 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnobserved Local Structures Make Compositional Generalization Hard
Jan 15, 2022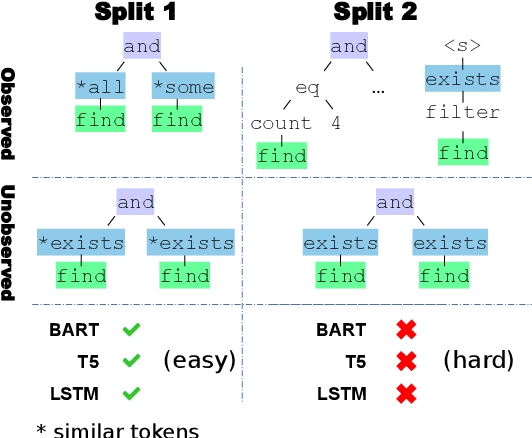

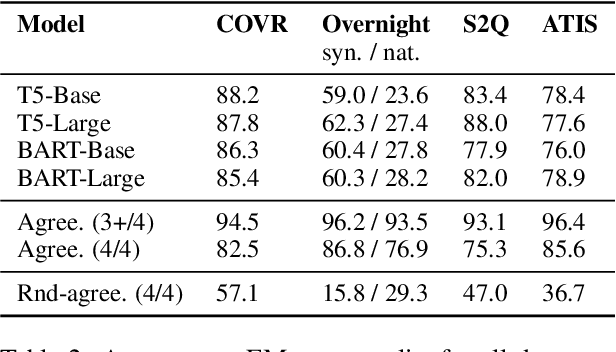
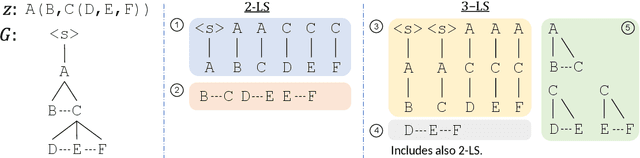
While recent work has convincingly showed that sequence-to-sequence models struggle to generalize to new compositions (termed compositional generalization), little is known on what makes compositional generalization hard on a particular test instance. In this work, we investigate what are the factors that make generalization to certain test instances challenging. We first substantiate that indeed some examples are more difficult than others by showing that different models consistently fail or succeed on the same test instances. Then, we propose a criterion for the difficulty of an example: a test instance is hard if it contains a local structure that was not observed at training time. We formulate a simple decision rule based on this criterion and empirically show it predicts instance-level generalization well across 5 different semantic parsing datasets, substantially better than alternative decision rules. Last, we show local structures can be leveraged for creating difficult adversarial compositional splits and also to improve compositional generalization under limited training budgets by strategically selecting examples for the training set.
COVR: A test-bed for Visually Grounded Compositional Generalization with real images
Sep 22, 2021
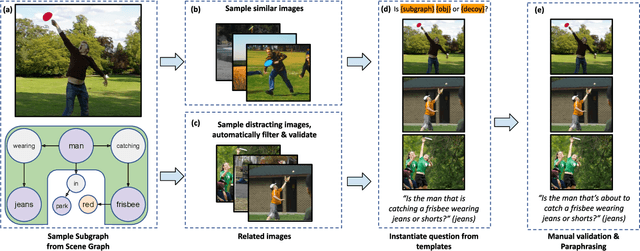
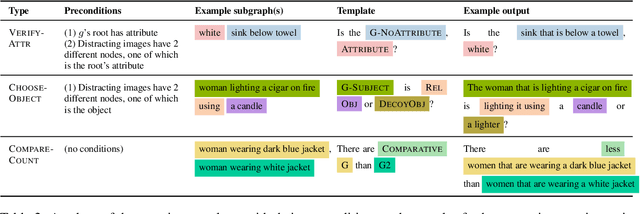
While interest in models that generalize at test time to new compositions has risen in recent years, benchmarks in the visually-grounded domain have thus far been restricted to synthetic images. In this work, we propose COVR, a new test-bed for visually-grounded compositional generalization with real images. To create COVR, we use real images annotated with scene graphs, and propose an almost fully automatic procedure for generating question-answer pairs along with a set of context images. COVR focuses on questions that require complex reasoning, including higher-order operations such as quantification and aggregation. Due to the automatic generation process, COVR facilitates the creation of compositional splits, where models at test time need to generalize to new concepts and compositions in a zero- or few-shot setting. We construct compositional splits using COVR and demonstrate a myriad of cases where state-of-the-art pre-trained language-and-vision models struggle to compositionally generalize.
Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
Jun 09, 2021
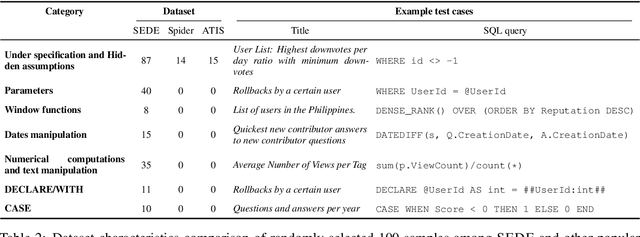
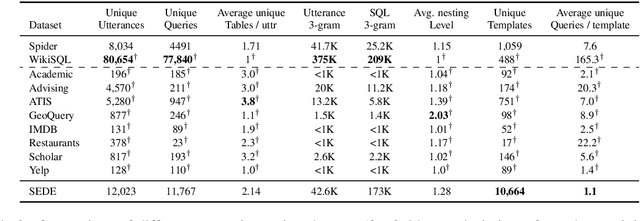
Most available semantic parsing datasets, comprising of pairs of natural utterances and logical forms, were collected solely for the purpose of training and evaluation of natural language understanding systems. As a result, they do not contain any of the richness and variety of natural-occurring utterances, where humans ask about data they need or are curious about. In this work, we release SEDE, a dataset with 12,023 pairs of utterances and SQL queries collected from real usage on the Stack Exchange website. We show that these pairs contain a variety of real-world challenges which were rarely reflected so far in any other semantic parsing dataset, propose an evaluation metric based on comparison of partial query clauses that is more suitable for real-world queries, and conduct experiments with strong baselines, showing a large gap between the performance on SEDE compared to other common datasets.
MedICaT: A Dataset of Medical Images, Captions, and Textual References
Oct 12, 2020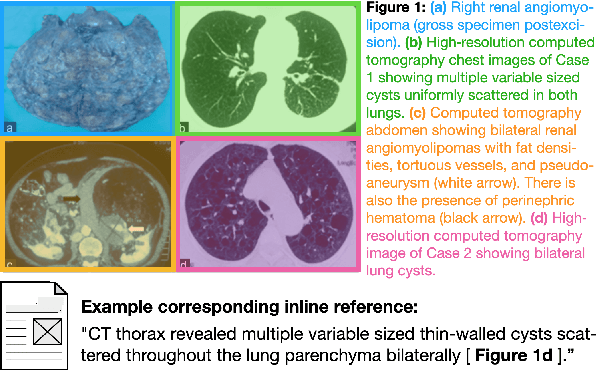

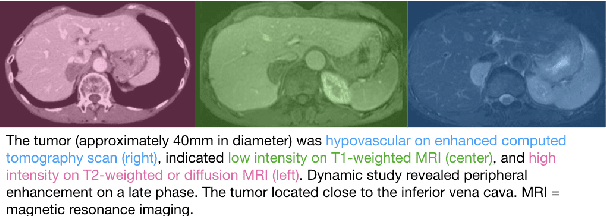
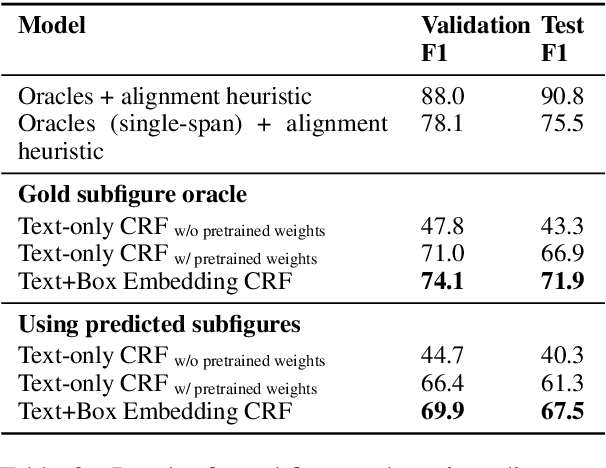
Understanding the relationship between figures and text is key to scientific document understanding. Medical figures in particular are quite complex, often consisting of several subfigures (75% of figures in our dataset), with detailed text describing their content. Previous work studying figures in scientific papers focused on classifying figure content rather than understanding how images relate to the text. To address challenges in figure retrieval and figure-to-text alignment, we introduce MedICaT, a dataset of medical images in context. MedICaT consists of 217K images from 131K open access biomedical papers, and includes captions, inline references for 74% of figures, and manually annotated subfigures and subcaptions for a subset of figures. Using MedICaT, we introduce the task of subfigure to subcaption alignment in compound figures and demonstrate the utility of inline references in image-text matching. Our data and code can be accessed at https://github.com/allenai/medicat.
