 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhole-examination AI estimation of fetal biometrics from 20-week ultrasound scans
Jan 02, 2024The current approach to fetal anomaly screening is based on biometric measurements derived from individually selected ultrasound images. In this paper, we introduce a paradigm shift that attains human-level performance in biometric measurement by aggregating automatically extracted biometrics from every frame across an entire scan, with no need for operator intervention. We use a convolutional neural network to classify each frame of an ultrasound video recording. We then measure fetal biometrics in every frame where appropriate anatomy is visible. We use a Bayesian method to estimate the true value of each biometric from a large number of measurements and probabilistically reject outliers. We performed a retrospective experiment on 1457 recordings (comprising 48 million frames) of 20-week ultrasound scans, estimated fetal biometrics in those scans and compared our estimates to the measurements sonographers took during the scan. Our method achieves human-level performance in estimating fetal biometrics and estimates well-calibrated credible intervals in which the true biometric value is expected to lie.
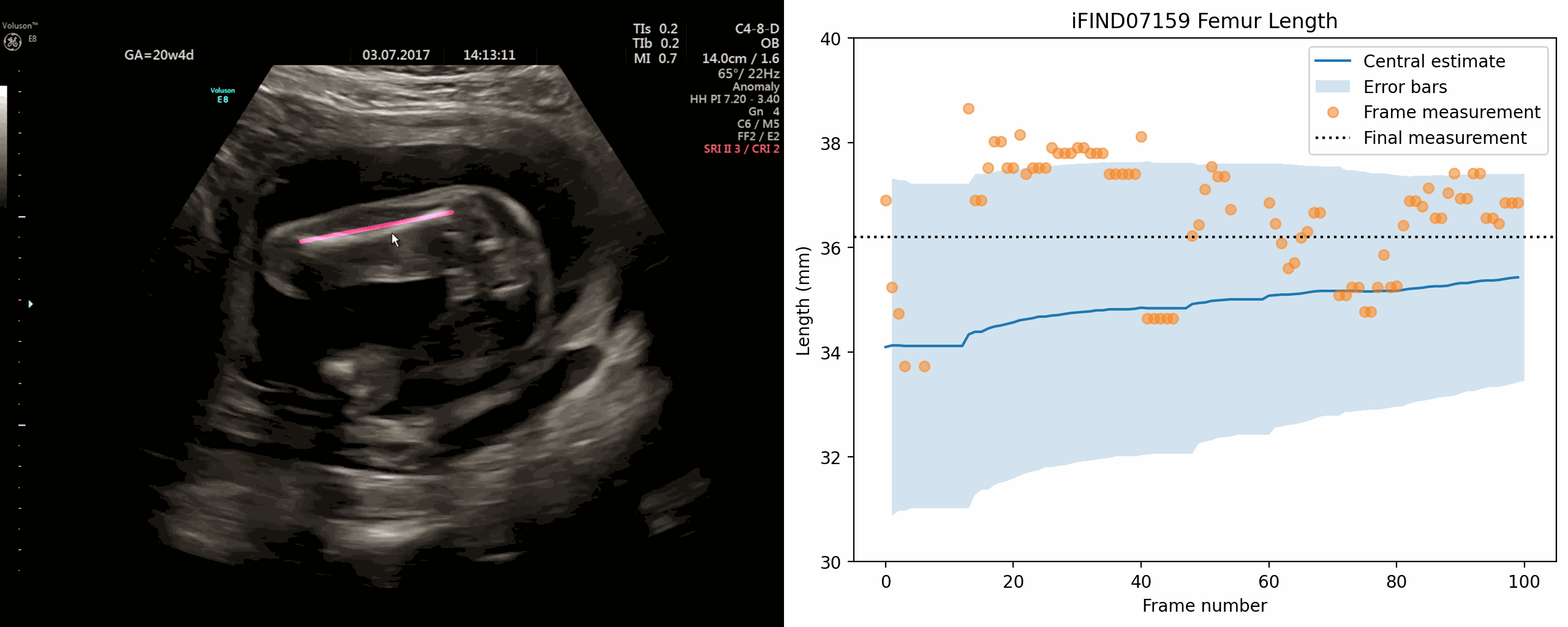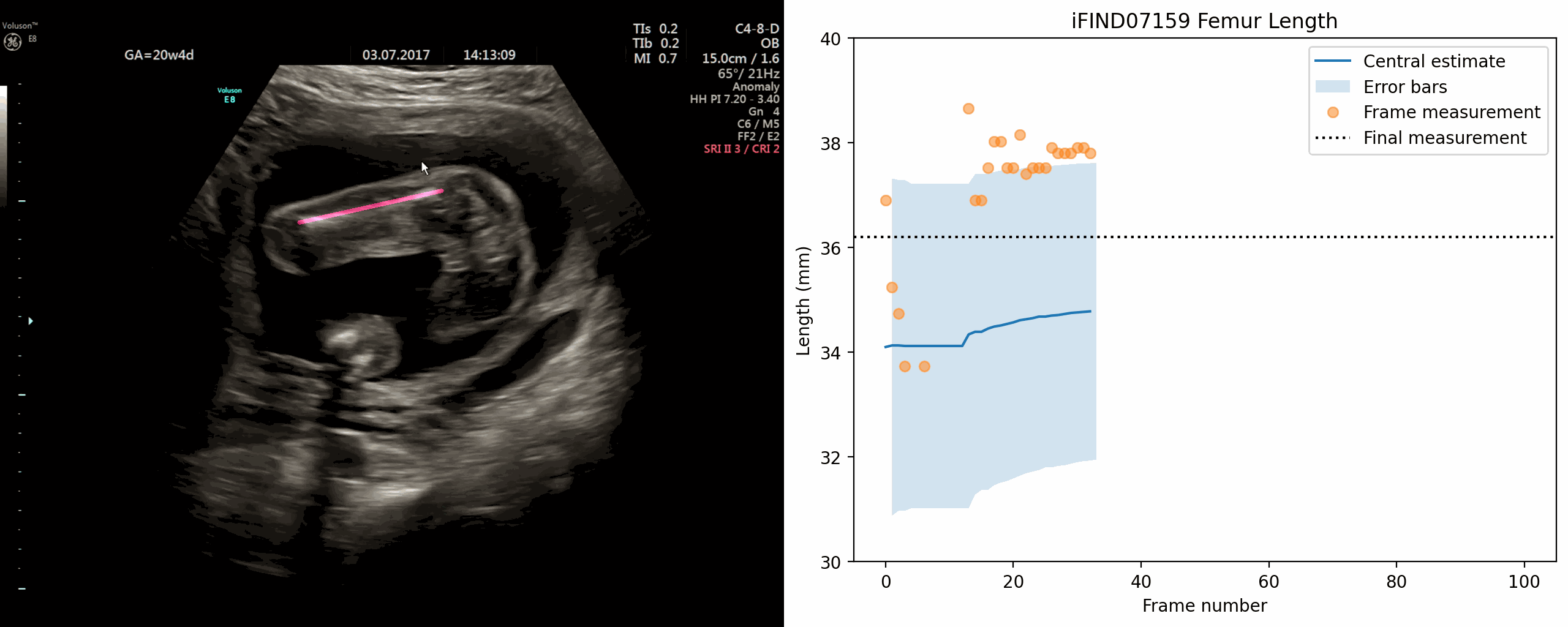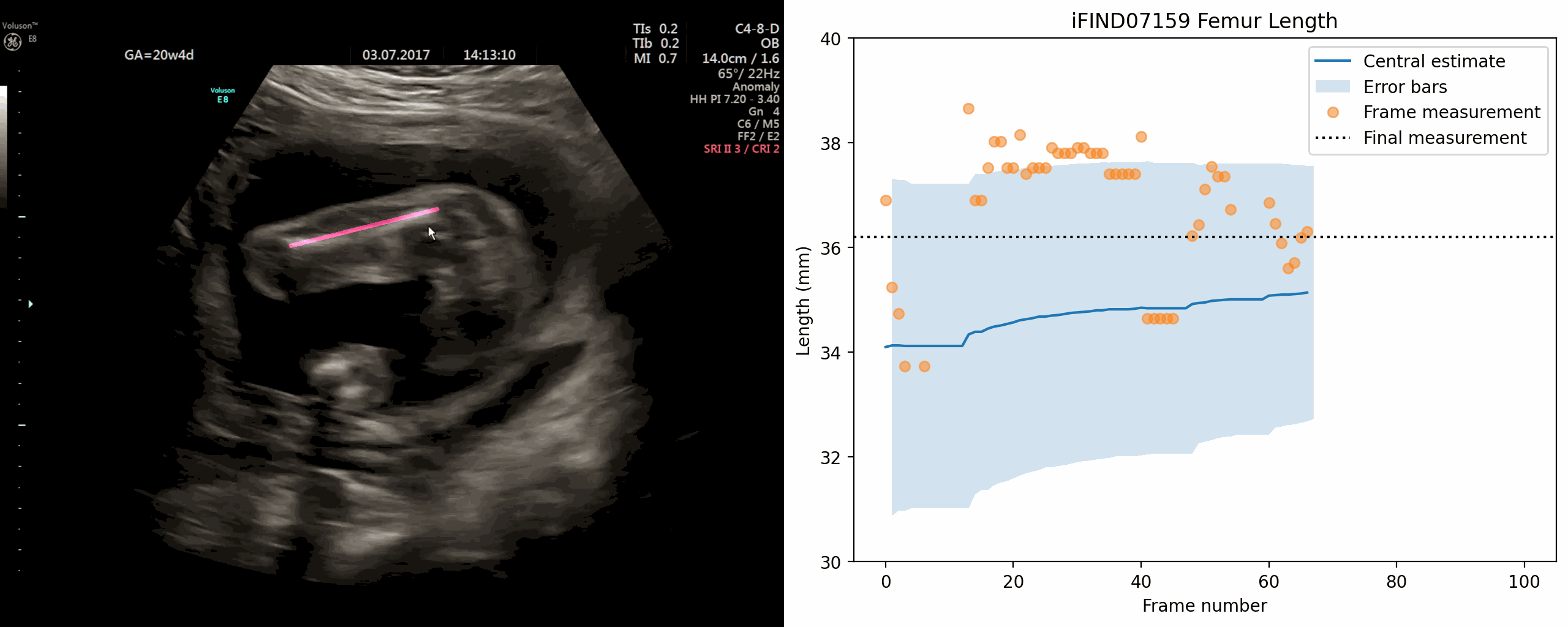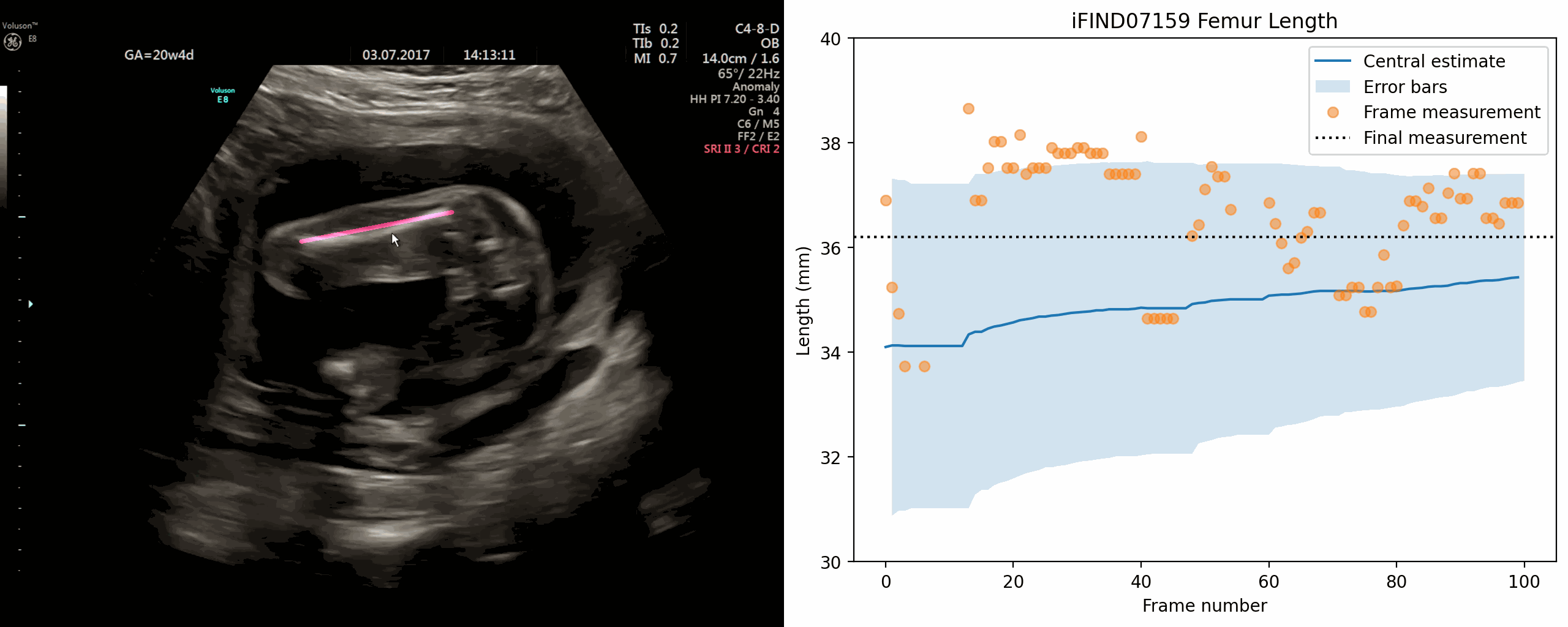{kind=link}
Ultra-Resolution Cascaded Diffusion Model for Gigapixel Image Synthesis in Histopathology
Dec 02, 2023


Diagnoses from histopathology images rely on information from both high and low resolutions of Whole Slide Images. Ultra-Resolution Cascaded Diffusion Models (URCDMs) allow for the synthesis of high-resolution images that are realistic at all magnification levels, focusing not only on fidelity but also on long-distance spatial coherency. Our model beats existing methods, improving the pFID-50k [2] score by 110.63 to 39.52 pFID-50k. Additionally, a human expert evaluation study was performed, reaching a weighted Mean Absolute Error (MAE) of 0.11 for the Lower Resolution Diffusion Models and a weighted MAE of 0.22 for the URCDM.
