 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimGym: A Framework for A/B Test Simulation in E-Commerce with Traffic-Grounded VLM Agents
May 19, 2026A/B testing remains the gold standard for evaluating modifications to e-commerce storefronts, yet it diverts traffic, requires weeks to reach statistical significance, and risks degrading user experience. We present SimGym, a framework for simulating A/B tests on e-commerce storefronts using vision-language model (VLM) agents operating in a live browser. The framework comprises three key components: (a) a traffic-grounded persona generation pipeline that derives per-shop buyer archetypes and intents from production clickstream data; (b) a live-browser agent architecture that combines multimodal perception over visual and browser-structured observations with episodic memory and guardrails to conduct coherent shopping sessions across control and treatment storefronts; and (c) an evaluation protocol that compares simulated outcome shifts with observed shifts in real buyer behavior. We validate SimGym on A/B tests of visually driven UI theme changes from a major e-commerce platform across diverse storefronts and product categories. Empirical results show that SimGym agents achieve strong agreement with observed outcome shifts, attaining 77% directional alignment with add-to-cart shifts observed across interface variants in real-buyer traffic. It reduces experimental cycles from weeks to under an hour, enabling rapid experimentation without exposing real buyers to candidate variants.
SimGym: Traffic-Grounded Browser Agents for Offline A/B Testing in E-Commerce
Feb 01, 2026A/B testing remains the gold standard for evaluating e-commerce UI changes, yet it diverts traffic, takes weeks to reach significance, and risks harming user experience. We introduce SimGym, a scalable system for rapid offline A/B testing using traffic-grounded synthetic buyers powered by Large Language Model agents operating in a live browser. SimGym extracts per-shop buyer profiles and intents from production interaction data, identifies distinct behavioral archetypes, and simulates cohort-weighted sessions across control and treatment storefronts. We validate SimGym against real human outcomes from real UI changes on a major e-commerce platform under confounder control. Even without alignment post training, SimGym agents achieve state of the art alignment with observed outcome shifts and reduces experiment cycles from weeks to under an hour , enabling rapid experimentation without exposure to real buyers.
Text-to-SQL in the Wild: A Naturally-Occurring Dataset Based on Stack Exchange Data
Jun 09, 2021
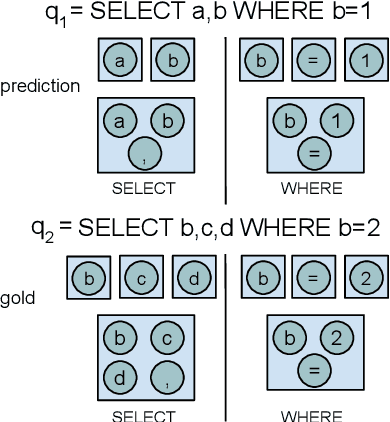
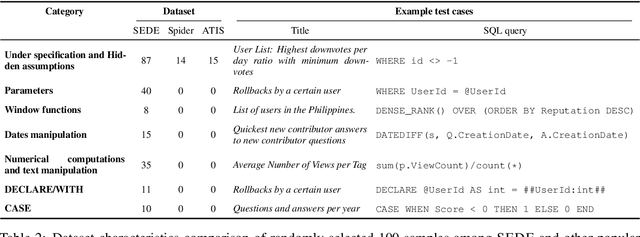
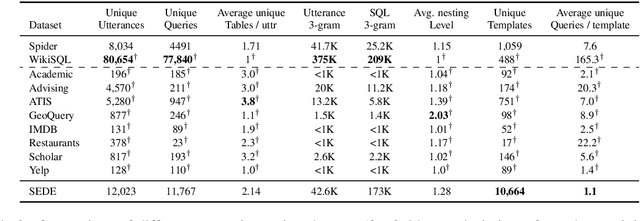
Most available semantic parsing datasets, comprising of pairs of natural utterances and logical forms, were collected solely for the purpose of training and evaluation of natural language understanding systems. As a result, they do not contain any of the richness and variety of natural-occurring utterances, where humans ask about data they need or are curious about. In this work, we release SEDE, a dataset with 12,023 pairs of utterances and SQL queries collected from real usage on the Stack Exchange website. We show that these pairs contain a variety of real-world challenges which were rarely reflected so far in any other semantic parsing dataset, propose an evaluation metric based on comparison of partial query clauses that is more suitable for real-world queries, and conduct experiments with strong baselines, showing a large gap between the performance on SEDE compared to other common datasets.