 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEPOpt: Learning Robust Neural Network Policies Using Model Ensembles
Mar 03, 2017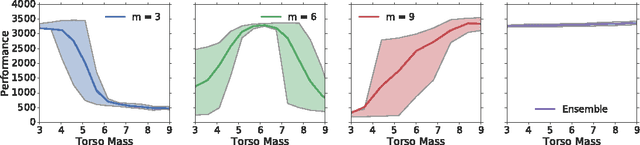
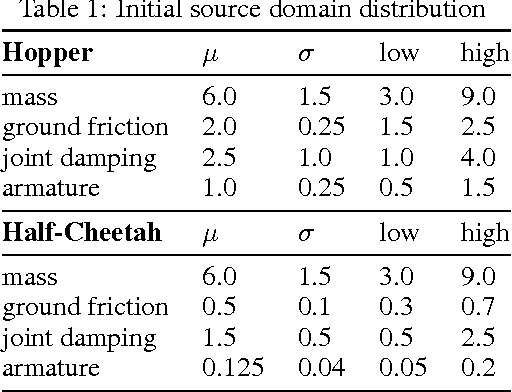
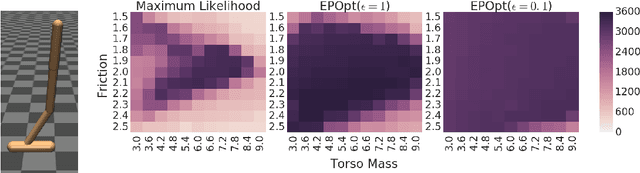
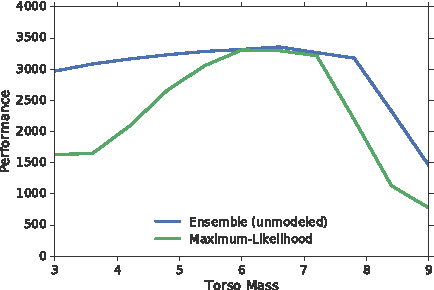
Sample complexity and safety are major challenges when learning policies with reinforcement learning for real-world tasks, especially when the policies are represented using rich function approximators like deep neural networks. Model-based methods where the real-world target domain is approximated using a simulated source domain provide an avenue to tackle the above challenges by augmenting real data with simulated data. However, discrepancies between the simulated source domain and the target domain pose a challenge for simulated training. We introduce the EPOpt algorithm, which uses an ensemble of simulated source domains and a form of adversarial training to learn policies that are robust and generalize to a broad range of possible target domains, including unmodeled effects. Further, the probability distribution over source domains in the ensemble can be adapted using data from target domain and approximate Bayesian methods, to progressively make it a better approximation. Thus, learning on a model ensemble, along with source domain adaptation, provides the benefit of both robustness and learning/adaptation.