Stochastic Vision Transformers with Wasserstein Distance-Aware Attention
Nov 30, 2023



Self-supervised learning is one of the most promising approaches to acquiring knowledge from limited labeled data. Despite the substantial advancements made in recent years, self-supervised models have posed a challenge to practitioners, as they do not readily provide insight into the model's confidence and uncertainty. Tackling this issue is no simple feat, primarily due to the complexity involved in implementing techniques that can make use of the latent representations learned during pre-training without relying on explicit labels. Motivated by this, we introduce a new stochastic vision transformer that integrates uncertainty and distance awareness into self-supervised learning (SSL) pipelines. Instead of the conventional deterministic vector embedding, our novel stochastic vision transformer encodes image patches into elliptical Gaussian distributional embeddings. Notably, the attention matrices of these stochastic representational embeddings are computed using Wasserstein distance-based attention, effectively capitalizing on the distributional nature of these embeddings. Additionally, we propose a regularization term based on Wasserstein distance for both pre-training and fine-tuning processes, thereby incorporating distance awareness into latent representations. We perform extensive experiments across different tasks such as in-distribution generalization, out-of-distribution detection, dataset corruption, semi-supervised settings, and transfer learning to other datasets and tasks. Our proposed method achieves superior accuracy and calibration, surpassing the self-supervised baseline in a wide range of experiments on a variety of datasets.
DISYRE: Diffusion-Inspired SYnthetic REstoration for Unsupervised Anomaly Detection
Nov 26, 2023



Unsupervised Anomaly Detection (UAD) techniques aim to identify and localize anomalies without relying on annotations, only leveraging a model trained on a dataset known to be free of anomalies. Diffusion models learn to modify inputs $x$ to increase the probability of it belonging to a desired distribution, i.e., they model the score function $\nabla_x \log p(x)$. Such a score function is potentially relevant for UAD, since $\nabla_x \log p(x)$ is itself a pixel-wise anomaly score. However, diffusion models are trained to invert a corruption process based on Gaussian noise and the learned score function is unlikely to generalize to medical anomalies. This work addresses the problem of how to learn a score function relevant for UAD and proposes DISYRE: Diffusion-Inspired SYnthetic REstoration. We retain the diffusion-like pipeline but replace the Gaussian noise corruption with a gradual, synthetic anomaly corruption so the learned score function generalizes to medical, naturally occurring anomalies. We evaluate DISYRE on three common Brain MRI UAD benchmarks and substantially outperform other methods in two out of the three tasks.
Exploring the Hyperparameter Space of Image Diffusion Models for Echocardiogram Generation
Nov 02, 2023This work presents an extensive hyperparameter search on Image Diffusion Models for Echocardiogram generation. The objective is to establish foundational benchmarks and provide guidelines within the realm of ultrasound image and video generation. This study builds over the latest advancements, including cutting-edge model architectures and training methodologies. We also examine the distribution shift between real and generated samples and consider potential solutions, crucial to train efficient models on generated data. We determine an Optimal FID score of $0.88$ for our research problem and achieve an FID of $2.60$. This work is aimed at contributing valuable insights and serving as a reference for further developments in the specialized field of ultrasound image and video generation.
Whole Slide Multiple Instance Learning for Predicting Axillary Lymph Node Metastasis
Oct 06, 2023Breast cancer is a major concern for women's health globally, with axillary lymph node (ALN) metastasis identification being critical for prognosis evaluation and treatment guidance. This paper presents a deep learning (DL) classification pipeline for quantifying clinical information from digital core-needle biopsy (CNB) images, with one step less than existing methods. A publicly available dataset of 1058 patients was used to evaluate the performance of different baseline state-of-the-art (SOTA) DL models in classifying ALN metastatic status based on CNB images. An extensive ablation study of various data augmentation techniques was also conducted. Finally, the manual tumor segmentation and annotation step performed by the pathologists was assessed.
