 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurDB: On the Design and Implementation of an AI-powered Autonomous Database
Aug 06, 2024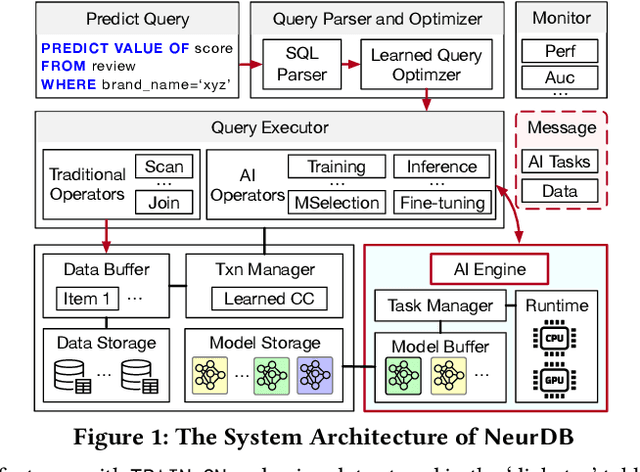
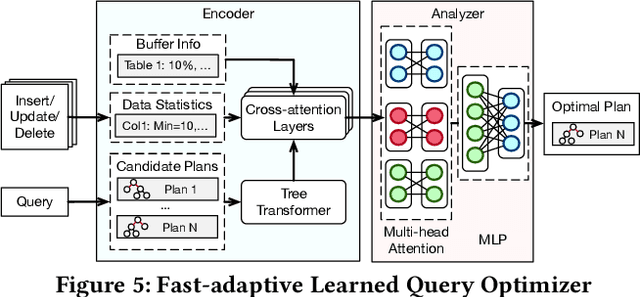
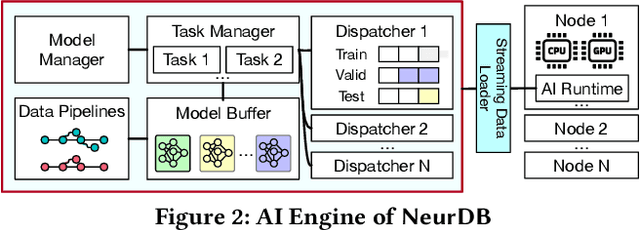
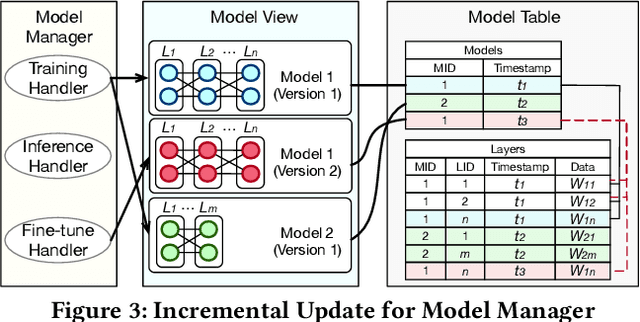
Databases are increasingly embracing AI to provide autonomous system optimization and intelligent in-database analytics, aiming to relieve end-user burdens across various industry sectors. Nonetheless, most existing approaches fail to account for the dynamic nature of databases, which renders them ineffective for real-world applications characterized by evolving data and workloads. This paper introduces NeurDB, an AI-powered autonomous database that deepens the fusion of AI and databases with adaptability to data and workload drift. NeurDB establishes a new in-database AI ecosystem that seamlessly integrates AI workflows within the database. This integration enables efficient and effective in-database AI analytics and fast-adaptive learned system components. Empirical evaluations demonstrate that NeurDB substantially outperforms existing solutions in managing AI analytics tasks, with the proposed learned components more effectively handling environmental dynamism than state-of-the-art approaches.