SLAM-Safe Planner: Preventing Monocular SLAM Failure using Reinforcement Learning
Mar 03, 2017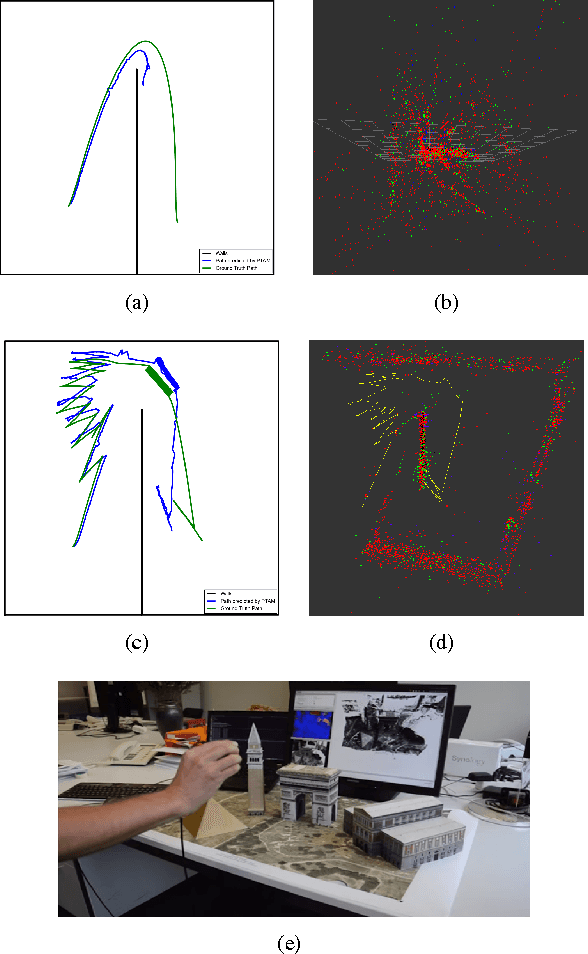
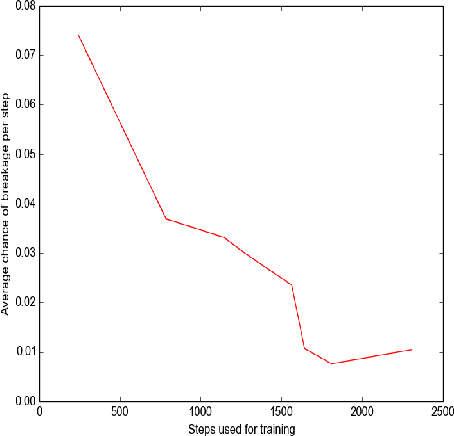
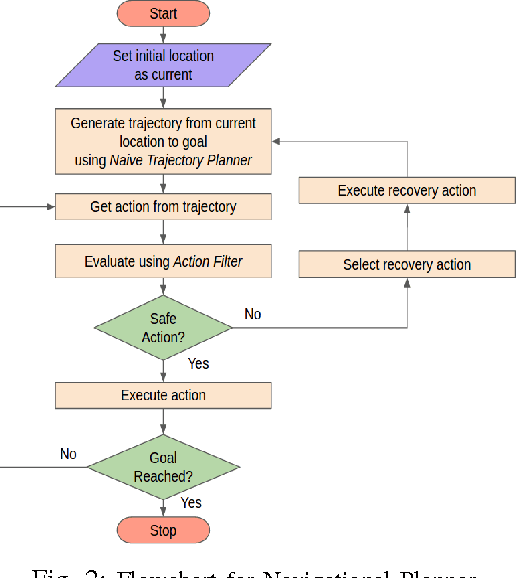
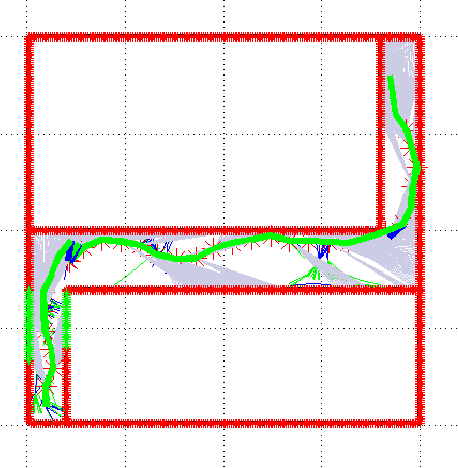
Effective SLAM using a single monocular camera is highly preferred due to its simplicity. However, when compared to trajectory planning methods using depth-based SLAM, Monocular SLAM in loop does need additional considerations. One main reason being that for the optimization, in the form of Bundle Adjustment (BA), to be robust, the SLAM system needs to scan the area for a reasonable duration. Most monocular SLAM systems do not tolerate large camera rotations between successive views and tend to breakdown. Other reasons for Monocular SLAM failure include ambiguities in decomposition of the Essential Matrix, feature-sparse scenes and more layers of non linear optimization apart from BA. This paper presents a novel formulation based on Reinforcement Learning (RL) that generates fail safe trajectories wherein the SLAM generated outputs (scene structure and camera motion) do not deviate largely from their true values. Quintessentially, the RL framework successfully learns the otherwise complex relation between motor actions and perceptual inputs that result in trajectories that do not cause failure of SLAM, which are almost intractable to capture in an obvious mathematical formulation. We show systematically in simulations how the quality of the SLAM map and trajectory dramatically improves when trajectories are computed by using RL.
