 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining in Style: Training a GAN to explain a classifier in StyleSpace
Apr 27, 2021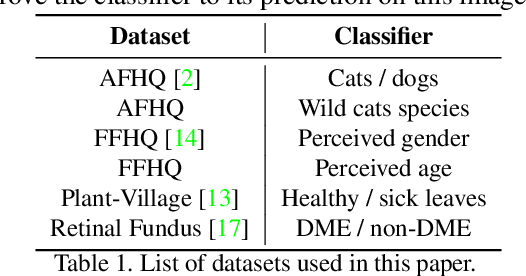
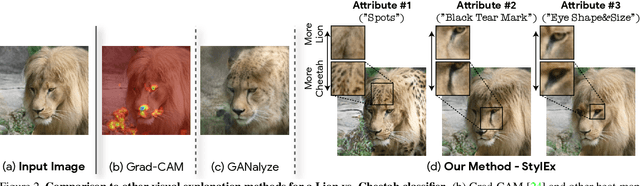
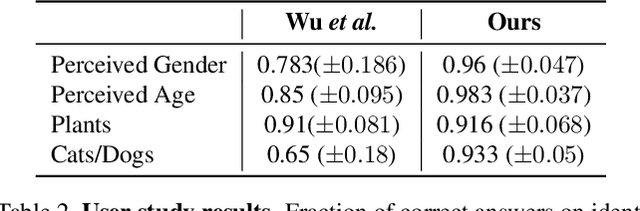
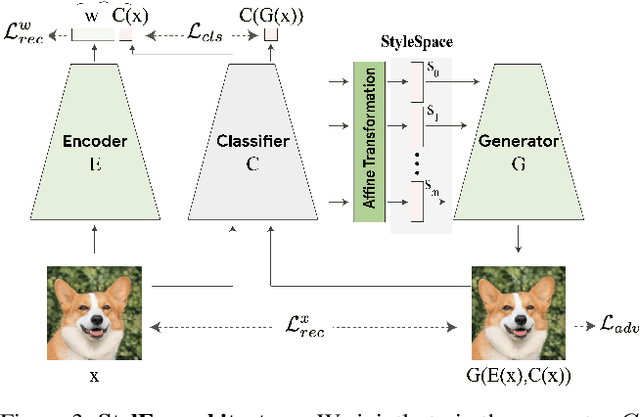
Image classification models can depend on multiple different semantic attributes of the image. An explanation of the decision of the classifier needs to both discover and visualize these properties. Here we present StylEx, a method for doing this, by training a generative model to specifically explain multiple attributes that underlie classifier decisions. A natural source for such attributes is the StyleSpace of StyleGAN, which is known to generate semantically meaningful dimensions in the image. However, because standard GAN training is not dependent on the classifier, it may not represent these attributes which are important for the classifier decision, and the dimensions of StyleSpace may represent irrelevant attributes. To overcome this, we propose a training procedure for a StyleGAN, which incorporates the classifier model, in order to learn a classifier-specific StyleSpace. Explanatory attributes are then selected from this space. These can be used to visualize the effect of changing multiple attributes per image, thus providing image-specific explanations. We apply StylEx to multiple domains, including animals, leaves, faces and retinal images. For these, we show how an image can be modified in different ways to change its classifier output. Our results show that the method finds attributes that align well with semantic ones, generate meaningful image-specific explanations, and are human-interpretable as measured in user-studies.