VecAug: Unveiling Camouflaged Frauds with Cohort Augmentation for Enhanced Detection
Aug 01, 2024



Fraud detection presents a challenging task characterized by ever-evolving fraud patterns and scarce labeled data. Existing methods predominantly rely on graph-based or sequence-based approaches. While graph-based approaches connect users through shared entities to capture structural information, they remain vulnerable to fraudsters who can disrupt or manipulate these connections. In contrast, sequence-based approaches analyze users' behavioral patterns, offering robustness against tampering but overlooking the interactions between similar users. Inspired by cohort analysis in retention and healthcare, this paper introduces VecAug, a novel cohort-augmented learning framework that addresses these challenges by enhancing the representation learning of target users with personalized cohort information. To this end, we first propose a vector burn-in technique for automatic cohort identification, which retrieves a task-specific cohort for each target user. Then, to fully exploit the cohort information, we introduce an attentive cohort aggregation technique for augmenting target user representations. To improve the robustness of such cohort augmentation, we also propose a novel label-aware cohort neighbor separation mechanism to distance negative cohort neighbors and calibrate the aggregated cohort information. By integrating this cohort information with target user representations, VecAug enhances the modeling capacity and generalization capabilities of the model to be augmented. Our framework is flexible and can be seamlessly integrated with existing fraud detection models. We deploy our framework on e-commerce platforms and evaluate it on three fraud detection datasets, and results show that VecAug improves the detection performance of base models by up to 2.48\% in AUC and 22.5\% in R@P$_{0.9}$, outperforming state-of-the-art methods significantly.
CohortNet: Empowering Cohort Discovery for Interpretable Healthcare Analytics
Jun 20, 2024Cohort studies are of significant importance in the field of healthcare analysis. However, existing methods typically involve manual, labor-intensive, and expert-driven pattern definitions or rely on simplistic clustering techniques that lack medical relevance. Automating cohort studies with interpretable patterns has great potential to facilitate healthcare analysis but remains an unmet need in prior research efforts. In this paper, we propose a cohort auto-discovery model, CohortNet, for interpretable healthcare analysis, focusing on the effective identification, representation, and exploitation of cohorts characterized by medically meaningful patterns. CohortNet initially learns fine-grained patient representations by separately processing each feature, considering both individual feature trends and feature interactions at each time step. Subsequently, it classifies each feature into distinct states and employs a heuristic cohort exploration strategy to effectively discover substantial cohorts with concrete patterns. For each identified cohort, it learns comprehensive cohort representations with credible evidence through associated patient retrieval. Ultimately, given a new patient, CohortNet can leverage relevant cohorts with distinguished importance, which can provide a more holistic understanding of the patient's conditions. Extensive experiments on three real-world datasets demonstrate that it consistently outperforms state-of-the-art approaches and offers interpretable insights from diverse perspectives in a top-down fashion.
NeurDB: An AI-powered Autonomous Data System
May 07, 2024In the wake of rapid advancements in artificial intelligence (AI), we stand on the brink of a transformative leap in data systems. The imminent fusion of AI and DB (AIxDB) promises a new generation of data systems, which will relieve the burden on end-users across all industry sectors by featuring AI-enhanced functionalities, such as personalized and automated in-database AI-powered analytics, self-driving capabilities for improved system performance, etc. In this paper, we explore the evolution of data systems with a focus on deepening the fusion of AI and DB. We present NeurDB, our next-generation data system designed to fully embrace AI design in each major system component and provide in-database AI-powered analytics. We outline the conceptual and architectural overview of NeurDB, discuss its design choices and key components, and report its current development and future plan.