Learning to Repeat: Fine Grained Action Repetition for Deep Reinforcement Learning
Feb 20, 2017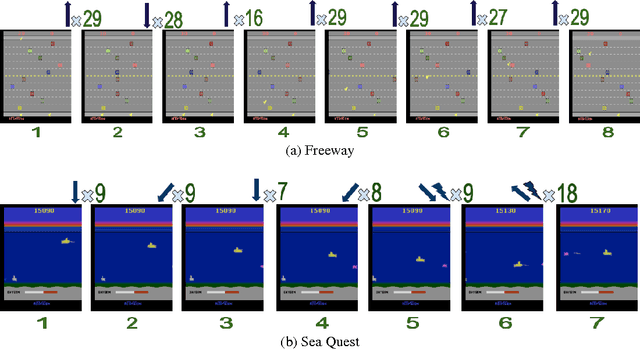

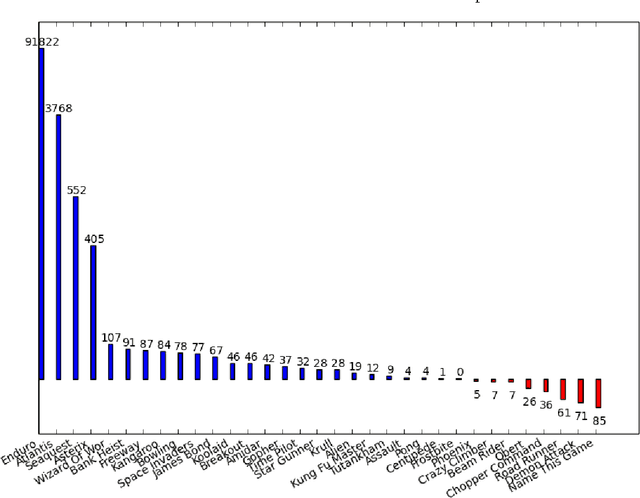
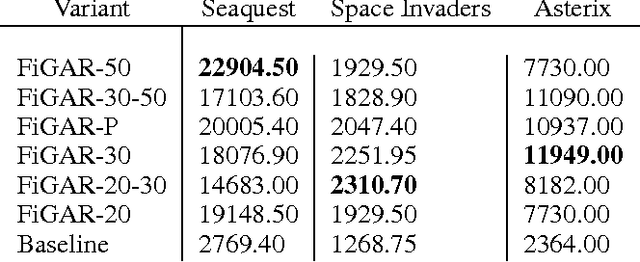
Reinforcement Learning algorithms can learn complex behavioral patterns for sequential decision making tasks wherein an agent interacts with an environment and acquires feedback in the form of rewards sampled from it. Traditionally, such algorithms make decisions, i.e., select actions to execute, at every single time step of the agent-environment interactions. In this paper, we propose a novel framework, Fine Grained Action Repetition (FiGAR), which enables the agent to decide the action as well as the time scale of repeating it. FiGAR can be used for improving any Deep Reinforcement Learning algorithm which maintains an explicit policy estimate by enabling temporal abstractions in the action space. We empirically demonstrate the efficacy of our framework by showing performance improvements on top of three policy search algorithms in different domains: Asynchronous Advantage Actor Critic in the Atari 2600 domain, Trust Region Policy Optimization in Mujoco domain and Deep Deterministic Policy Gradients in the TORCS car racing domain.
