 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD'ARTAGNAN: Counterfactual Video Generation
Jun 03, 2022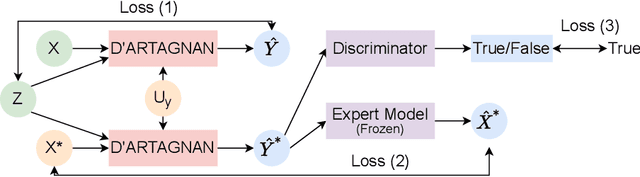


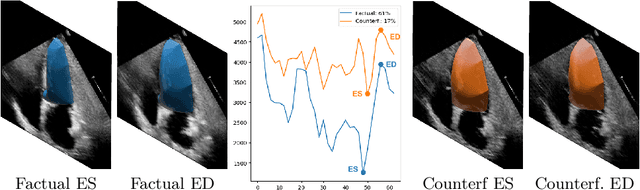
Causally-enabled machine learning frameworks could help clinicians to identify the best course of treatments by answering counterfactual questions. We explore this path for the case of echocardiograms by looking into the variation of the Left Ventricle Ejection Fraction, the most essential clinical metric gained from these examinations. We combine deep neural networks, twin causal networks and generative adversarial methods for the first time to build D'ARTAGNAN (Deep ARtificial Twin-Architecture GeNerAtive Networks), a novel causal generative model. We demonstrate the soundness of our approach on a synthetic dataset before applying it to cardiac ultrasound videos by answering the question: "What would this echocardiogram look like if the patient had a different ejection fraction?". To do so, we generate new ultrasound videos, retaining the video style and anatomy of the original patient, with variations of the Ejection Fraction conditioned on a given input. We achieve an SSIM score of 0.79 and an R2 score of 0.51 on the counterfactual videos. Code and models are available at https://github.com/HReynaud/dartagnan.
Estimating the probabilities of causation via deep monotonic twin networks
Sep 07, 2021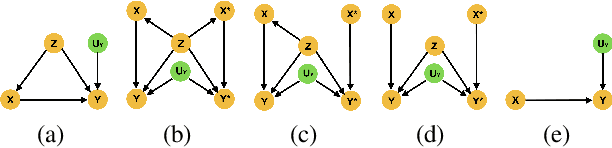

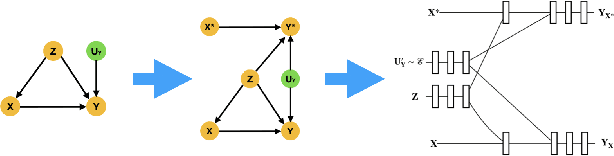

There has been much recent work using machine learning to answer causal queries. Most focus on interventional queries, such as the conditional average treatment effect. However, as noted by Pearl, interventional queries only form part of a larger hierarchy of causal queries, with counterfactuals sitting at the top. Despite this, our community has not fully succeeded in adapting machine learning tools to answer counterfactual queries. This work addresses this challenge by showing how to implement twin network counterfactual inference -- an alternative to abduction, action, & prediction counterfactual inference -- with deep learning to estimate counterfactual queries. We show how the graphical nature of twin networks makes them particularly amenable to deep learning, yielding simple neural network architectures that, when trained, are capable of counterfactual inference. Importantly, we show how to enforce known identifiability constraints during training, ensuring the answer to each counterfactual query is uniquely determined. We demonstrate our approach by using it to accurately estimate the probabilities of causation -- important counterfactual queries that quantify the degree to which one event was a necessary or sufficient cause of another -- on both synthetic and real data.
