 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the relative composition of EEG signals using pairwise relative shift pretraining
Nov 14, 2025Self-supervised learning (SSL) offers a promising approach for learning electroencephalography (EEG) representations from unlabeled data, reducing the need for expensive annotations for clinical applications like sleep staging and seizure detection. While current EEG SSL methods predominantly use masked reconstruction strategies like masked autoencoders (MAE) that capture local temporal patterns, position prediction pretraining remains underexplored despite its potential to learn long-range dependencies in neural signals. We introduce PAirwise Relative Shift or PARS pretraining, a novel pretext task that predicts relative temporal shifts between randomly sampled EEG window pairs. Unlike reconstruction-based methods that focus on local pattern recovery, PARS encourages encoders to capture relative temporal composition and long-range dependencies inherent in neural signals. Through comprehensive evaluation on various EEG decoding tasks, we demonstrate that PARS-pretrained transformers consistently outperform existing pretraining strategies in label-efficient and transfer learning settings, establishing a new paradigm for self-supervised EEG representation learning.
CPEP: Contrastive Pose-EMG Pre-training Enhances Gesture Generalization on EMG Signals
Sep 04, 2025



Hand gesture classification using high-quality structured data such as videos, images, and hand skeletons is a well-explored problem in computer vision. Leveraging low-power, cost-effective biosignals, e.g. surface electromyography (sEMG), allows for continuous gesture prediction on wearables. In this paper, we demonstrate that learning representations from weak-modality data that are aligned with those from structured, high-quality data can improve representation quality and enables zero-shot classification. Specifically, we propose a Contrastive Pose-EMG Pre-training (CPEP) framework to align EMG and pose representations, where we learn an EMG encoder that produces high-quality and pose-informative representations. We assess the gesture classification performance of our model through linear probing and zero-shot setups. Our model outperforms emg2pose benchmark models by up to 21% on in-distribution gesture classification and 72% on unseen (out-of-distribution) gesture classification.
Promoting cross-modal representations to improve multimodal foundation models for physiological signals
Oct 21, 2024



Many healthcare applications are inherently multimodal, involving several physiological signals. As sensors for these signals become more common, improving machine learning methods for multimodal healthcare data is crucial. Pretraining foundation models is a promising avenue for success. However, methods for developing foundation models in healthcare are still in early exploration and it is unclear which pretraining strategies are most effective given the diversity of physiological signals. This is partly due to challenges in multimodal health data: obtaining data across many patients is difficult and costly, there is a lot of inter-subject variability, and modalities are often heterogeneously informative across downstream tasks. Here, we explore these challenges in the PhysioNet 2018 dataset. We use a masked autoencoding objective to pretrain a multimodal model. We show that the model learns representations that can be linearly probed for a diverse set of downstream tasks. We hypothesize that cross-modal reconstruction objectives are important for successful multimodal training, as they encourage the model to integrate information across modalities. We demonstrate that modality dropout in the input space improves performance across downstream tasks. We also find that late-fusion models pretrained with contrastive learning objectives are less effective across multiple tasks. Finally, we analyze the model's representations, showing that attention weights become more cross-modal and temporally aligned with our pretraining strategy. The learned embeddings also become more distributed in terms of the modalities encoded by each unit. Overall, our work demonstrates the utility of multimodal foundation models with health data, even across diverse physiological data sources. We further argue that explicit methods for inducing cross-modality may enhance multimodal pretraining strategies.
Generalizable autoregressive modeling of time series through functional narratives
Oct 10, 2024



Time series data are inherently functions of time, yet current transformers often learn time series by modeling them as mere concatenations of time periods, overlooking their functional properties. In this work, we propose a novel objective for transformers that learn time series by re-interpreting them as temporal functions. We build an alternative sequence of time series by constructing degradation operators of different intensity in the functional space, creating augmented variants of the original sample that are abstracted or simplified to different degrees. Based on the new set of generated sequence, we train an autoregressive transformer that progressively recovers the original sample from the most simplified variant. Analogous to the next word prediction task in languages that learns narratives by connecting different words, our autoregressive transformer aims to learn the Narratives of Time Series (NoTS) by connecting different functions in time. Theoretically, we justify the construction of the alternative sequence through its advantages in approximating functions. When learning time series data with transformers, constructing sequences of temporal functions allows for a broader class of approximable functions (e.g., differentiation) compared to sequences of time periods, leading to a 26\% performance improvement in synthetic feature regression experiments. Experimentally, we validate NoTS in 3 different tasks across 22 real-world datasets, where we show that NoTS significantly outperforms other pre-training methods by up to 6\%. Additionally, combining NoTS on top of existing transformer architectures can consistently boost the performance. Our results demonstrate the potential of NoTS as a general-purpose dynamic learner, offering a viable alternative for developing foundation models for time series analysis.
