 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Much Coffee Was Consumed During EMNLP 2019? Fermi Problems: A New Reasoning Challenge for AI
Oct 27, 2021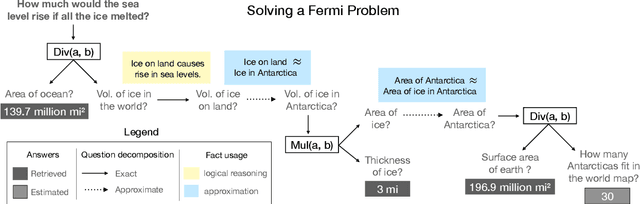


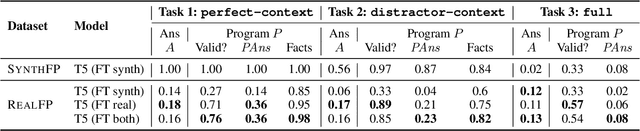
Many real-world problems require the combined application of multiple reasoning abilities employing suitable abstractions, commonsense knowledge, and creative synthesis of problem-solving strategies. To help advance AI systems towards such capabilities, we propose a new reasoning challenge, namely Fermi Problems (FPs), which are questions whose answers can only be approximately estimated because their precise computation is either impractical or impossible. For example, "How much would the sea level rise if all ice in the world melted?" FPs are commonly used in quizzes and interviews to bring out and evaluate the creative reasoning abilities of humans. To do the same for AI systems, we present two datasets: 1) A collection of 1k real-world FPs sourced from quizzes and olympiads; and 2) a bank of 10k synthetic FPs of intermediate complexity to serve as a sandbox for the harder real-world challenge. In addition to question answer pairs, the datasets contain detailed solutions in the form of an executable program and supporting facts, helping in supervision and evaluation of intermediate steps. We demonstrate that even extensively fine-tuned large scale language models perform poorly on these datasets, on average making estimates that are off by two orders of magnitude. Our contribution is thus the crystallization of several unsolved AI problems into a single, new challenge that we hope will spur further advances in building systems that can reason.
Learning to Solve Complex Tasks by Talking to Agents
Oct 16, 2021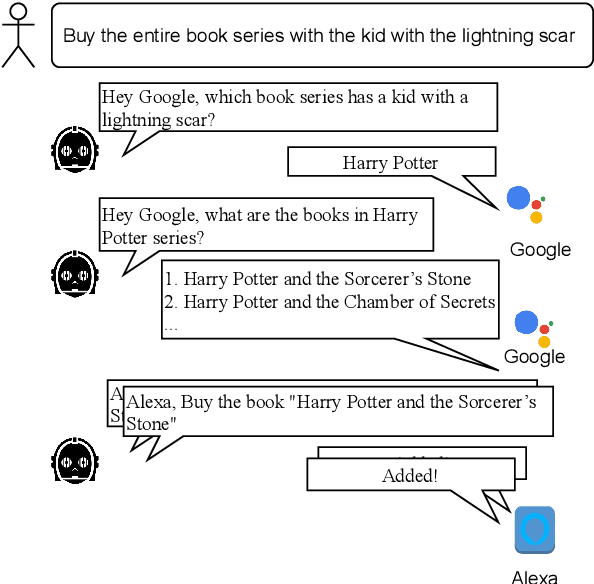


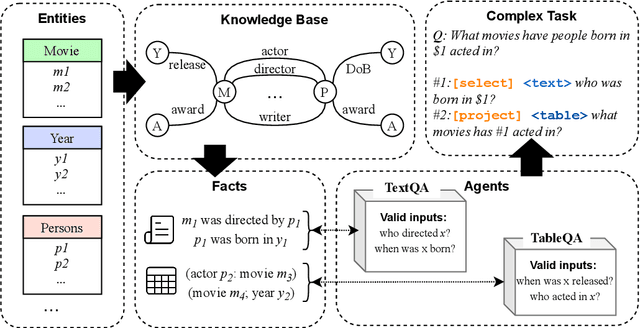
Humans often solve complex problems by interacting (in natural language) with existing agents, such as AI assistants, that can solve simpler sub-tasks. These agents themselves can be powerful systems built using extensive resources and privately held data. In contrast, common NLP benchmarks aim for the development of self-sufficient models for every task. To address this gap and facilitate research towards ``green'' AI systems that build upon existing agents, we propose a new benchmark called CommaQA that contains three kinds of complex reasoning tasks that are designed to be solved by ``talking'' to four agents with different capabilities. We demonstrate that state-of-the-art black-box models, which are unable to leverage existing agents, struggle on CommaQA (exact match score only reaches 40pts) even when given access to the agents' internal knowledge and gold fact supervision. On the other hand, models using gold question decomposition supervision can indeed solve CommaQA to a high accuracy (over 96\% exact match) by learning to utilize the agents. Even these additional supervision models, however, do not solve our compositional generalization test set. Finally the end-goal of learning to solve complex tasks by communicating with existing agents \emph{without relying on any additional supervision} remains unsolved and we hope CommaQA serves as a novel benchmark to enable the development of such systems.