Detecting Hypo-plastic Left Heart Syndrome in Fetal Ultrasound via Disease-specific Atlas Maps
Jul 06, 2021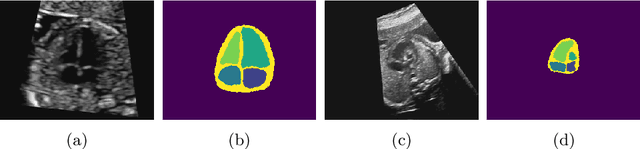
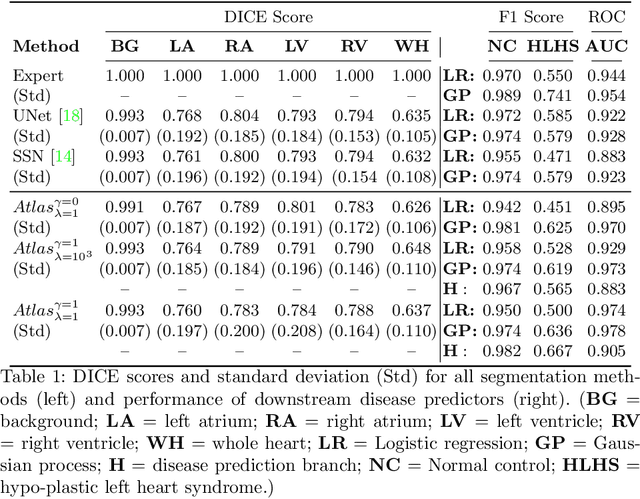

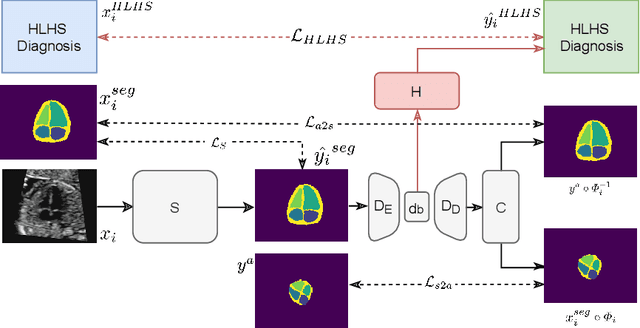
Fetal ultrasound screening during pregnancy plays a vital role in the early detection of fetal malformations which have potential long-term health impacts. The level of skill required to diagnose such malformations from live ultrasound during examination is high and resources for screening are often limited. We present an interpretable, atlas-learning segmentation method for automatic diagnosis of Hypo-plastic Left Heart Syndrome (HLHS) from a single `4 Chamber Heart' view image. We propose to extend the recently introduced Image-and-Spatial Transformer Networks (Atlas-ISTN) into a framework that enables sensitising atlas generation to disease. In this framework we can jointly learn image segmentation, registration, atlas construction and disease prediction while providing a maximum level of clinical interpretability compared to direct image classification methods. As a result our segmentation allows diagnoses competitive with expert-derived manual diagnosis and yields an AUC-ROC of 0.978 (1043 cases for training, 260 for validation and 325 for testing).
Ultrasound Video Transformers for Cardiac Ejection Fraction Estimation
Jul 02, 2021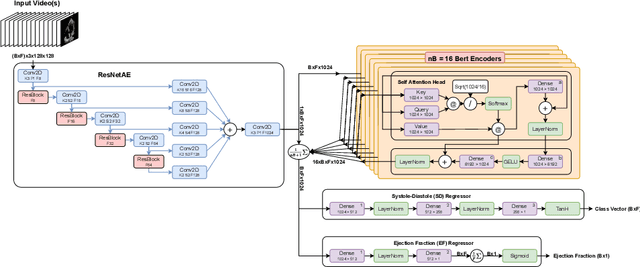
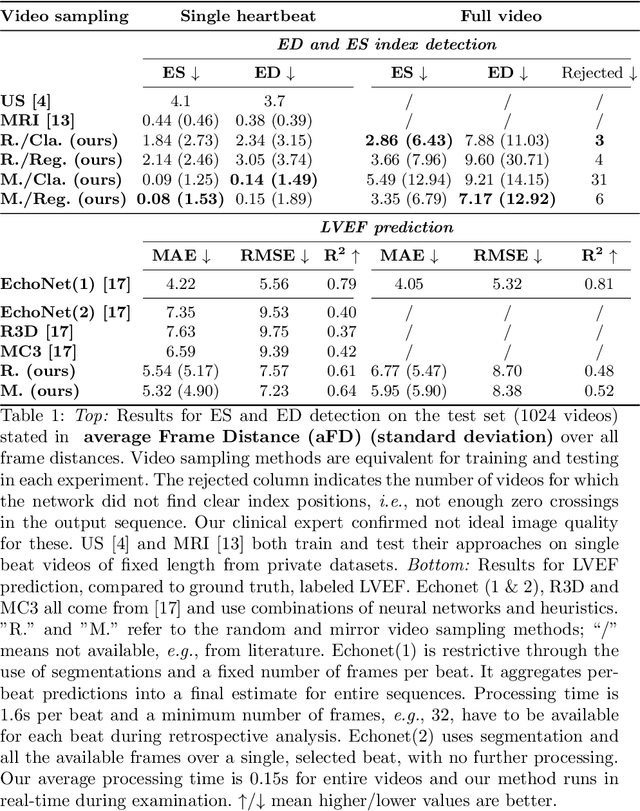
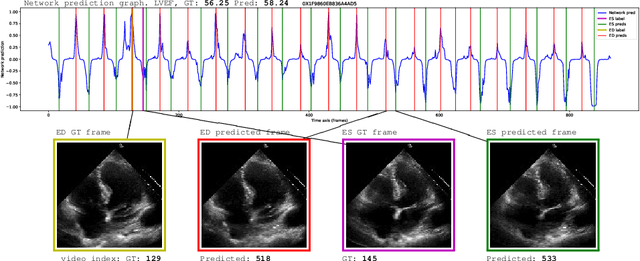
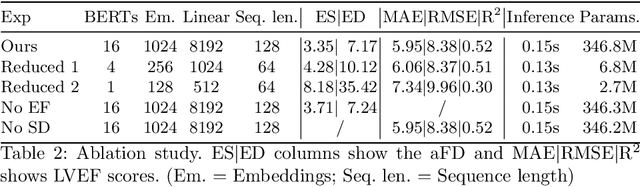
Cardiac ultrasound imaging is used to diagnose various heart diseases. Common analysis pipelines involve manual processing of the video frames by expert clinicians. This suffers from intra- and inter-observer variability. We propose a novel approach to ultrasound video analysis using a transformer