Efficient Source-Free Time-Series Adaptation via Parameter Subspace Disentanglement
Oct 03, 2024In this paper, we propose a framework for efficient Source-Free Domain Adaptation (SFDA) in the context of time-series, focusing on enhancing both parameter efficiency and data-sample utilization. Our approach introduces an improved paradigm for source-model preparation and target-side adaptation, aiming to enhance training efficiency during target adaptation. Specifically, we reparameterize the source model's weights in a Tucker-style decomposed manner, factorizing the model into a compact form during the source model preparation phase. During target-side adaptation, only a subset of these decomposed factors is fine-tuned, leading to significant improvements in training efficiency. We demonstrate using PAC Bayesian analysis that this selective fine-tuning strategy implicitly regularizes the adaptation process by constraining the model's learning capacity. Furthermore, this re-parameterization reduces the overall model size and enhances inference efficiency, making the approach particularly well suited for resource-constrained devices. Additionally, we demonstrate that our framework is compatible with various SFDA methods and achieves significant computational efficiency, reducing the number of fine-tuned parameters and inference overhead in terms of MACs by over 90% while maintaining model performance.
Model-driven Heart Rate Estimation and Heart Murmur Detection based on Phonocardiogram
Jul 25, 2024



Acoustic signals are crucial for health monitoring, particularly heart sounds which provide essential data like heart rate and detect cardiac anomalies such as murmurs. This study utilizes a publicly available phonocardiogram (PCG) dataset to estimate heart rate using model-driven methods and extends the best-performing model to a multi-task learning (MTL) framework for simultaneous heart rate estimation and murmur detection. Heart rate estimates are derived using a sliding window technique on heart sound snippets, analyzed with a combination of acoustic features (Mel spectrogram, cepstral coefficients, power spectral density, root mean square energy). Our findings indicate that a 2D convolutional neural network (\textbf{\texttt{2dCNN}}) is most effective for heart rate estimation, achieving a mean absolute error (MAE) of 1.312 bpm. We systematically investigate the impact of different feature combinations and find that utilizing all four features yields the best results. The MTL model (\textbf{\texttt{2dCNN-MTL}}) achieves accuracy over 95% in murmur detection, surpassing existing models, while maintaining an MAE of 1.636 bpm in heart rate estimation, satisfying the requirements stated by Association for the Advancement of Medical Instrumentation (AAMI).
Budget-Aware Activity Detection with A Recurrent Policy Network
May 08, 2018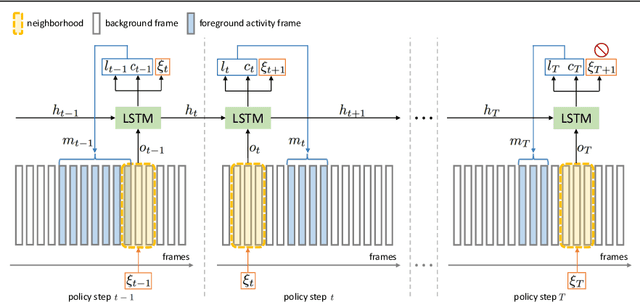
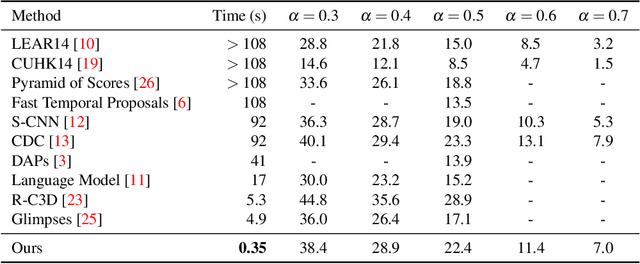
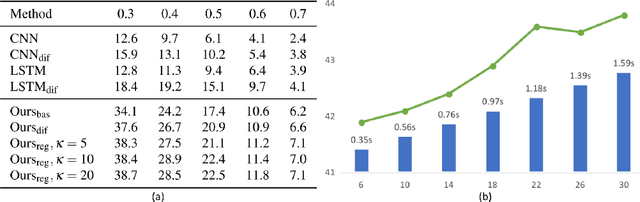
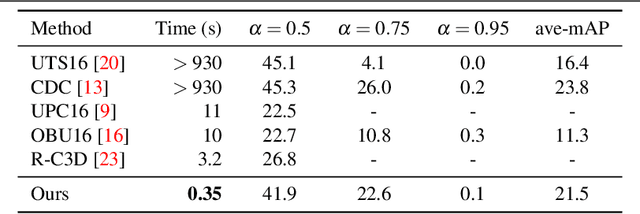
In this paper, we address the challenging problem of efficient temporal activity detection in untrimmed long videos. While most recent work has focused and advanced the detection accuracy, the inference time can take seconds to minutes in processing each single video, which is too slow to be useful in real-world settings. This motivates the proposed budget-aware framework, which learns to perform activity detection by intelligently selecting a small subset of frames according to a specified time budget. We formulate this problem as a Markov decision process, and adopt a recurrent network to model the frame selection policy. We derive a recurrent policy gradient based approach to approximate the gradient of the non-decomposable and non-differentiable objective defined in our problem. In the extensive experiments, we achieve competitive detection accuracy, and more importantly, our approach is able to substantially reduce computation time and detect multiple activities with only 0.35s for each untrimmed long video.
