 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unifying Interpretability and Control: Evaluation via Intervention
Nov 07, 2024



With the growing complexity and capability of large language models, a need to understand model reasoning has emerged, often motivated by an underlying goal of controlling and aligning models. While numerous interpretability and steering methods have been proposed as solutions, they are typically designed either for understanding or for control, seldom addressing both, with the connection between interpretation and control more broadly remaining tenuous. Additionally, the lack of standardized applications, motivations, and evaluation metrics makes it difficult to assess these methods' practical utility and efficacy. To address this, we propose intervention as a fundamental goal of interpretability and introduce success criteria to evaluate how well methods are able to control model behavior through interventions. We unify and extend four popular interpretability methods--sparse autoencoders, logit lens, tuned lens, and probing--into an abstract encoder-decoder framework. This framework maps intermediate latent representations to human-interpretable feature spaces, enabling interventions on these interpretable features, which can then be mapped back to latent representations to control model outputs. We introduce two new evaluation metrics: intervention success rate and the coherence-intervention tradeoff, designed to measure the accuracy of explanations and their utility in controlling model behavior. Our findings reveal that (1) although current methods allow for intervention, they are inconsistent across models and features, (2) lens-based methods outperform others in achieving simple, concrete interventions, and (3) interventions often compromise model performance and coherence, underperforming simpler alternatives, such as prompting, for steering model behavior and highlighting a critical shortcoming of current interpretability approaches in real-world applications requiring control.
Racing Thoughts: Explaining Large Language Model Contextualization Errors
Oct 02, 2024



The profound success of transformer-based language models can largely be attributed to their ability to integrate relevant contextual information from an input sequence in order to generate a response or complete a task. However, we know very little about the algorithms that a model employs to implement this capability, nor do we understand their failure modes. For example, given the prompt "John is going fishing, so he walks over to the bank. Can he make an ATM transaction?", a model may incorrectly respond "Yes" if it has not properly contextualized "bank" as a geographical feature, rather than a financial institution. We propose the LLM Race Conditions Hypothesis as an explanation of contextualization errors of this form. This hypothesis identifies dependencies between tokens (e.g., "bank" must be properly contextualized before the final token, "?", integrates information from "bank"), and claims that contextualization errors are a result of violating these dependencies. Using a variety of techniques from mechanistic intepretability, we provide correlational and causal evidence in support of the hypothesis, and suggest inference-time interventions to address it.
When Can Transformers Count to n?
Jul 21, 2024Large language models based on the transformer architectures can solve highly complex tasks. But are there simple tasks that such models cannot solve? Here we focus on very simple counting tasks, that involve counting how many times a token in the vocabulary have appeared in a string. We show that if the dimension of the transformer state is linear in the context length, this task can be solved. However, the solution we propose does not scale beyond this limit, and we provide theoretical arguments for why it is likely impossible for a size limited transformer to implement this task. Our empirical results demonstrate the same phase-transition in performance, as anticipated by the theoretical argument. Our results demonstrate the importance of understanding how transformers can solve simple tasks.
Who's asking? User personas and the mechanics of latent misalignment
Jun 17, 2024



Despite investments in improving model safety, studies show that misaligned capabilities remain latent in safety-tuned models. In this work, we shed light on the mechanics of this phenomenon. First, we show that even when model generations are safe, harmful content can persist in hidden representations and can be extracted by decoding from earlier layers. Then, we show that whether the model divulges such content depends significantly on its perception of who it is talking to, which we refer to as user persona. In fact, we find manipulating user persona to be even more effective for eliciting harmful content than direct attempts to control model refusal. We study both natural language prompting and activation steering as control methods and show that activation steering is significantly more effective at bypassing safety filters. We investigate why certain personas break model safeguards and find that they enable the model to form more charitable interpretations of otherwise dangerous queries. Finally, we show we can predict a persona's effect on refusal given only the geometry of its steering vector.
Patchscopes: A Unifying Framework for Inspecting Hidden Representations of Language Models
Jan 12, 2024



