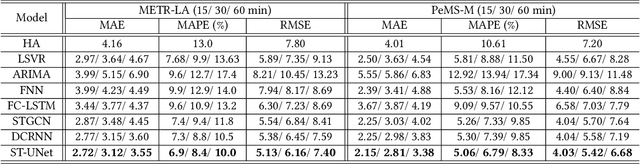
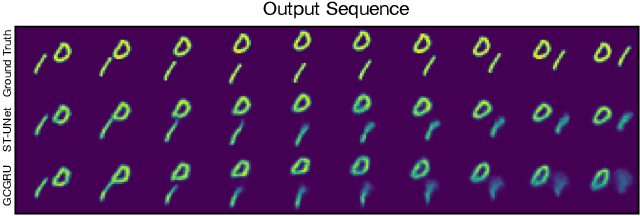
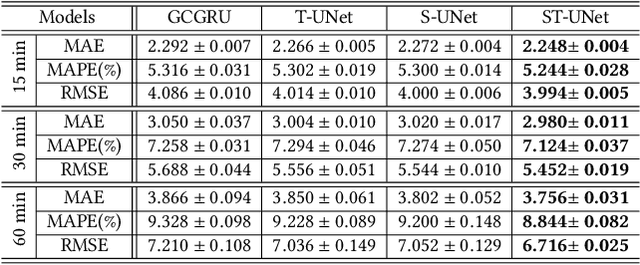
The spatio-temporal graph learning is becoming an increasingly important object of graph study. Many application domains involve highly dynamic graphs where temporal information is crucial, e.g. traffic networks and financial transaction graphs. Despite the constant progress made on learning structured data, there is still a lack of effective means to extract dynamic complex features from spatio-temporal structures. Particularly, conventional models such as convolutional networks or recurrent neural networks are incapable of revealing the temporal patterns in short or long terms and exploring the spatial properties in local or global scope from spatio-temporal graphs simultaneously. To tackle this problem, we design a novel multi-scale architecture, Spatio-Temporal U-Net (ST-UNet), for graph-structured time series modeling. In this U-shaped network, a paired sampling operation is proposed in spacetime domain accordingly: the pooling (ST-Pool) coarsens the input graph in spatial from its deterministic partition while abstracts multi-resolution temporal dependencies through dilated recurrent skip connections; based on previous settings in the downsampling, the unpooling (ST-Unpool) restores the original structure of spatio-temporal graphs and resumes regular intervals within graph sequences. Experiments on spatio-temporal prediction tasks demonstrate that our model effectively captures comprehensive features in multiple scales and achieves substantial improvements over mainstream methods on several real-world datasets.
3D Graph Convolutional Networks with Temporal Graphs: A Spatial Information Free Framework For Traffic Forecasting
Mar 03, 2019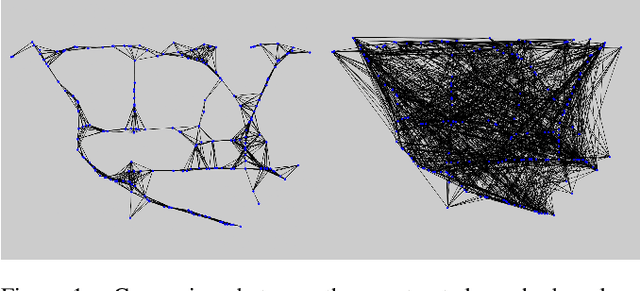
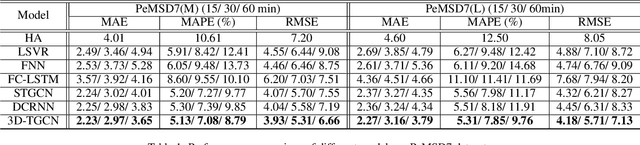
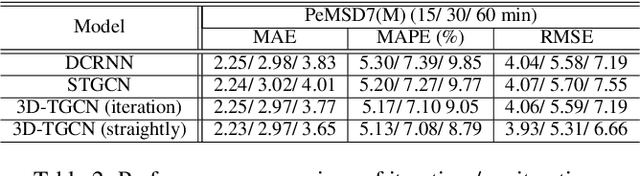
Spatio-temporal prediction plays an important role in many application areas especially in traffic domain. However, due to complicated spatio-temporal dependency and high non-linear dynamics in road networks, traffic prediction task is still challenging. Existing works either exhibit heavy training cost or fail to accurately capture the spatio-temporal patterns, also ignore the correlation between distant roads that share the similar patterns. In this paper, we propose a novel deep learning framework to overcome these issues: 3D Temporal Graph Convolutional Networks (3D-TGCN). Two novel components of our model are introduced. (1) Instead of constructing the road graph based on spatial information, we learn it by comparing the similarity between time series for each road, thus providing a spatial information free framework. (2) We propose an original 3D graph convolution model to model the spatio-temporal data more accurately. Empirical results show that 3D-TGCN could outperform state-of-the-art baselines.