ML-based Flood Forecasting: Advances in Scale, Accuracy and Reach
Dec 06, 2020
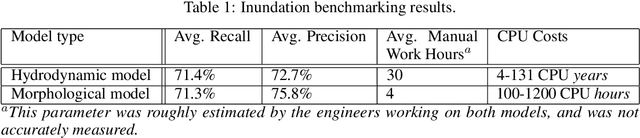
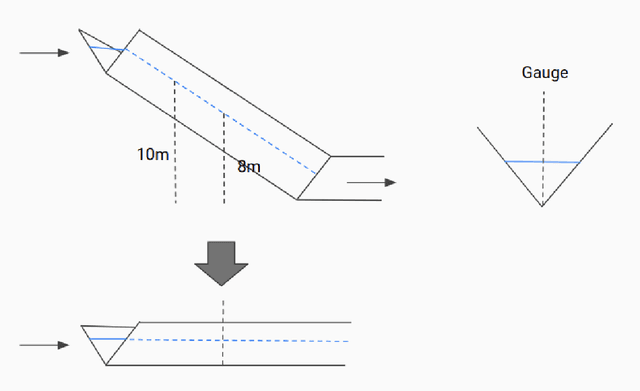
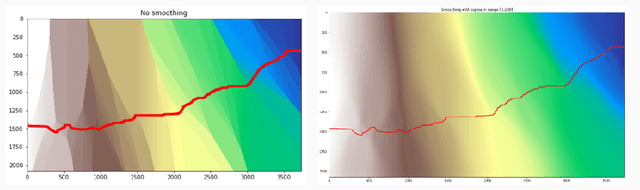
Floods are among the most common and deadly natural disasters in the world, and flood warning systems have been shown to be effective in reducing harm. Yet the majority of the world's vulnerable population does not have access to reliable and actionable warning systems, due to core challenges in scalability, computational costs, and data availability. In this paper we present two components of flood forecasting systems which were developed over the past year, providing access to these critical systems to 75 million people who didn't have this access before.
An Optimal Elimination Algorithm for Learning a Best Arm
Jun 20, 2020We consider the classic problem of $(\epsilon,\delta)$-PAC learning a best arm where the goal is to identify with confidence $1-\delta$ an arm whose mean is an $\epsilon$-approximation to that of the highest mean arm in a multi-armed bandit setting. This problem is one of the most fundamental problems in statistics and learning theory, yet somewhat surprisingly its worst-case sample complexity is not well understood. In this paper, we propose a new approach for $(\epsilon,\delta)$-PAC learning a best arm. This approach leads to an algorithm whose sample complexity converges to \emph{exactly} the optimal sample complexity of $(\epsilon,\delta)$-learning the mean of $n$ arms separately and we complement this result with a conditional matching lower bound. More specifically:
Adversarially Robust Streaming Algorithms via Differential Privacy
Apr 13, 2020A streaming algorithm is said to be adversarially robust if its accuracy guarantees are maintained even when the data stream is chosen maliciously, by an adaptive adversary. We establish a connection between adversarial robustness of streaming algorithms and the notion of differential privacy. This connection allows us to design new adversarially robust streaming algorithms that outperform the current state-of-the-art constructions for many interesting regimes of parameters.
Spectral Algorithm for Low-rank Multitask Regression
Oct 27, 2019

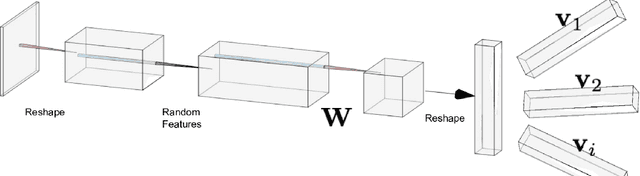
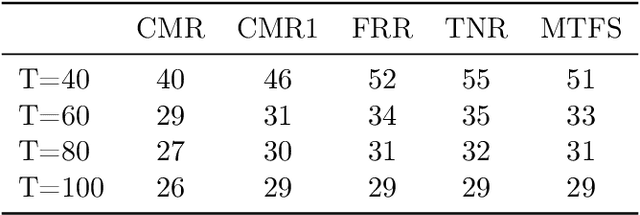
Multitask learning, i.e. taking advantage of the relatedness of individual tasks in order to improve performance on all of them, is a core challenge in the field of machine learning. We focus on matrix regression tasks where the rank of the weight matrix is constrained to reduce sample complexity. We introduce the common mechanism regression (CMR) model which assumes a shared left low-rank component across all tasks, but allows an individual per-task right low-rank component. This dramatically reduces the number of samples needed for accurate estimation. The problem of jointly recovering the common and the local components has a non-convex bi-linear structure. We overcome this hurdle and provide a provably beneficial non-iterative spectral algorithm. Appealingly, the solution has favorable behavior as a function of the number of related tasks and the small number of samples available for each one. We demonstrate the efficacy of our approach for the challenging task of remote river discharge estimation across multiple river sites, where data for each task is naturally scarce. In this scenario sharing a low-rank component between the tasks translates to a shared spectral reflection of the water, which is a true underlying physical model. We also show the benefit of the approach on the markedly different setting of image classification where the common component can be interpreted as the shared convolution filters.