Exploration for Multi-task Reinforcement Learning with Deep Generative Models
Nov 29, 2016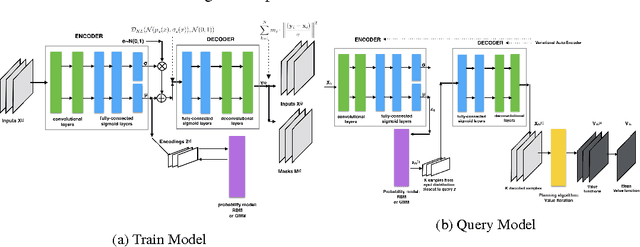
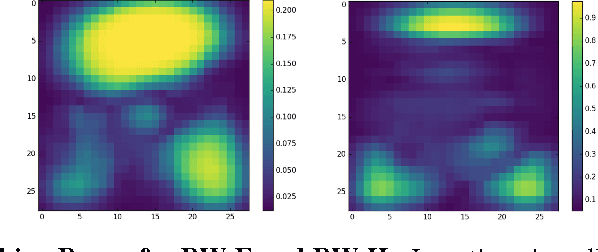
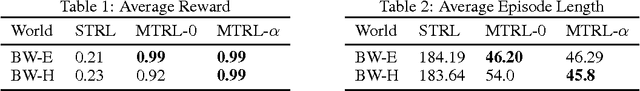

Exploration in multi-task reinforcement learning is critical in training agents to deduce the underlying MDP. Many of the existing exploration frameworks such as $E^3$, $R_{max}$, Thompson sampling assume a single stationary MDP and are not suitable for system identification in the multi-task setting. We present a novel method to facilitate exploration in multi-task reinforcement learning using deep generative models. We supplement our method with a low dimensional energy model to learn the underlying MDP distribution and provide a resilient and adaptive exploration signal to the agent. We evaluate our method on a new set of environments and provide intuitive interpretation of our results.
Option Discovery in Hierarchical Reinforcement Learning using Spatio-Temporal Clustering
Sep 20, 2016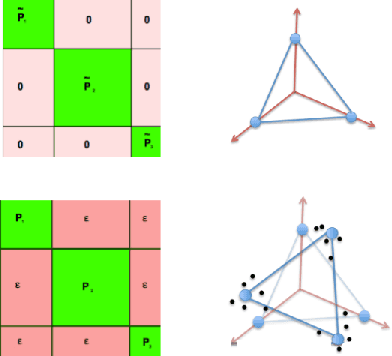

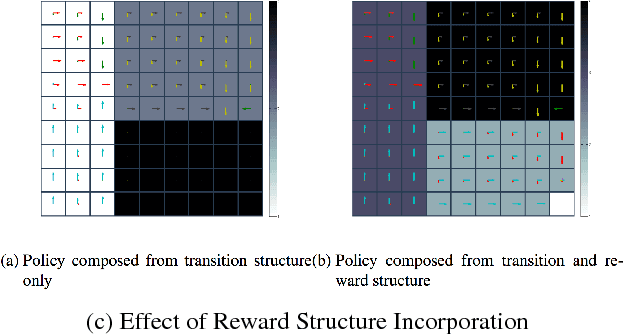
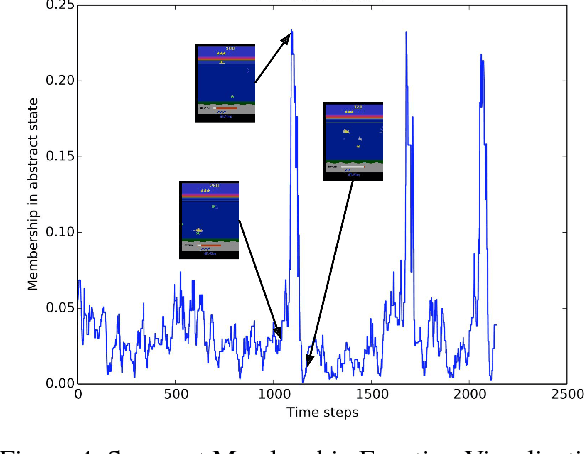
This paper introduces an automated skill acquisition framework in reinforcement learning which involves identifying a hierarchical description of the given task in terms of abstract states and extended actions between abstract states. Identifying such structures present in the task provides ways to simplify and speed up reinforcement learning algorithms. These structures also help to generalize such algorithms over multiple tasks without relearning policies from scratch. We use ideas from dynamical systems to find metastable regions in the state space and associate them with abstract states. The spectral clustering algorithm PCCA+ is used to identify suitable abstractions aligned to the underlying structure. Skills are defined in terms of the sequence of actions that lead to transitions between such abstract states. The connectivity information from PCCA+ is used to generate these skills or options. These skills are independent of the