Inspecting the information encoded in hidden representations of large language models (LLMs) can explain models' behavior and verify their alignment with human values. Given the capabilities of LLMs in generating human-understandable text, we propose leveraging the model itself to explain its internal representations in natural language. We introduce a framework called Patchscopes and show how it can be used to answer a wide range of questions about an LLM's computation. We show that prior interpretability methods based on projecting representations into the vocabulary space and intervening on the LLM computation can be viewed as instances of this framework. Moreover, several of their shortcomings such as failure in inspecting early layers or lack of expressivity can be mitigated by Patchscopes. Beyond unifying prior inspection techniques, Patchscopes also opens up new possibilities such as using a more capable model to explain the representations of a smaller model, and unlocks new applications such as self-correction in multi-hop reasoning.
Interpretability Illusions in the Generalization of Simplified Models
Dec 06, 2023



A common method to study deep learning systems is to use simplified model representations -- for example, using singular value decomposition to visualize the model's hidden states in a lower dimensional space. This approach assumes that the results of these simplified are faithful to the original model. Here, we illustrate an important caveat to this assumption: even if the simplified representations can accurately approximate the full model on the training set, they may fail to accurately capture the model's behavior out of distribution -- the understanding developed from simplified representations may be an illusion. We illustrate this by training Transformer models on controlled datasets with systematic generalization splits. First, we train models on the Dyck balanced-parenthesis languages. We simplify these models using tools like dimensionality reduction and clustering, and then explicitly test how these simplified proxies match the behavior of the original model on various out-of-distribution test sets. We find that the simplified proxies are generally less faithful out of distribution. In cases where the original model generalizes to novel structures or deeper depths, the simplified versions may fail, or generalize better. This finding holds even if the simplified representations do not directly depend on the training distribution. Next, we study a more naturalistic task: predicting the next character in a dataset of computer code. We find similar generalization gaps between the original model and simplified proxies, and conduct further analysis to investigate which aspects of the code completion task are associated with the largest gaps. Together, our results raise questions about the extent to which mechanistic interpretations derived using tools like SVD can reliably predict what a model will do in novel situations.
Post Hoc Explanations of Language Models Can Improve Language Models
May 19, 2023



Large Language Models (LLMs) have demonstrated remarkable capabilities in performing complex tasks. Moreover, recent research has shown that incorporating human-annotated rationales (e.g., Chain-of- Thought prompting) during in-context learning can significantly enhance the performance of these models, particularly on tasks that require reasoning capabilities. However, incorporating such rationales poses challenges in terms of scalability as this requires a high degree of human involvement. In this work, we present a novel framework, Amplifying Model Performance by Leveraging In-Context Learning with Post Hoc Explanations (AMPLIFY), which addresses the aforementioned challenges by automating the process of rationale generation. To this end, we leverage post hoc explanation methods which output attribution scores (explanations) capturing the influence of each of the input features on model predictions. More specifically, we construct automated natural language rationales that embed insights from post hoc explanations to provide corrective signals to LLMs. Extensive experimentation with real-world datasets demonstrates that our framework, AMPLIFY, leads to prediction accuracy improvements of about 10-25% over a wide range of tasks, including those where prior approaches which rely on human-annotated rationales such as Chain-of-Thought prompting fall short. Our work makes one of the first attempts at highlighting the potential of post hoc explanations as valuable tools for enhancing the effectiveness of LLMs. Furthermore, we conduct additional empirical analyses and ablation studies to demonstrate the impact of each of the components of AMPLIFY, which, in turn, lead to critical insights for refining in-context learning.
Mixed Effects Random Forests for Personalised Predictions of Clinical Depression Severity
Jan 24, 2023