Latent Compositional Representations Improve Systematic Generalization in Grounded Question Answering
Jul 01, 2020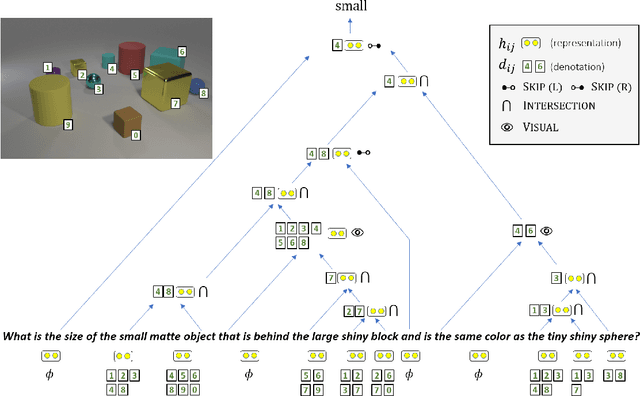


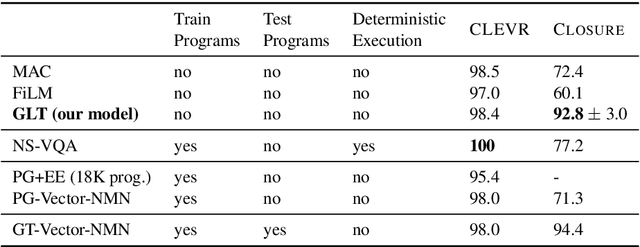
Answering questions that involve multi-step reasoning requires decomposing them and using the answers of intermediate steps to reach the final answer. However, state-of-the-art models in grounded question answering often do not explicitly perform decomposition, leading to difficulties in generalization to out-of-distribution examples. In this work, we propose a model that computes a representation and denotation for all question spans in a bottom-up, compositional manner using a CKY-style parser. Our model effectively induces latent trees, driven by end-to-end (the answer) supervision only. We show that this inductive bias towards tree structures dramatically improves systematic generalization to out-of-distribution examples compared to strong baselines on an arithmetic expressions benchmark as well as on CLOSURE, a dataset that focuses on systematic generalization of models for grounded question answering. On this challenging dataset, our model reaches an accuracy of 92.8%, significantly higher than prior models that almost perfectly solve the task on a random, in-distribution split.