learning task and can be efficiently reused across a variety of tasks defined over the same model. This approach works well even without the exact model of the environment by using sample trajectories to construct an approximate estimate. We also present our approach to scaling the skill acquisition framework to complex tasks with large state spaces for which we perform state aggregation using the representation learned from an action conditional video prediction network and use the skill acquisition framework on the aggregated state space.
Bridge Correlational Neural Networks for Multilingual Multimodal Representation Learning
Jul 01, 2016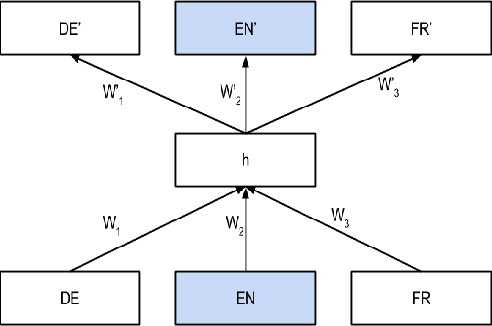
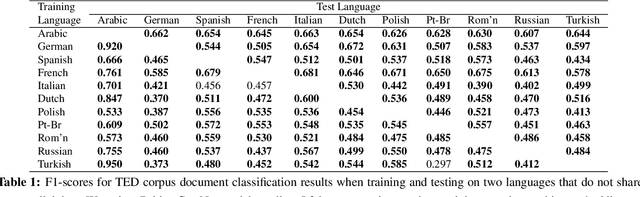
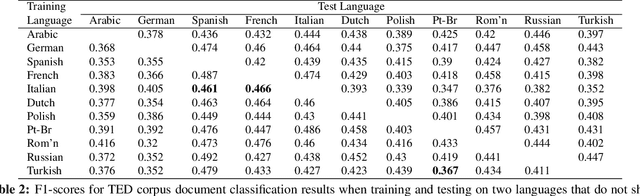
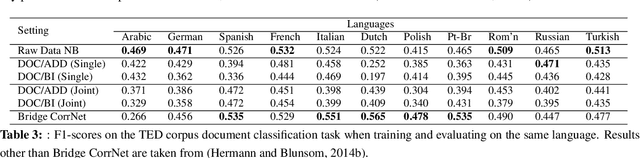
Recently there has been a lot of interest in learning common representations for multiple views of data. Typically, such common representations are learned using a parallel corpus between the two views (say, 1M images and their English captions). In this work, we address a real-world scenario where no direct parallel data is available between two views of interest (say, $V_1$ and $V_2$) but parallel data is available between each of these views and a pivot view ($V_3$). We propose a model for learning a common representation for $V_1$, $V_2$ and $V_3$ using only the parallel data available between $V_1V_3$ and $V_2V_3$. The proposed model is generic and even works when there are $n$ views of interest and only one pivot view which acts as a bridge between them. There are two specific downstream applications that we focus on (i) transfer learning between languages $L_1$,$L_2$,...,$L_n$ using a pivot language $L$ and (ii) cross modal access between images and a language $L_1$ using a pivot language $L_2$. Our model achieves state-of-the-art performance in multilingual document classification on the publicly available multilingual TED corpus and promising results in multilingual multimodal retrieval on a new dataset created and released as a part of this work.