architecture based on a Residual Auto-Encoder Network and a BERT model adapted for token classification. This enables videos of any length to be processed. We apply our model to the task of End-Systolic (ES) and End-Diastolic (ED) frame detection and the automated computation of the left ventricular ejection fraction. We achieve an average frame distance of 3.36 frames for the ES and 7.17 frames for the ED on videos of arbitrary length. Our end-to-end learnable approach can estimate the ejection fraction with a MAE of 5.95 and $R^2$ of 0.52 in 0.15s per video, showing that segmentation is not the only way to predict ejection fraction. Code and models are available at https://github.com/HReynaud/UVT.
Video Summarization through Reinforcement Learning with a 3D Spatio-Temporal U-Net
Jun 19, 2021
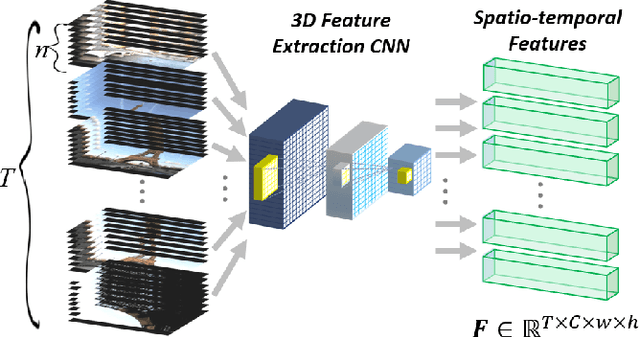
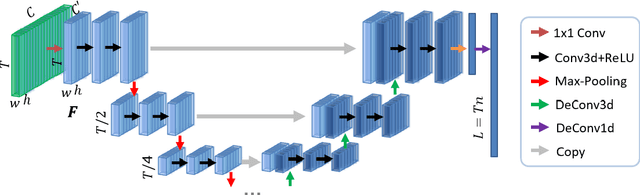
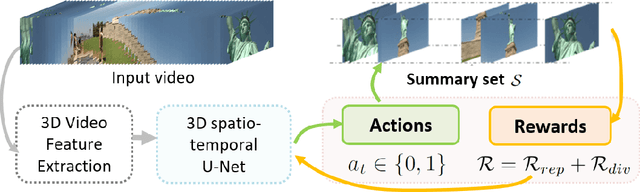
Intelligent video summarization algorithms allow to quickly convey the most relevant information in videos through the identification of the most essential and explanatory content while removing redundant video frames. In this paper, we introduce the 3DST-UNet-RL framework for video summarization. A 3D spatio-temporal U-Net is used to efficiently encode spatio-temporal information of the input videos for downstream reinforcement learning (RL). An RL agent learns from spatio-temporal latent scores and predicts actions for keeping or rejecting a video frame in a video summary. We investigate if real/inflated 3D spatio-temporal CNN features are better suited to learn representations from videos than commonly used 2D image features. Our framework can operate in both, a fully unsupervised mode and a supervised training mode. We analyse the impact of prescribed summary lengths and show experimental evidence for