Personalizing ASR for Dysarthric and Accented Speech with Limited Data
Jul 31, 2019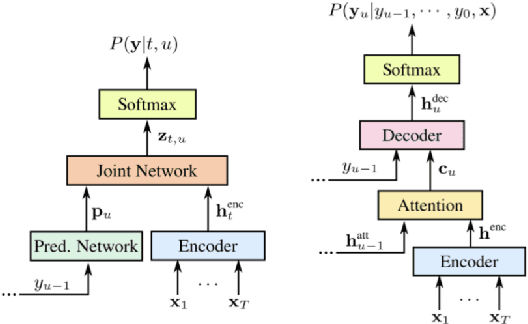
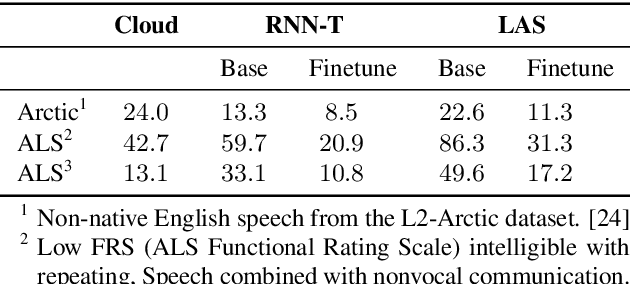
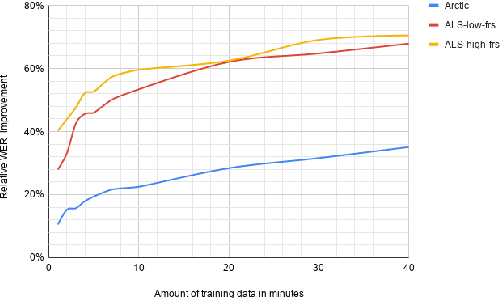
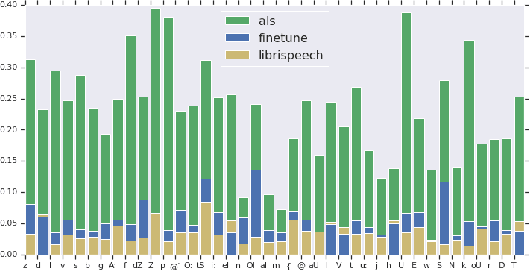
Automatic speech recognition (ASR) systems have dramatically improved over the last few years. ASR systems are most often trained from 'typical' speech, which means that underrepresented groups don't experience the same level of improvement. In this paper, we present and evaluate finetuning techniques to improve ASR for users with non-standard speech. We focus on two types of non-standard speech: speech from people with amyotrophic lateral sclerosis (ALS) and accented speech. We train personalized models that achieve 62% and 35% relative WER improvement on these two groups, bringing the absolute WER for ALS speakers, on a test set of message bank phrases, down to 10% for mild dysarthria and 20% for more serious dysarthria. We show that 71% of the improvement comes from only 5 minutes of training data. Finetuning a particular subset of layers (with many fewer parameters) often gives better results than finetuning the entire model. This is the first step towards building state of the art ASR models for dysarthric speech.