Dynamic Frame skip Deep Q Network
Jun 11, 2016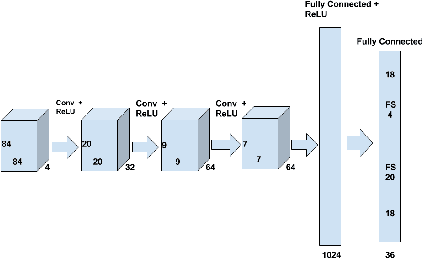
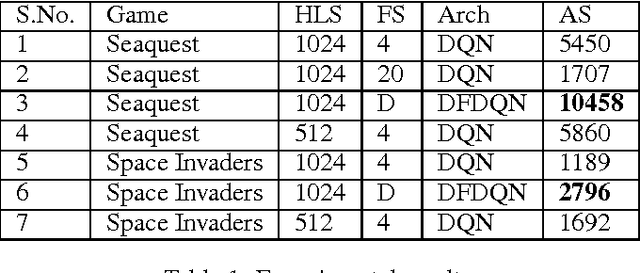
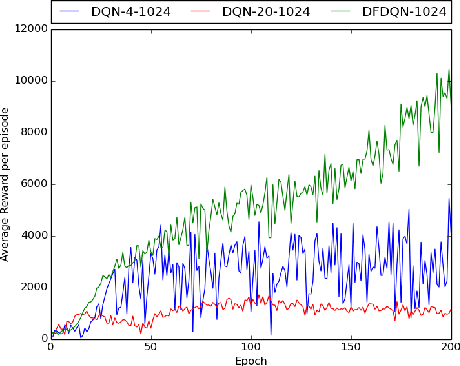
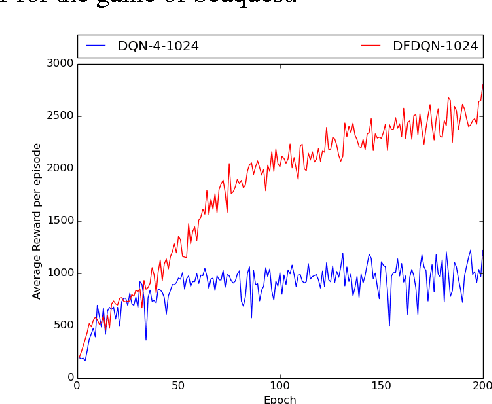
Deep Reinforcement Learning methods have achieved state of the art performance in learning control policies for the games in the Atari 2600 domain. One of the important parameters in the Arcade Learning Environment (ALE) is the frame skip rate. It decides the granularity at which agents can control game play. A frame skip value of $k$ allows the agent to repeat a selected action $k$ number of times. The current state of the art architectures like Deep Q-Network (DQN) and Dueling Network Architectures (DuDQN) consist of a framework with a static frame skip rate, where the action output from the network is repeated for a fixed number of frames regardless of the current state. In this paper, we propose a new architecture, Dynamic Frame skip Deep Q-Network (DFDQN) which makes the frame skip rate a dynamic learnable parameter. This allows us to choose the number of times an action is to be repeated based on the current state. We show empirically that such a setting improves the performance on relatively harder games like Seaquest.