Powering In-Database Dynamic Model Slicing for Structured Data Analytics
May 01, 2024



Relational database management systems (RDBMS) are widely used for the storage and retrieval of structured data. To derive insights beyond statistical aggregation, we typically have to extract specific subdatasets from the database using conventional database operations, and then apply deep neural networks (DNN) training and inference on these respective subdatasets in a separate machine learning system. The process can be prohibitively expensive, especially when there are a combinatorial number of subdatasets extracted for different analytical purposes. This calls for efficient in-database support of advanced analytical methods In this paper, we introduce LEADS, a novel SQL-aware dynamic model slicing technique to customize models for subdatasets specified by SQL queries. LEADS improves the predictive modeling of structured data via the mixture of experts (MoE) technique and maintains inference efficiency by a SQL-aware gating network. At the core of LEADS is the construction of a general model with multiple expert sub-models via MoE trained over the entire database. This SQL-aware MoE technique scales up the modeling capacity, enhances effectiveness, and preserves efficiency by activating only necessary experts via the gating network during inference. Additionally, we introduce two regularization terms during the training process of LEADS to strike a balance between effectiveness and efficiency. We also design and build an in-database inference system, called INDICES, to support end-to-end advanced structured data analytics by non-intrusively incorporating LEADS onto PostgreSQL. Our extensive experiments on real-world datasets demonstrate that LEADS consistently outperforms baseline models, and INDICES delivers effective in-database analytics with a considerable reduction in inference latency compared to traditional solutions.
Exploring Privacy and Fairness Risks in Sharing Diffusion Models: An Adversarial Perspective
Mar 04, 2024



Diffusion models have recently gained significant attention in both academia and industry due to their impressive generative performance in terms of both sampling quality and distribution coverage. Accordingly, proposals are made for sharing pre-trained diffusion models across different organizations, as a way of improving data utilization while enhancing privacy protection by avoiding sharing private data directly. However, the potential risks associated with such an approach have not been comprehensively examined. In this paper, we take an adversarial perspective to investigate the potential privacy and fairness risks associated with the sharing of diffusion models. Specifically, we investigate the circumstances in which one party (the sharer) trains a diffusion model using private data and provides another party (the receiver) black-box access to the pre-trained model for downstream tasks. We demonstrate that the sharer can execute fairness poisoning attacks to undermine the receiver's downstream models by manipulating the training data distribution of the diffusion model. Meanwhile, the receiver can perform property inference attacks to reveal the distribution of sensitive features in the sharer's dataset. Our experiments conducted on real-world datasets demonstrate remarkable attack performance on different types of diffusion models, which highlights the critical importance of robust data auditing and privacy protection protocols in pertinent applications.
METER: A Dynamic Concept Adaptation Framework for Online Anomaly Detection
Dec 28, 2023



Real-time analytics and decision-making require online anomaly detection (OAD) to handle drifts in data streams efficiently and effectively. Unfortunately, existing approaches are often constrained by their limited detection capacity and slow adaptation to evolving data streams, inhibiting their efficacy and efficiency in handling concept drift, which is a major challenge in evolving data streams. In this paper, we introduce METER, a novel dynamic concept adaptation framework that introduces a new paradigm for OAD. METER addresses concept drift by first training a base detection model on historical data to capture recurring central concepts, and then learning to dynamically adapt to new concepts in data streams upon detecting concept drift. Particularly, METER employs a novel dynamic concept adaptation technique that leverages a hypernetwork to dynamically generate the parameter shift of the base detection model, providing a more effective and efficient solution than conventional retraining or fine-tuning approaches. Further, METER incorporates a lightweight drift detection controller, underpinned by evidential deep learning, to support robust and interpretable concept drift detection. We conduct an extensive experimental evaluation, and the results show that METER significantly outperforms existing OAD approaches in various application scenarios.