the effectiveness of 3DST-UNet-RL on two commonly used general video summarization benchmarks. We also applied our method on a medical video summarization task. The proposed video summarization method has the potential to save storage costs of ultrasound screening videos as well as to increase efficiency when browsing patient video data during retrospective analysis or audit without loosing essential information
Next-Gen Machine Learning Supported Diagnostic Systems for Spacecraft
Jun 10, 2021Future short or long-term space missions require a new generation of monitoring and diagnostic systems due to communication impasses as well as limitations in specialized crew and equipment. Machine learning supported diagnostic systems present a viable solution for medical and technical applications. We discuss challenges and applicability of such systems in light of upcoming missions and outline an example use case for a next-generation medical diagnostic system for future space operations. Additionally, we present approach recommendations and constraints for the successful generation and use of machine learning models aboard a spacecraft.
Unsupervised Human Pose Estimation through Transforming Shape Templates
May 10, 2021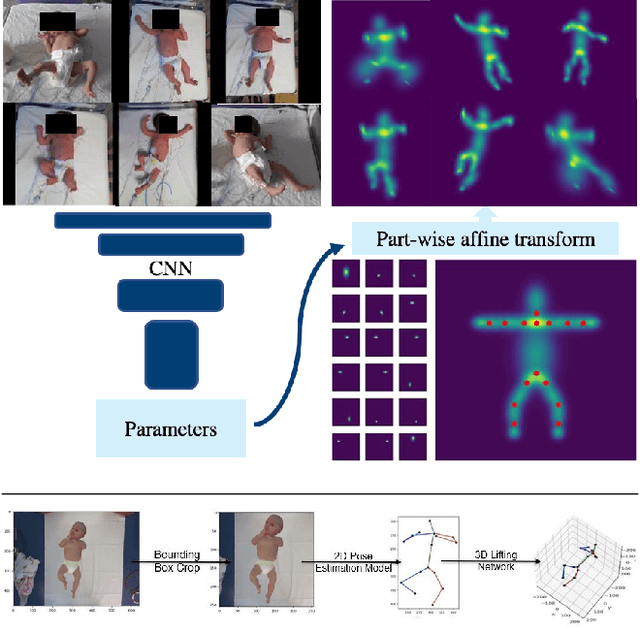

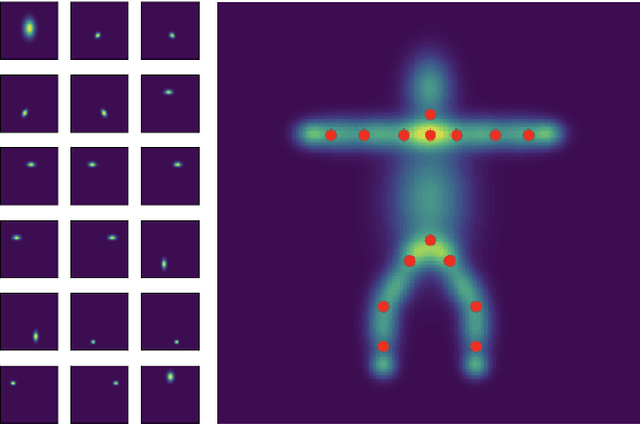
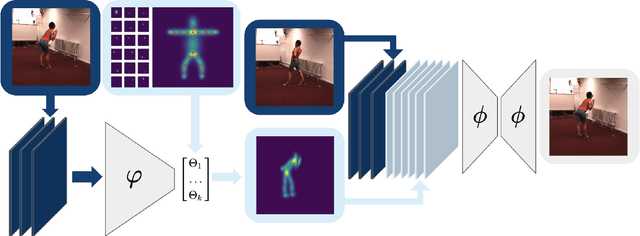
Human pose estimation is a major computer vision problem with applications ranging from augmented reality and video capture to surveillance and movement tracking. In the medical context, the latter may be an important biomarker for neurological impairments in infants. Whilst many methods exist, their application has been limited by the need for well annotated large datasets and the inability to generalize to humans of different shapes and body compositions, e.g. children and infants. In