Approximate Policy Iteration for Budgeted Semantic Video Segmentation
Jul 26, 2016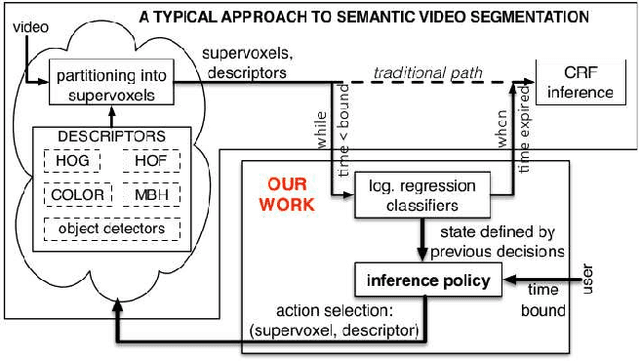
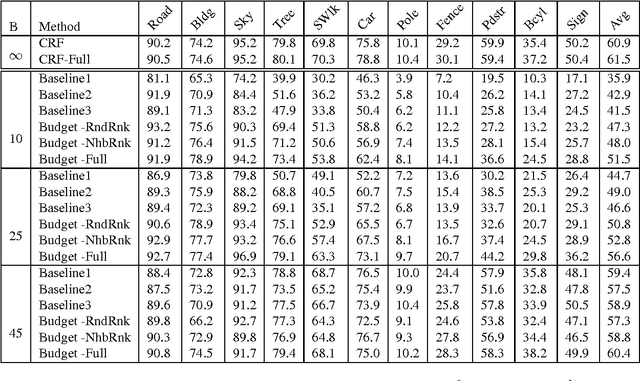
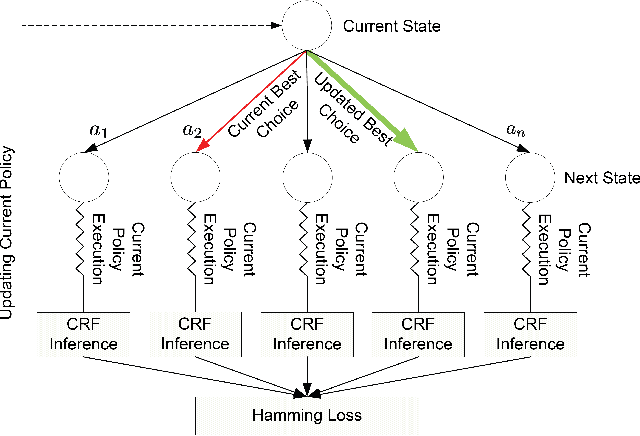
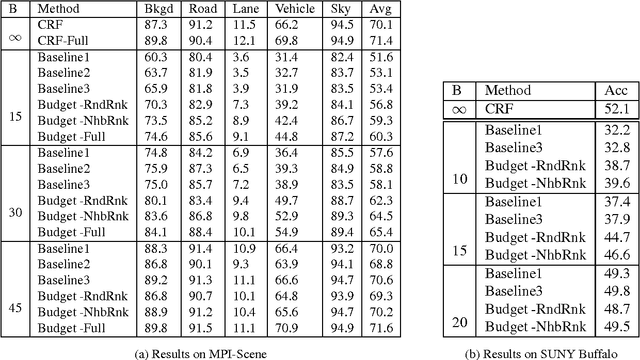
This paper formulates and presents a solution to the new problem of budgeted semantic video segmentation. Given a video, the goal is to accurately assign a semantic class label to every pixel in the video within a specified time budget. Typical approaches to such labeling problems, such as Conditional Random Fields (CRFs), focus on maximizing accuracy but do not provide a principled method for satisfying a time budget. For video data, the time required by CRF and related methods is often dominated by the time to compute low-level descriptors of supervoxels across the video. Our key contribution is the new budgeted inference framework for CRF models that intelligently selects the most useful subsets of descriptors to run on subsets of supervoxels within the time budget. The objective is to maintain an accuracy as close as possible to the CRF model with no time bound, while remaining within the time budget. Our second contribution is the algorithm for learning a policy for the sparse selection of supervoxels and their descriptors for budgeted CRF inference. This learning algorithm is derived by casting our problem in the framework of Markov Decision Processes, and then instantiating a state-of-the-art policy learning algorithm known as Classification-Based Approximate Policy Iteration. Our experiments on multiple video datasets show that our learning approach and framework is able to significantly reduce computation time, and maintain competitive accuracy under varying budgets.