Obtaining Faithful Interpretations from Compositional Neural Networks
May 02, 2020
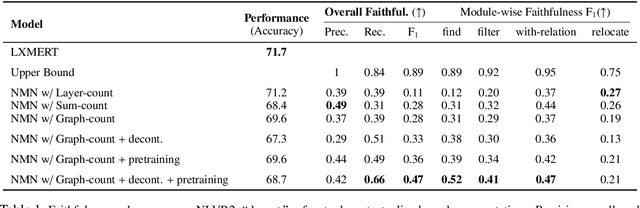
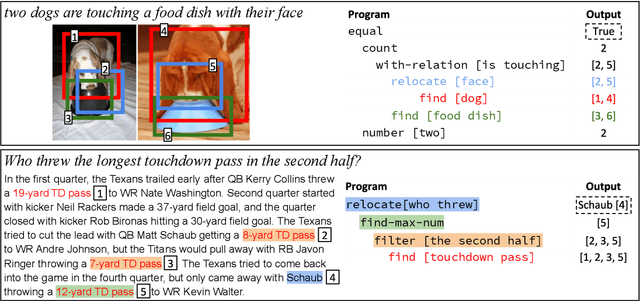
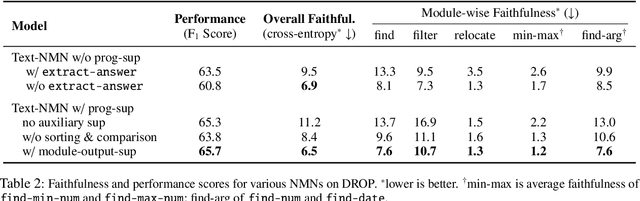
Neural module networks (NMNs) are a popular approach for modeling compositionality: they achieve high accuracy when applied to problems in language and vision, while reflecting the compositional structure of the problem in the network architecture. However, prior work implicitly assumed that the structure of the network modules, describing the abstract reasoning process, provides a faithful explanation of the model's reasoning; that is, that all modules perform their intended behaviour. In this work, we propose and conduct a systematic evaluation of the intermediate outputs of NMNs on NLVR2 and DROP, two datasets which require composing multiple reasoning steps. We find that the intermediate outputs differ from the expected output, illustrating that the network structure does not provide a faithful explanation of model behaviour. To remedy that, we train the model with auxiliary supervision and propose particular choices for module architecture that yield much better faithfulness, at a minimal cost to accuracy.
Evaluating NLP Models via Contrast Sets
Apr 06, 2020
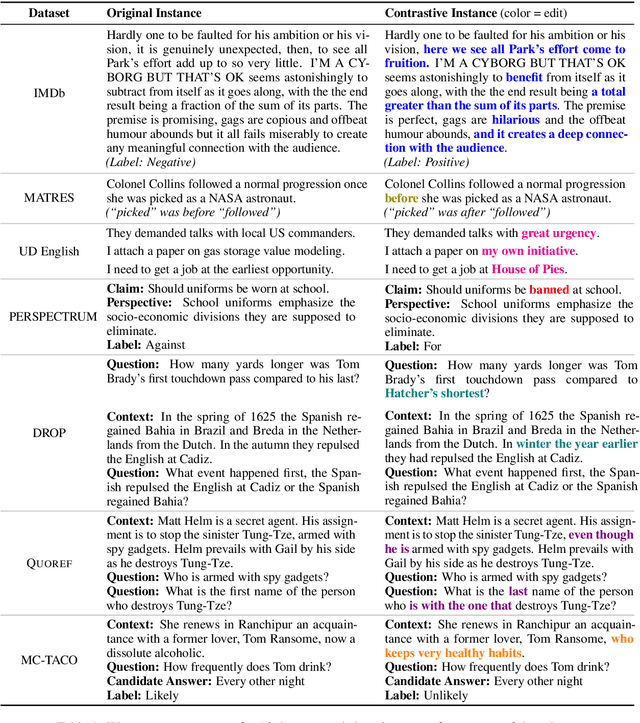
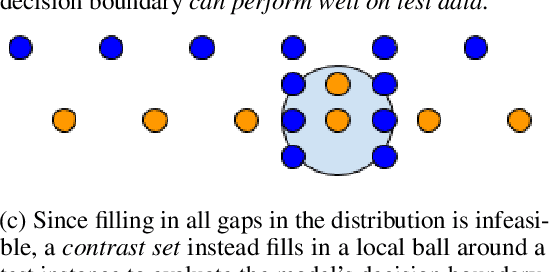
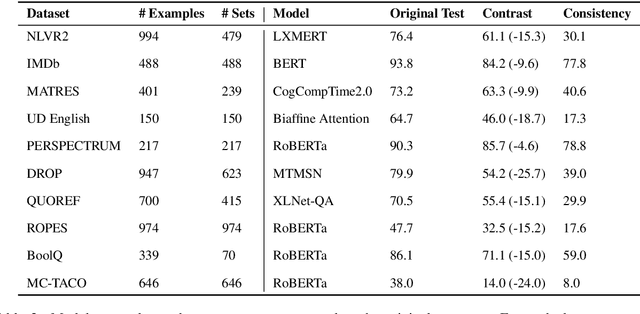
Standard test sets for supervised learning evaluate in-distribution generalization. Unfortunately, when a dataset has systematic gaps (e.g., annotation artifacts), these evaluations are misleading: a model can learn simple decision rules that perform well on the test set but do not capture a dataset's intended capabilities. We propose a new annotation paradigm for NLP that helps to close systematic gaps in the test data. In particular, after a dataset is constructed, we recommend that the dataset authors manually perturb the test instances in small but meaningful ways that (typically) change the gold label, creating contrast sets. Contrast sets provide a local view of a model's decision boundary, which can be used to more accurately evaluate a model's true linguistic capabilities. We demonstrate the efficacy of contrast sets by creating them for 10 diverse NLP datasets (e.g., DROP reading comprehension, UD parsing, IMDb sentiment analysis). Although our contrast sets are not explicitly adversarial, model performance is significantly lower on them than on the original test sets---up to 25\% in some cases. We release our contrast sets as new evaluation benchmarks and encourage future dataset construction efforts to follow similar annotation processes.