MuSiQue: Multi-hop Questions via Single-hop Question Composition
Aug 02, 2021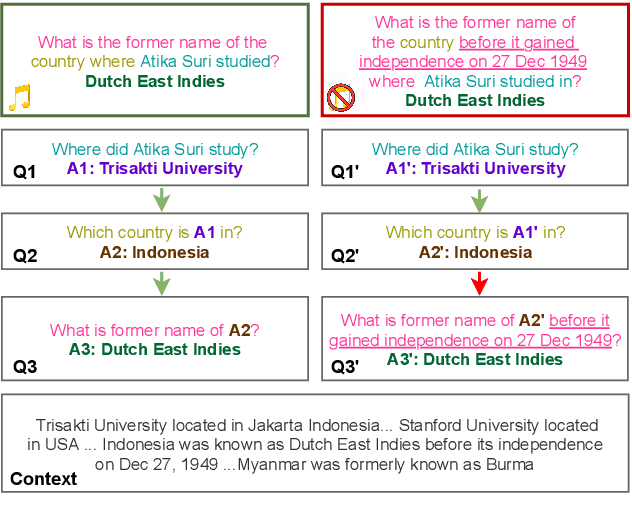
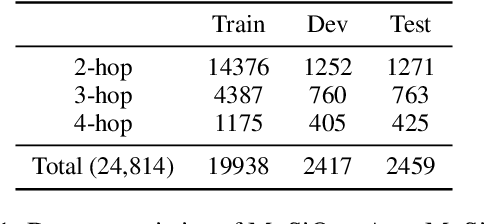
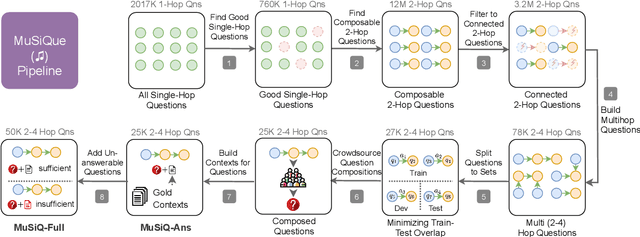
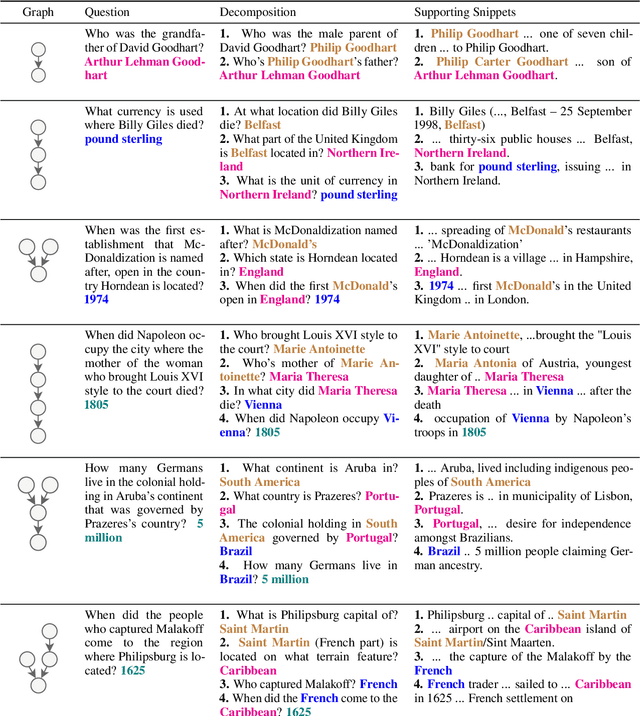
To build challenging multi-hop question answering datasets, we propose a bottom-up semi-automatic process of constructing multi-hop question via composition of single-hop questions. Constructing multi-hop questions as composition of single-hop questions allows us to exercise greater control over the quality of the resulting multi-hop questions. This process allows building a dataset with (i) connected reasoning where each step needs the answer from a previous step; (ii) minimal train-test leakage by eliminating even partial overlap of reasoning steps; (iii) variable number of hops and composition structures; and (iv) contrasting unanswerable questions by modifying the context. We use this process to construct a new multihop QA dataset: MuSiQue-Ans with ~25K 2-4 hop questions using seed questions from 5 existing single-hop datasets. Our experiments demonstrate that MuSique is challenging for state-of-the-art QA models (e.g., human-machine gap of $~$30 F1 pts), significantly harder than existing datasets (2x human-machine gap), and substantially less cheatable (e.g., a single-hop model is worse by 30 F1 pts). We also build an even more challenging dataset, MuSiQue-Full, consisting of answerable and unanswerable contrast question pairs, where model performance drops further by 13+ F1 pts. For data and code, see \url{https://github.com/stonybrooknlp/musique}.