this paper we present a novel method for learning pose estimators for human adults and infants in an unsupervised fashion. We approach this as a learnable template matching problem facilitated by deep feature extractors. Human-interpretable landmarks are estimated by transforming a template consisting of predefined body parts that are characterized by 2D Gaussian distributions. Enforcing a connectivity prior guides our model to meaningful human shape representations. We demonstrate the effectiveness of our approach on two different datasets including adults and infants.
Topological Data Analysis of Database Representations for Information Retrieval
Apr 04, 2021Appropriately representing elements in a database so that queries may be accurately matched is a central task in information retrieval. This recently has been achieved by embedding the graphical structure of the database into a manifold so that the hierarchy is preserved. Persistent homology provides a rigorous characterization for the database topology in terms of both its hierarchy and connectivity structure. We compute persistent homology on a variety of datasets and show that some commonly used embeddings fail to preserve the connectivity. Moreover, we show that embeddings which successfully retain the database topology coincide in persistent homology. We introduce the dilation-invariant bottleneck distance to capture this effect, which addresses metric distortion on manifolds. We use it to show that distances between topology-preserving embeddings of databases are small.
Causal Future Prediction in a Minkowski Space-Time
Aug 30, 2020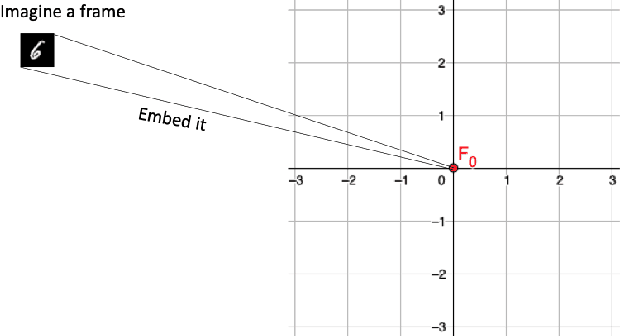
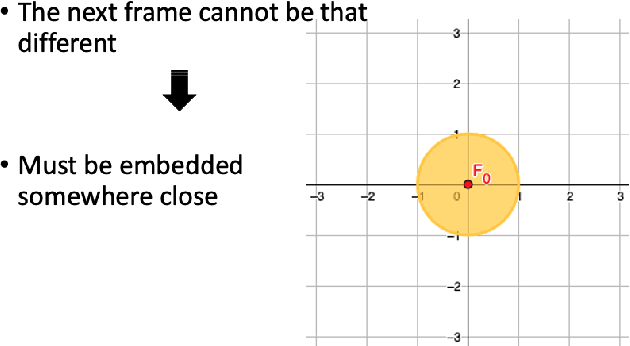
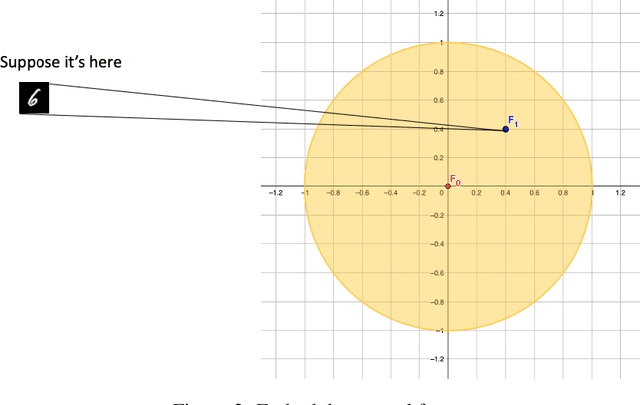
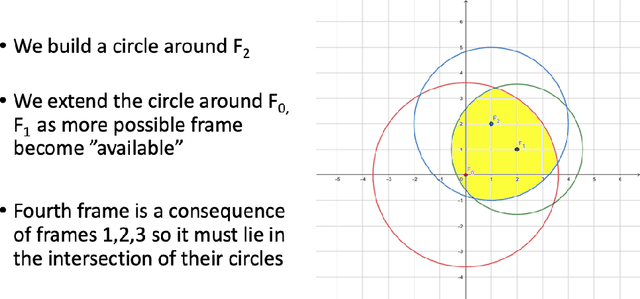