Tangent-Normal Adversarial Regularization for Semi-supervised Learning
Aug 18, 2018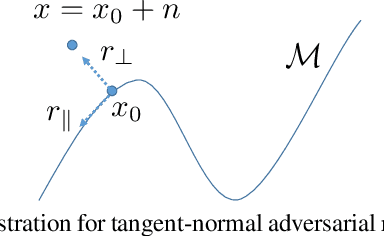
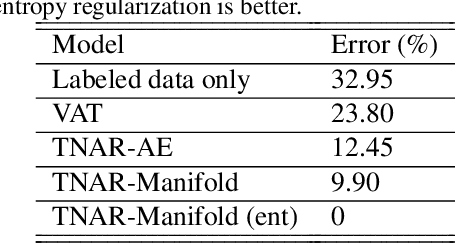

The ever-increasing size of modern datasets combined with the difficulty of obtaining label information has made semi-supervised learning of significant practical importance in modern machine learning applications. Compared with supervised learning, the key difficulty in semi-supervised learning is how to make full use of the unlabeled data. In order to utilize manifold information provided by unlabeled data, we propose a novel regularization called the tangent-normal adversarial regularization, which is composed by two parts. The two terms complement with each other and jointly enforce the smoothness along two different directions that are crucial for semi-supervised learning. One is applied along the tangent space of the data manifold, aiming to enforce local invariance of the classifier on the manifold, while the other is performed on the normal space orthogonal to the tangent space, intending to impose robustness on the classifier against the noise causing the observed data deviating from the underlying data manifold. Both of the two regularizers are achieved by the strategy of virtual adversarial training. Our method has achieved state-of-the-art performance on semi-supervised learning tasks on both artificial dataset and FashionMNIST dataset.
Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting
Jul 12, 2018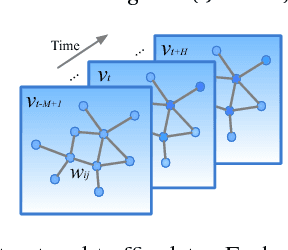
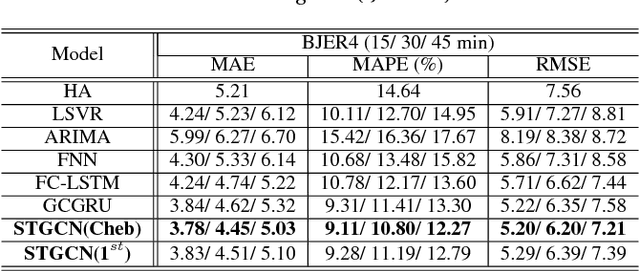
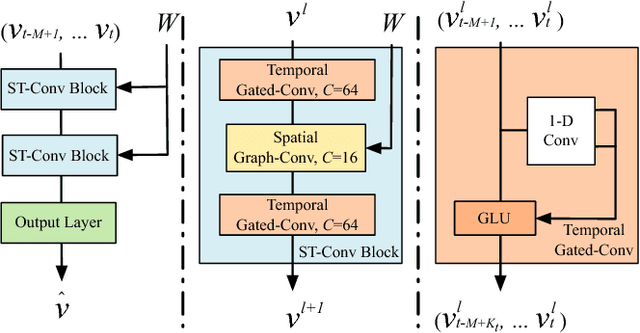
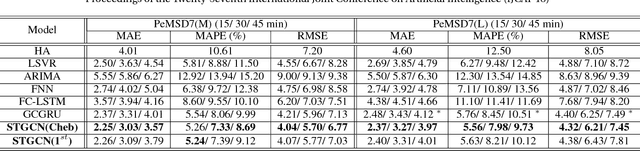
Timely accurate traffic forecast is crucial for urban traffic control and guidance. Due to the high nonlinearity and complexity of traffic flow, traditional methods cannot satisfy the requirements of mid-and-long term prediction tasks and often neglect spatial and temporal dependencies. In this paper, we propose a novel deep learning framework, Spatio-Temporal Graph Convolutional Networks (STGCN), to tackle the time series prediction problem in traffic domain. Instead of applying regular convolutional and recurrent units, we formulate the problem on graphs and build the model with complete convolutional structures, which enable much faster training speed with fewer parameters. Experiments show that our model STGCN effectively captures comprehensive spatio-temporal correlations through modeling multi-scale traffic networks and consistently outperforms state-of-the-art baselines on various real-world traffic datasets.
The Anisotropic Noise in Stochastic Gradient Descent: Its Behavior of Escaping from Minima and Regularization Effects
May 21, 2018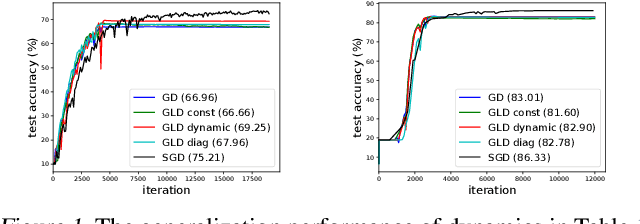

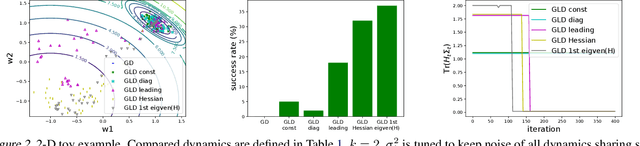
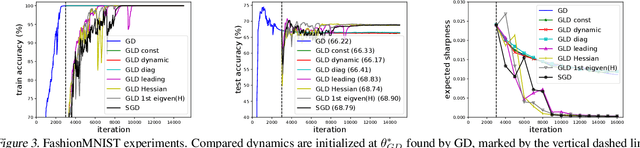
Understanding the behavior of stochastic gradient descent (SGD) in the context of deep neural networks has raised lots of concerns recently. Along this line, we theoretically study a general form of gradient based optimization dynamics with unbiased noise, which unifies SGD and standard Langevin dynamics. Through investigating this general optimization dynamics, we analyze the behavior of SGD on escaping from minima and its regularization effects. A novel indicator is derived to characterize the efficiency of escaping from minima through measuring the alignment of noise covariance and the curvature of loss function. Based on this indicator, two conditions are established to show which type of noise structure is superior to isotropic noise in term of escaping efficiency. We further show that the anisotropic noise in SGD satisfies the two conditions, and thus helps to escape from sharp and poor minima effectively, towards more stable and flat minima that typically generalize well. We verify our understanding through comparing this anisotropic diffusion with full gradient descent plus isotropic diffusion (i.e. Langevin dynamics) and other types of position-dependent noise.