Global Reasoning over Database Structures for Text-to-SQL Parsing
Aug 29, 2019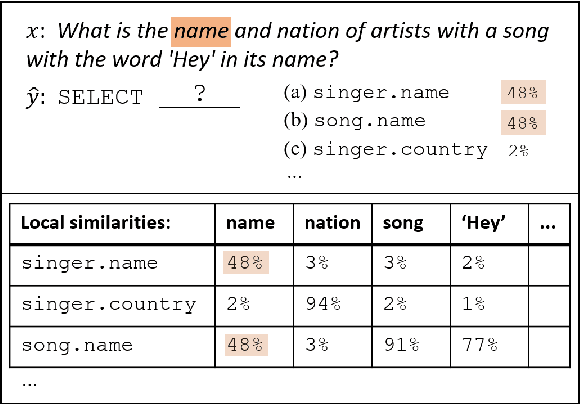

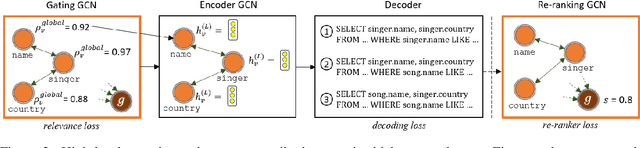
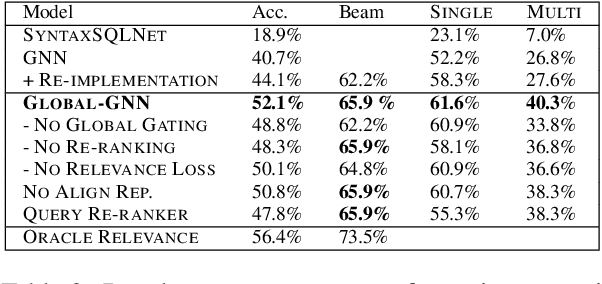
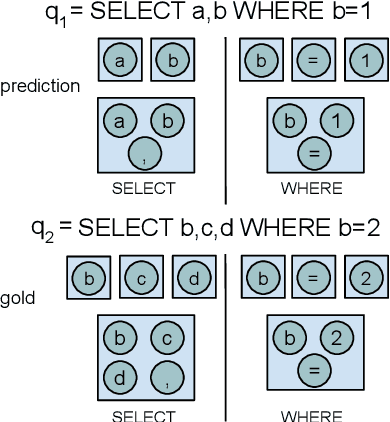
State-of-the-art semantic parsers rely on auto-regressive decoding, emitting one symbol at a time. When tested against complex databases that are unobserved at training time (zero-shot), the parser often struggles to select the correct set of database constants in the new database, due to the local nature of decoding. In this work, we propose a semantic parser that globally reasons about the structure of the output query to make a more contextually-informed selection of database constants. We use message-passing through a graph neural network to softly select a subset of database constants for the output query, conditioned on the question. Moreover, we train a model to rank queries based on the global alignment of database constants to question words. We apply our techniques to the current state-of-the-art model for Spider, a zero-shot semantic parsing dataset with complex databases, increasing accuracy from 39.4% to 47.4%.