Linear Bandit algorithms using the Bootstrap
May 04, 2016
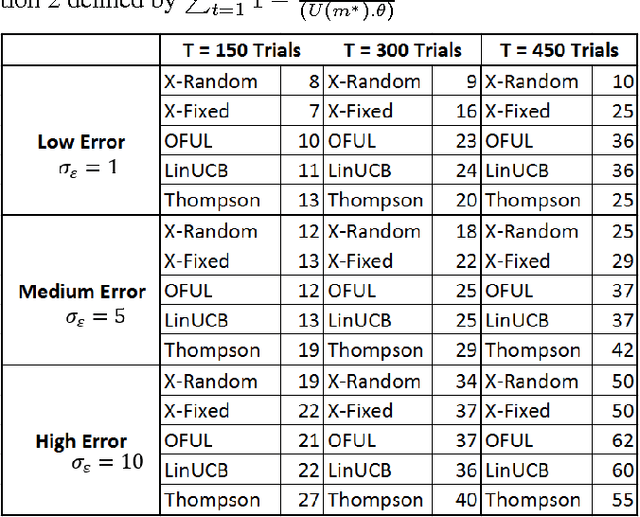
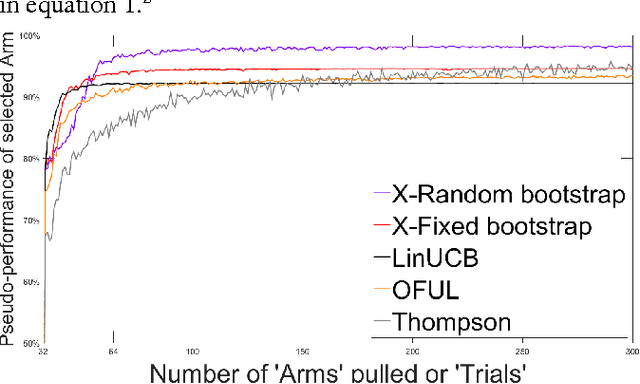
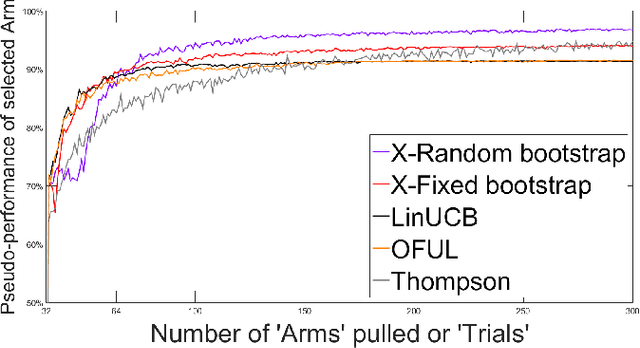
This study presents two new algorithms for solving linear stochastic bandit problems. The proposed methods use an approach from non-parametric statistics called bootstrapping to create confidence bounds. This is achieved without making any assumptions about the distribution of noise in the underlying system. We present the X-Random and X-Fixed bootstrap bandits which correspond to the two well-known approaches for conducting bootstraps on models, in the literature. The proposed methods are compared to other popular solutions for linear stochastic bandit problems, namely, OFUL, LinUCB and Thompson Sampling. The comparisons are carried out using a simulation study on a hierarchical probability meta-model, built from published data of experiments, which are run on real systems. The model representing the response surfaces is conceptualized as a Bayesian Network which is presented with varying degrees of noise for the simulations. One of the proposed methods, X-Random bootstrap, performs better than the baselines in-terms of cumulative regret across various degrees of noise and different number of trials. In certain settings the cumulative regret of this method is less than half of the best baseline. The X-Fixed bootstrap performs comparably in most situations and particularly well when the number of trials is low. The study concludes that these algorithms could be a preferred alternative for solving linear bandit problems, especially when the distribution of the noise in the system is unknown.