Secure and Verifiable Data Collaboration with Low-Cost Zero-Knowledge Proofs
Nov 26, 2023



Organizations are increasingly recognizing the value of data collaboration for data analytics purposes. Yet, stringent data protection laws prohibit the direct exchange of raw data. To facilitate data collaboration, federated Learning (FL) emerges as a viable solution, which enables multiple clients to collaboratively train a machine learning (ML) model under the supervision of a central server while ensuring the confidentiality of their raw data. However, existing studies have unveiled two main risks: (i) the potential for the server to infer sensitive information from the client's uploaded updates (i.e., model gradients), compromising client input privacy, and (ii) the risk of malicious clients uploading malformed updates to poison the FL model, compromising input integrity. Recent works utilize secure aggregation with zero-knowledge proofs (ZKP) to guarantee input privacy and integrity in FL. Nevertheless, they suffer from extremely low efficiency and, thus, are impractical for real deployment. In this paper, we propose a novel and highly efficient solution RiseFL for secure and verifiable data collaboration, ensuring input privacy and integrity simultaneously.Firstly, we devise a probabilistic integrity check method that significantly reduces the cost of ZKP generation and verification. Secondly, we design a hybrid commitment scheme to satisfy Byzantine robustness with improved performance. Thirdly, we theoretically prove the security guarantee of the proposed solution. Extensive experiments on synthetic and real-world datasets suggest that our solution is effective and is highly efficient in both client computation and communication. For instance, RiseFL is up to 28x, 53x and 164x faster than three state-of-the-art baselines ACORN, RoFL and EIFFeL for the client computation.
Passive Inference Attacks on Split Learning via Adversarial Regularization
Oct 16, 2023



Split Learning (SL) has emerged as a practical and efficient alternative to traditional federated learning. While previous attempts to attack SL have often relied on overly strong assumptions or targeted easily exploitable models, we seek to develop more practical attacks. We introduce SDAR, a novel attack framework against SL with an honest-but-curious server. SDAR leverages auxiliary data and adversarial regularization to learn a decodable simulator of the client's private model, which can effectively infer the client's private features under the vanilla SL, and both features and labels under the U-shaped SL. We perform extensive experiments in both configurations to validate the effectiveness of our proposed attacks. Notably, in challenging but practical scenarios where existing passive attacks struggle to reconstruct the client's private data effectively, SDAR consistently achieves attack performance comparable to active attacks. On CIFAR-10, at the deep split level of 7, SDAR achieves private feature reconstruction with less than 0.025 mean squared error in both the vanilla and the U-shaped SL, and attains a label inference accuracy of over 98% in the U-shaped setting, while existing attacks fail to produce non-trivial results.
Learning in Imperfect Environment: Multi-Label Classification with Long-Tailed Distribution and Partial Labels
Apr 20, 2023Conventional multi-label classification (MLC) methods assume that all samples are fully labeled and identically distributed. Unfortunately, this assumption is unrealistic in large-scale MLC data that has long-tailed (LT) distribution and partial labels (PL). To address the problem, we introduce a novel task, Partial labeling and Long-Tailed Multi-Label Classification (PLT-MLC), to jointly consider the above two imperfect learning environments. Not surprisingly, we find that most LT-MLC and PL-MLC approaches fail to solve the PLT-MLC, resulting in significant performance degradation on the two proposed PLT-MLC benchmarks. Therefore, we propose an end-to-end learning framework: \textbf{CO}rrection $\rightarrow$ \textbf{M}odificat\textbf{I}on $\rightarrow$ balan\textbf{C}e, abbreviated as \textbf{\method{}}. Our bootstrapping philosophy is to simultaneously correct the missing labels (Correction) with convinced prediction confidence over a class-aware threshold and to learn from these recall labels during training. We next propose a novel multi-focal modifier loss that simultaneously addresses head-tail imbalance and positive-negative imbalance to adaptively modify the attention to different samples (Modification) under the LT class distribution. In addition, we develop a balanced training strategy by distilling the model's learning effect from head and tail samples, and thus design a balanced classifier (Balance) conditioned on the head and tail learning effect to maintain stable performance for all samples. Our experimental study shows that the proposed \method{} significantly outperforms general MLC, LT-MLC and PL-MLC methods in terms of effectiveness and robustness on our newly created PLT-MLC datasets.