Audio De-identification: A New Entity Recognition Task
Mar 17, 2019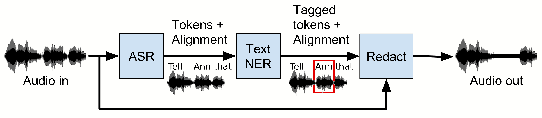
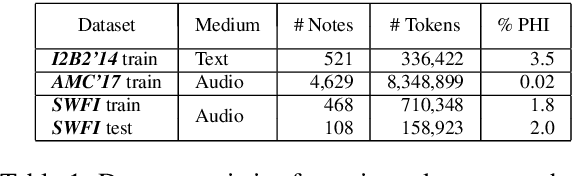
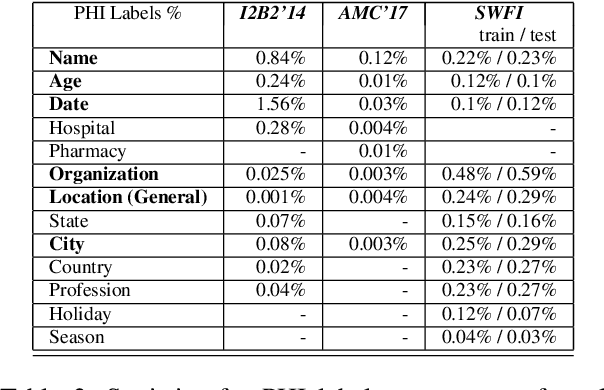
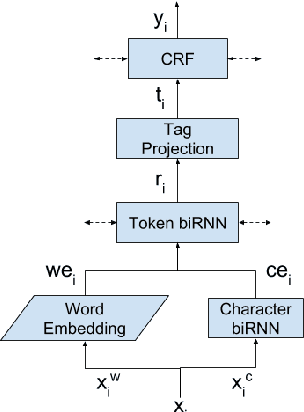
Named Entity Recognition (NER) has been mostly studied in the context of written text. Specifically, NER is an important step in de-identification (de-ID) of medical records, many of which are recorded conversations between a patient and a doctor. In such recordings, audio spans with personal information should be redacted, similar to the redaction of sensitive character spans in de-ID for written text. The application of NER in the context of audio de-identification has yet to be fully investigated. To this end, we define the task of audio de-ID, in which audio spans with entity mentions should be detected. We then present our pipeline for this task, which involves Automatic Speech Recognition (ASR), NER on the transcript text, and text-to-audio alignment. Finally, we introduce a novel metric for audio de-ID and a new evaluation benchmark consisting of a large labeled segment of the Switchboard and Fisher audio datasets and detail our pipeline's results on it.
Learning and Generalization for Matching Problems
Feb 24, 2019
We study a classic algorithmic problem through the lens of statistical learning. That is, we consider a matching problem where the input graph is sampled from some distribution. This distribution is unknown to the algorithm; however, an additional graph which is sampled from the same distribution is given during a training phase (preprocessing). More specifically, the algorithmic problem is to match $k$ out of $n$ items that arrive online to $d$ categories ($d\ll k \ll n$). Our goal is to design a two-stage online algorithm that retains a small subset of items in the first stage which contains an offline matching of maximum weight. We then compute this optimal matching in a second stage. The added statistical component is that before the online matching process begins, our algorithms learn from a training set consisting of another matching instance drawn from the same unknown distribution. Using this training set, we learn a policy that we apply during the online matching process. We consider a class of online policies that we term \emph{thresholds policies}. For this class, we derive uniform convergence results both for the number of retained items and the value of the optimal matching. We show that the number of retained items and the value of the offline optimal matching deviate from their expectation by $O(\sqrt{k})$. This requires usage of less-standard concentration inequalities (standard ones give deviations of $O(\sqrt{n})$). Furthermore, we design an algorithm that outputs the optimal offline solution with high probability while retaining only $O(k\log \log n)$ items in expectation.
ML for Flood Forecasting at Scale
Jan 28, 2019Effective riverine flood forecasting at scale is hindered by a multitude of factors, most notably the need to rely on human calibration in current methodology, the limited amount of data for a specific location, and the computational difficulty of building continent/global level models that are sufficiently accurate. Machine learning (ML) is primed to be useful in this scenario: learned models often surpass human experts in complex high-dimensional scenarios, and the framework of transfer or multitask learning is an appealing solution for leveraging local signals to achieve improved global performance. We propose to build on these strengths and develop ML systems for timely and accurate riverine flood prediction.
Towards Global Remote Discharge Estimation: Using the Few to Estimate The Many
Jan 03, 2019
Learning hydrologic models for accurate riverine flood prediction at scale is a challenge of great importance. One of the key difficulties is the need to rely on in-situ river discharge measurements, which can be quite scarce and unreliable, particularly in regions where floods cause the most damage every year. Accordingly, in this work we tackle the problem of river discharge estimation at different river locations. A core characteristic of the data at hand (e.g. satellite measurements) is that we have few measurements for many locations, all sharing the same physics that underlie the water discharge. We capture this scenario in a simple but powerful common mechanism regression (CMR) model with a local component as well as a shared one which captures the global discharge mechanism. The resulting learning objective is non-convex, but we show that we can find its global optimum by leveraging the power of joining local measurements across sites. In particular, using a spectral initialization with provable near-optimal accuracy, we can find the optimum using standard descent methods. We demonstrate the efficacy of our approach for the problem of discharge estimation using simulations.