This work demonstrates how mixed effects random forests enable accurate predictions of depression severity using multimodal physiological and digital activity data collected from an 8-week study involving 31 patients with major depressive disorder. We show that mixed effects random forests outperform standard random forests and personal average baselines when predicting clinical Hamilton Depression Rating Scale scores (HDRS_17). Compared to the latter baseline, accuracy is significantly improved for each patient by an average of 0.199-0.276 in terms of mean absolute error (p<0.05). This is noteworthy as these simple baselines frequently outperform machine learning methods in mental health prediction tasks. We suggest that this improved performance results from the ability of the mixed effects random forest to personalise model parameters to individuals in the dataset. However, we find that these improvements pertain exclusively to scenarios where labelled patient data are available to the model at training time. Investigating methods that improve accuracy when generalising to new patients is left as important future work.
Does Localization Inform Editing? Surprising Differences in Causality-Based Localization vs. Knowledge Editing in Language Models
Jan 10, 2023



Language models are known to learn a great quantity of factual information during pretraining, and recent work localizes this information to specific model weights like mid-layer MLP weights (Meng et al., 2022). In this paper, we find that we can change how a fact is stored in a model by editing weights that are in a different location than where existing methods suggest that the fact is stored. This is surprising because we would expect that localizing facts to specific parameters in models would tell us where to manipulate knowledge in models, and this assumption has motivated past work on model editing methods. Specifically, we show that localization conclusions from representation denoising (also known as Causal Tracing) do not provide any insight into which model MLP layer would be best to edit in order to override an existing stored fact with a new one. This finding raises questions about how past work relies on Causal Tracing to select which model layers to edit (Meng et al., 2022). Next, to better understand the discrepancy between representation denoising and weight editing, we develop several variants of the editing problem that appear more and more like representation denoising in their design and objective. Experiments show that, for one of our editing problems, editing performance does relate to localization results from representation denoising, but we find that which layer we edit is a far better predictor of performance. Our results suggest, counterintuitively, that better mechanistic understanding of how pretrained language models work may not always translate to insights about how to best change their behavior. Code is available at: https://github.com/google/belief-localization
DISSECT: Disentangled Simultaneous Explanations via Concept Traversals
May 31, 2021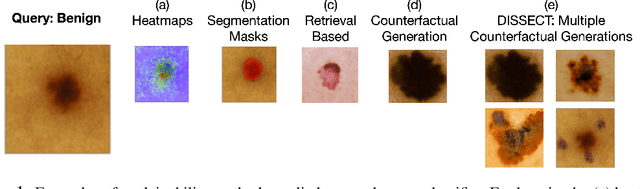


Explaining deep learning model inferences is a promising venue for scientific understanding, improving safety, uncovering hidden biases, evaluating fairness, and beyond, as argued by many scholars. One of the principal benefits of counterfactual explanations is allowing users to explore "what-if" scenarios through what does not and cannot exist in the data, a quality that many other forms of explanation such as heatmaps and influence functions are inherently incapable of doing. However, most previous work on generative explainability cannot disentangle important concepts effectively, produces unrealistic examples, or fails to retain relevant information. We propose a novel approach, DISSECT, that jointly trains a generator, a discriminator, and a concept disentangler to overcome such challenges using little supervision. DISSECT generates Concept Traversals (CTs), defined as a sequence of generated examples with increasing degrees of concepts that influence a classifier's decision. By training a generative model from a classifier's signal, DISSECT offers a way to discover a classifier's inherent "notion" of distinct concepts automatically rather than rely on user-predefined concepts. We show that DISSECT produces CTs that (1) disentangle several concepts, (2) are influential to a classifier's decision and are coupled to its reasoning due to joint training (3), are realistic, (4) preserve relevant information, and (5) are stable across similar inputs. We validate DISSECT on several challenging synthetic and realistic datasets where previous methods fall short of satisfying desirable criteria for interpretability and show that it performs consistently well and better than existing methods. Finally, we present experiments showing applications of DISSECT for detecting potential biases of a classifier and identifying spurious artifacts that impact predictions.