Correlational Neural Networks
Oct 12, 2015Common Representation Learning (CRL), wherein different descriptions (or views) of the data are embedded in a common subspace, is receiving a lot of attention recently. Two popular paradigms here are Canonical Correlation Analysis (CCA) based approaches and Autoencoder (AE) based approaches. CCA based approaches learn a joint representation by maximizing correlation of the views when projected to the common subspace. AE based methods learn a common representation by minimizing the error of reconstructing the two views. Each of these approaches has its own advantages and disadvantages. For example, while CCA based approaches outperform AE based approaches for the task of transfer learning, they are not as scalable as the latter. In this work we propose an AE based approach called Correlational Neural Network (CorrNet), that explicitly maximizes correlation among the views when projected to the common subspace. Through a series of experiments, we demonstrate that the proposed CorrNet is better than the above mentioned approaches with respect to its ability to learn correlated common representations. Further, we employ CorrNet for several cross language tasks and show that the representations learned using CorrNet perform better than the ones learned using other state of the art approaches.
TSEB: More Efficient Thompson Sampling for Policy Learning
Oct 10, 2015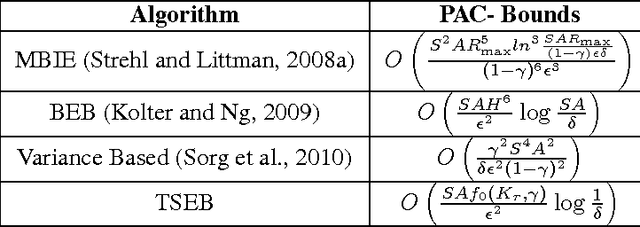
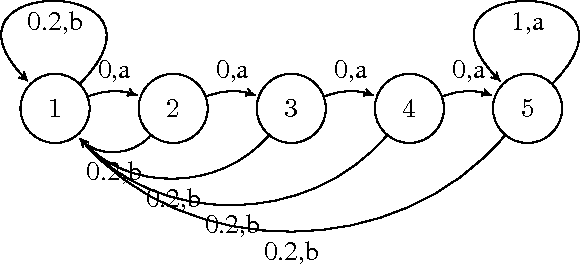
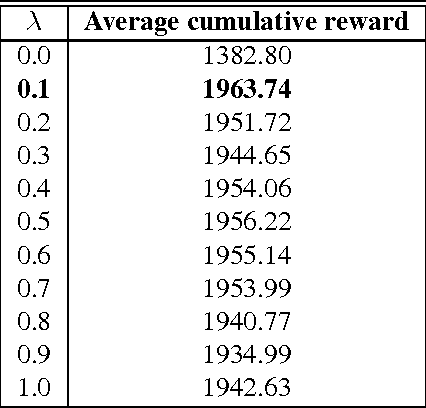
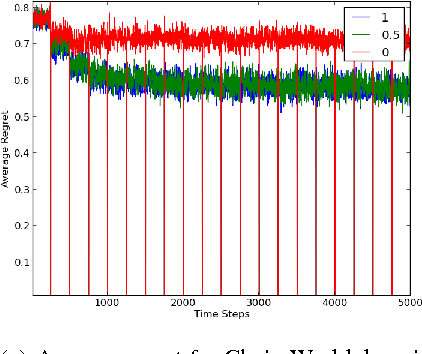
In model-based solution approaches to the problem of learning in an unknown environment, exploring to learn the model parameters takes a toll on the regret. The optimal performance with respect to regret or PAC bounds is achievable, if the algorithm exploits with respect to reward or explores with respect to the model parameters, respectively. In this paper, we propose TSEB, a Thompson Sampling based algorithm with adaptive exploration bonus that aims to solve the problem with tighter PAC guarantees, while being cautious on the regret as well. The proposed approach maintains distributions over the model parameters which are successively refined with more experience. At any given time, the agent solves a model sampled from this distribution, and the sampled reward distribution is skewed by an exploration bonus in order to generate more informative exploration. The policy by solving is then used for generating more experience that helps in updating the posterior over the model parameters. We provide a detailed analysis of the PAC guarantees, and convergence of the proposed approach. We show that our adaptive exploration bonus encourages the additional exploration required for better PAC bounds on the algorithm. We provide empirical analysis on two different simulated domains.