 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the relative composition of EEG signals using pairwise relative shift pretraining
Nov 14, 2025Self-supervised learning (SSL) offers a promising approach for learning electroencephalography (EEG) representations from unlabeled data, reducing the need for expensive annotations for clinical applications like sleep staging and seizure detection. While current EEG SSL methods predominantly use masked reconstruction strategies like masked autoencoders (MAE) that capture local temporal patterns, position prediction pretraining remains underexplored despite its potential to learn long-range dependencies in neural signals. We introduce PAirwise Relative Shift or PARS pretraining, a novel pretext task that predicts relative temporal shifts between randomly sampled EEG window pairs. Unlike reconstruction-based methods that focus on local pattern recovery, PARS encourages encoders to capture relative temporal composition and long-range dependencies inherent in neural signals. Through comprehensive evaluation on various EEG decoding tasks, we demonstrate that PARS-pretrained transformers consistently outperform existing pretraining strategies in label-efficient and transfer learning settings, establishing a new paradigm for self-supervised EEG representation learning.
Continual Hyperbolic Learning of Instances and Classes
Jun 12, 2025



Continual learning has traditionally focused on classifying either instances or classes, but real-world applications, such as robotics and self-driving cars, require models to handle both simultaneously. To mirror real-life scenarios, we introduce the task of continual learning of instances and classes, at the same time. This task challenges models to adapt to multiple levels of granularity over time, which requires balancing fine-grained instance recognition with coarse-grained class generalization. In this paper, we identify that classes and instances naturally form a hierarchical structure. To model these hierarchical relationships, we propose HyperCLIC, a continual learning algorithm that leverages hyperbolic space, which is uniquely suited for hierarchical data due to its ability to represent tree-like structures with low distortion and compact embeddings. Our framework incorporates hyperbolic classification and distillation objectives, enabling the continual embedding of hierarchical relations. To evaluate performance across multiple granularities, we introduce continual hierarchical metrics. We validate our approach on EgoObjects, the only dataset that captures the complexity of hierarchical object recognition in dynamic real-world environments. Empirical results show that HyperCLIC operates effectively at multiple granularities with improved hierarchical generalization.
Self-Contained Entity Discovery from Captioned Videos
Aug 13, 2022
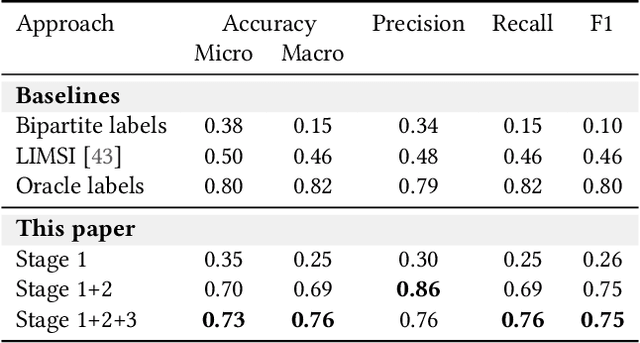
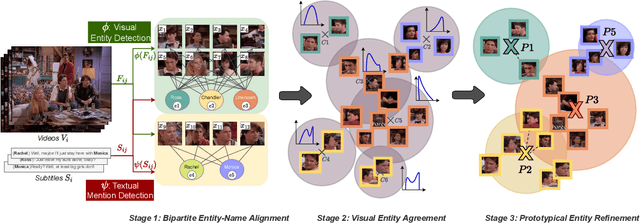
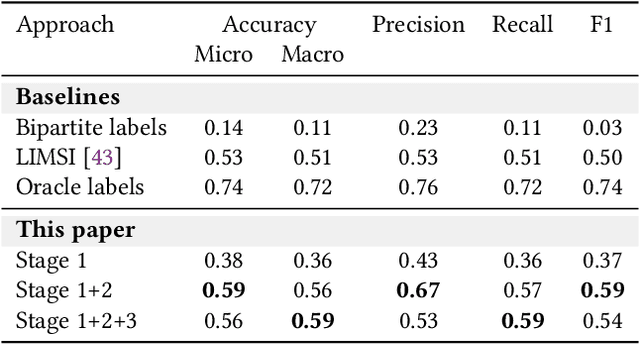
This paper introduces the task of visual named entity discovery in videos without the need for task-specific supervision or task-specific external knowledge sources. Assigning specific names to entities (e.g. faces, scenes, or objects) in video frames is a long-standing challenge. Commonly, this problem is addressed as a supervised learning objective by manually annotating faces with entity labels. To bypass the annotation burden of this setup, several works have investigated the problem by utilizing external knowledge sources such as movie databases. While effective, such approaches do not work when task-specific knowledge sources are not provided and can only be applied to movies and TV series. In this work, we take the problem a step further and propose to discover entities in videos from videos and corresponding captions or subtitles. We introduce a three-stage method where we (i) create bipartite entity-name graphs from frame-caption pairs, (ii) find visual entity agreements, and (iii) refine the entity assignment through entity-level prototype construction. To tackle this new problem, we outline two new benchmarks SC-Friends and SC-BBT based on the Friends and Big Bang Theory TV series. Experiments on the benchmarks demonstrate the ability of our approach to discover which named entity belongs to which face or scene, with an accuracy close to a supervised oracle, just from the multimodal information present in videos. Additionally, our qualitative examples show the potential challenges of self-contained discovery of any visual entity for future work. The code and the data are available on GitHub.