Estimating future events is a difficult task. Unlike humans, machine learning approaches are not regularized by a natural understanding of physics. In the wild, a plausible succession of events is governed by the rules of causality, which cannot easily be derived from a finite training set. In this paper we propose a novel theoretical framework to perform causal future prediction by embedding spatiotemporal information on a Minkowski space-time. We utilize the concept of a light cone from special relativity to restrict and traverse the latent space of an arbitrary model. We demonstrate successful applications in causal image synthesis and future video frame prediction on a dataset of images. Our framework is architecture- and task-independent and comes with strong theoretical guarantees of causal capabilities.
3D Probabilistic Segmentation and Volumetry from 2D projection images
Jun 23, 2020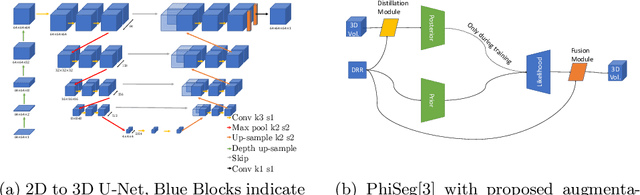
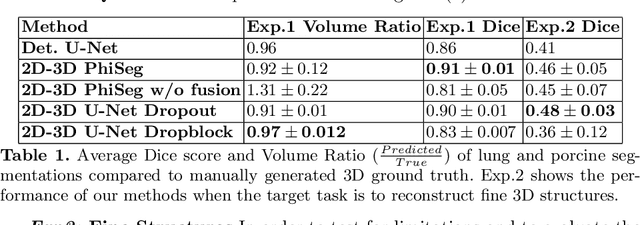

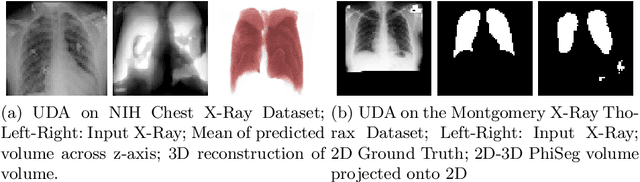
X-Ray imaging is quick, cheap and useful for front-line care assessment and intra-operative real-time imaging (e.g., C-Arm Fluoroscopy). However, it suffers from projective information loss and lacks vital volumetric information on which many essential diagnostic biomarkers are based on. In this paper we explore probabilistic methods to reconstruct 3D volumetric images from 2D imaging modalities and measure the models' performance and confidence. We show our models' performance on large connected structures and we test for limitations regarding fine structures and image domain sensitivity. We utilize fast end-to-end training of a 2D-3D convolutional networks, evaluate our method on 117 CT scans segmenting 3D structures from digitally reconstructed radiographs (DRRs) with a Dice score of $0.91 \pm 0.0013$. Source code will be made available by the time of the conference.