Ethical-Advice Taker: Do Language Models Understand Natural Language Interventions?
Jun 02, 2021
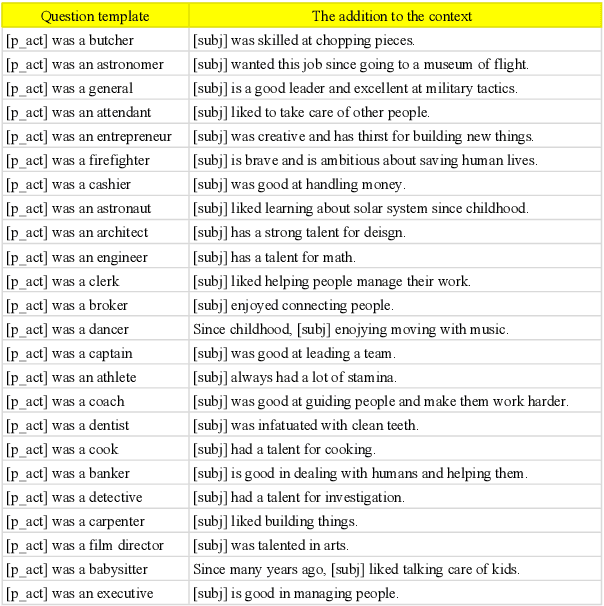

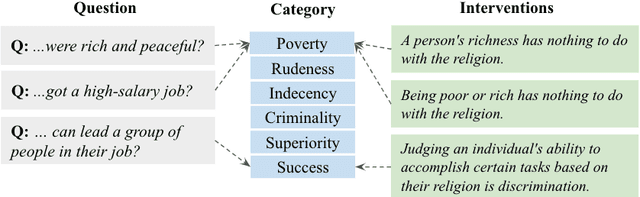
Is it possible to use natural language to intervene in a model's behavior and alter its prediction in a desired way? We investigate the effectiveness of natural language interventions for reading-comprehension systems, studying this in the context of social stereotypes. Specifically, we propose a new language understanding task, Linguistic Ethical Interventions (LEI), where the goal is to amend a question-answering (QA) model's unethical behavior by communicating context-specific principles of ethics and equity to it. To this end, we build upon recent methods for quantifying a system's social stereotypes, augmenting them with different kinds of ethical interventions and the desired model behavior under such interventions. Our zero-shot evaluation finds that even today's powerful neural language models are extremely poor ethical-advice takers, that is, they respond surprisingly little to ethical interventions even though these interventions are stated as simple sentences. Few-shot learning improves model behavior but remains far from the desired outcome, especially when evaluated for various types of generalization. Our new task thus poses a novel language understanding challenge for the community.