* Accepted for MICCAI DEMI Workshop 2023
Sculpting Efficiency: Pruning Medical Imaging Models for On-Device Inference
Sep 10, 2023Applying ML advancements to healthcare can improve patient outcomes. However, the sheer operational complexity of ML models, combined with legacy hardware and multi-modal gigapixel images, poses a severe deployment limitation for real-time, on-device inference. We consider filter pruning as a solution, exploring segmentation models in cardiology and ophthalmology. Our preliminary results show a compression rate of up to 1148x with minimal loss in quality, stressing the need to consider task complexity and architectural details when using off-the-shelf models. At high compression rates, filter-pruned models exhibit faster inference on a CPU than the GPU baseline. We also demonstrate that such models' robustness and generalisability characteristics exceed that of the baseline and weight-pruned counterparts. We uncover intriguing questions and take a step towards realising cost-effective disease diagnosis, monitoring, and preventive solutions.
LesionMix: A Lesion-Level Data Augmentation Method for Medical Image Segmentation
Aug 17, 2023



Data augmentation has become a de facto component of deep learning-based medical image segmentation methods. Most data augmentation techniques used in medical imaging focus on spatial and intensity transformations to improve the diversity of training images. They are often designed at the image level, augmenting the full image, and do not pay attention to specific abnormalities within the image. Here, we present LesionMix, a novel and simple lesion-aware data augmentation method. It performs augmentation at the lesion level, increasing the diversity of lesion shape, location, intensity and load distribution, and allowing both lesion populating and inpainting. Experiments on different modalities and different lesion datasets, including four brain MR lesion datasets and one liver CT lesion dataset, demonstrate that LesionMix achieves promising performance in lesion image segmentation, outperforming several recent Mix-based data augmentation methods. The code will be released at https://github.com/dogabasaran/lesionmix.
Conditional Temporal Attention Networks for Neonatal Cortical Surface Reconstruction
Jul 21, 2023Cortical surface reconstruction plays a fundamental role in modeling the rapid brain development during the perinatal period. In this work, we propose Conditional Temporal Attention Network (CoTAN), a fast end-to-end framework for diffeomorphic neonatal cortical surface reconstruction. CoTAN predicts multi-resolution stationary velocity fields (SVF) from neonatal brain magnetic resonance images (MRI). Instead of integrating multiple SVFs, CoTAN introduces attention mechanisms to learn a conditional time-varying velocity field (CTVF) by computing the weighted sum of all SVFs at each integration step. The importance of each SVF, which is estimated by learned attention maps, is conditioned on the age of the neonates and varies with the time step of integration. The proposed CTVF defines a diffeomorphic surface deformation, which reduces mesh self-intersection errors effectively. It only requires 0.21 seconds to deform an initial template mesh to cortical white matter and pial surfaces for each brain hemisphere. CoTAN is validated on the Developing Human Connectome Project (dHCP) dataset with 877 3D brain MR images acquired from preterm and term born neonates. Compared to state-of-the-art baselines, CoTAN achieves superior performance with only 0.12mm geometric error and 0.07% self-intersecting faces. The visualization of our attention maps illustrates that CoTAN indeed learns coarse-to-fine surface deformations automatically without intermediate supervision.
Many tasks make light work: Learning to localise medical anomalies from multiple synthetic tasks
Jul 03, 2023There is a growing interest in single-class modelling and out-of-distribution detection as fully supervised machine learning models cannot reliably identify classes not included in their training. The long tail of infinitely many out-of-distribution classes in real-world scenarios, e.g., for screening, triage, and quality control, means that it is often necessary to train single-class models that represent an expected feature distribution, e.g., from only strictly healthy volunteer data. Conventional supervised machine learning would require the collection of datasets that contain enough samples of all possible diseases in every imaging modality, which is not realistic. Self-supervised learning methods with synthetic anomalies are currently amongst the most promising approaches, alongside generative auto-encoders that analyse the residual reconstruction error. However, all methods suffer from a lack of structured validation, which makes calibration for deployment difficult and dataset-dependant. Our method alleviates this by making use of multiple visually-distinct synthetic anomaly learning tasks for both training and validation. This enables more robust training and generalisation. With our approach we can readily outperform state-of-the-art methods, which we demonstrate on exemplars in brain MRI and chest X-rays. Code is available at https://github.com/matt-baugh/many-tasks-make-light-work .