Representing Schema Structure with Graph Neural Networks for Text-to-SQL Parsing
Jun 03, 2019
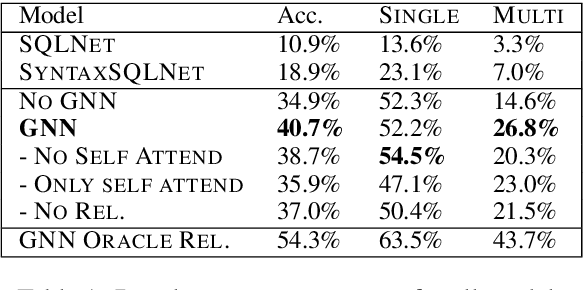
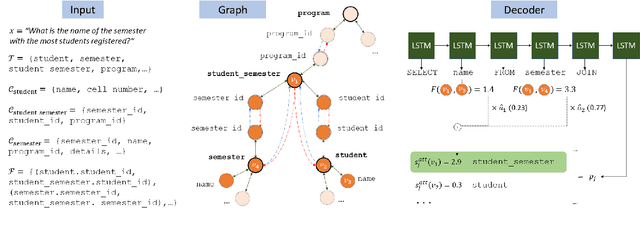
Research on parsing language to SQL has largely ignored the structure of the database (DB) schema, either because the DB was very simple, or because it was observed at both training and test time. In Spider, a recently-released text-to-SQL dataset, new and complex DBs are given at test time, and so the structure of the DB schema can inform the predicted SQL query. In this paper, we present an encoder-decoder semantic parser, where the structure of the DB schema is encoded with a graph neural network, and this representation is later used at both encoding and decoding time. Evaluation shows that encoding the schema structure improves our parser accuracy from 33.8% to 39.4%, dramatically above the current state of the art, which is at 19.7%.
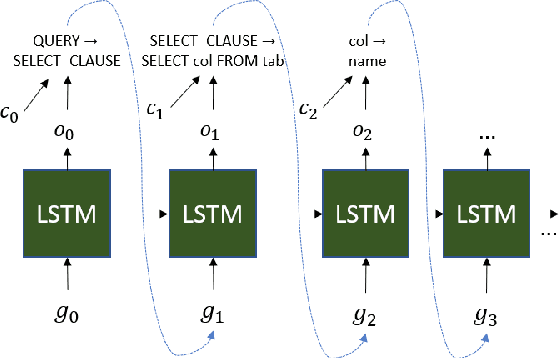
Grammar-based Neural Text-to-SQL Generation
May 30, 2019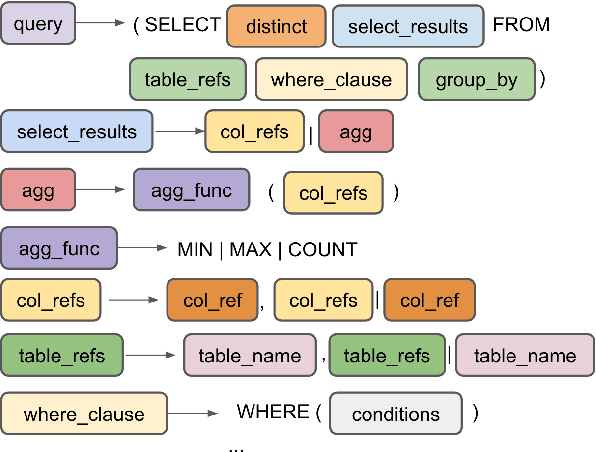

The sequence-to-sequence paradigm employed by neural text-to-SQL models typically performs token-level decoding and does not consider generating SQL hierarchically from a grammar. Grammar-based decoding has shown significant improvements for other semantic parsing tasks, but SQL and other general programming languages have complexities not present in logical formalisms that make writing hierarchical grammars difficult. We introduce techniques to handle these complexities, showing how to construct a schema-dependent grammar with minimal over-generation. We analyze these techniques on ATIS and Spider, two challenging text-to-SQL datasets, demonstrating that they yield 14--18\% relative reductions in error.