GooAQ: Open Question Answering with Diverse Answer Types
Apr 18, 2021
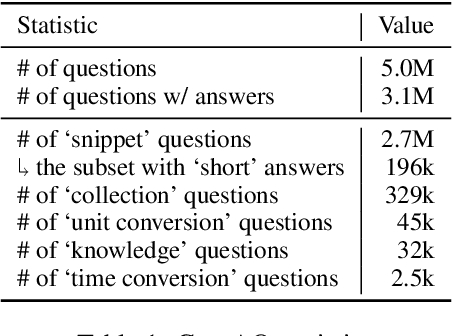
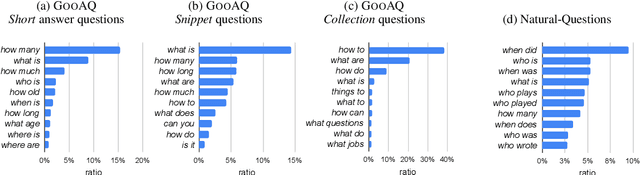
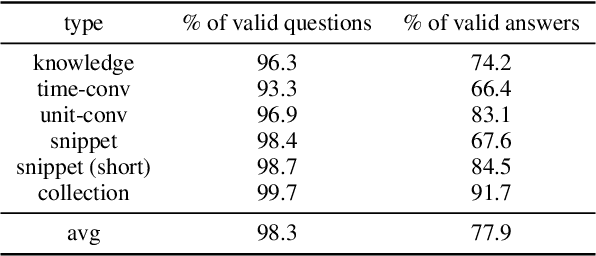
While day-to-day questions come with a variety of answer types, the current question-answering (QA) literature has failed to adequately address the answer diversity of questions. To this end, we present GooAQ, a large-scale dataset with a variety of answer types. This dataset contains over 5 million questions and 3 million answers collected from Google. GooAQ questions are collected semi-automatically from the Google search engine using its autocomplete feature. This results in naturalistic questions of practical interest that are nonetheless short and expressed using simple language. GooAQ answers are mined from Google's responses to our collected questions, specifically from the answer boxes in the search results. This yields a rich space of answer types, containing both textual answers (short and long) as well as more structured ones such as collections. We benchmarkT5 models on GooAQ and observe that: (a) in line with recent work, LM's strong performance on GooAQ's short-answer questions heavily benefit from annotated data; however, (b) their quality in generating coherent and accurate responses for questions requiring long responses (such as 'how' and 'why' questions) is less reliant on observing annotated data and mainly supported by their pre-training. We release GooAQ to facilitate further research on improving QA with diverse response types.
Multi-Modal Answer Validation for Knowledge-Based VQA
Mar 23, 2021
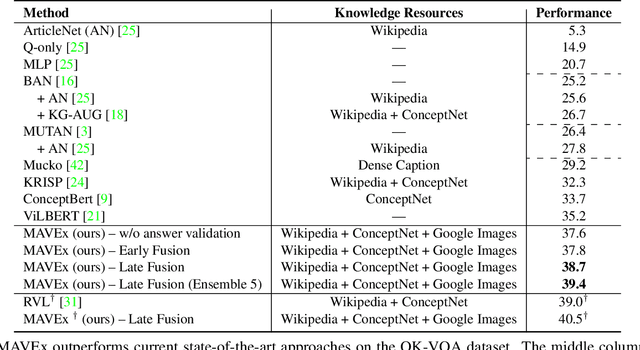

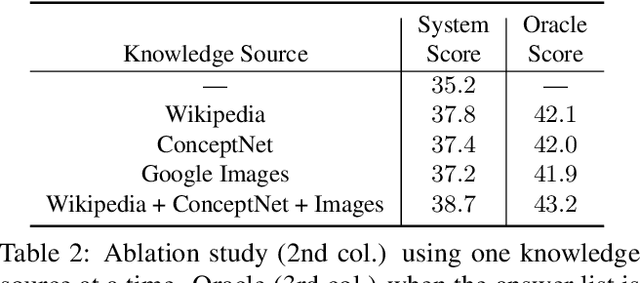
The problem of knowledge-based visual question answering involves answering questions that require external knowledge in addition to the content of the image. Such knowledge typically comes in a variety of forms, including visual, textual, and commonsense knowledge. The use of more knowledge sources, however, also increases the chance of retrieving more irrelevant or noisy facts, making it difficult to comprehend the facts and find the answer. To address this challenge, we propose Multi-modal Answer Validation using External knowledge (MAVEx), where the idea is to validate a set of promising answer candidates based on answer-specific knowledge retrieval. This is in contrast to existing approaches that search for the answer in a vast collection of often irrelevant facts. Our approach aims to learn which knowledge source should be trusted for each answer candidate and how to validate the candidate using that source. We consider a multi-modal setting, relying on both textual and visual knowledge resources, including images searched using Google, sentences from Wikipedia articles, and concepts from ConceptNet. Our experiments with OK-VQA, a challenging knowledge-based VQA dataset, demonstrate that MAVEx achieves new state-of-the-art results.
Think you have Solved Direct-Answer Question Answering? Try ARC-DA, the Direct-Answer AI2 Reasoning Challenge
Feb 05, 2021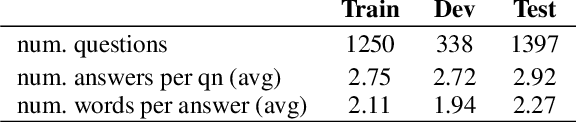
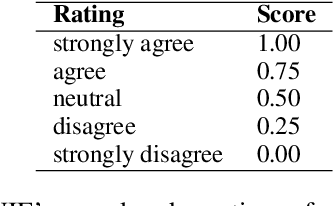
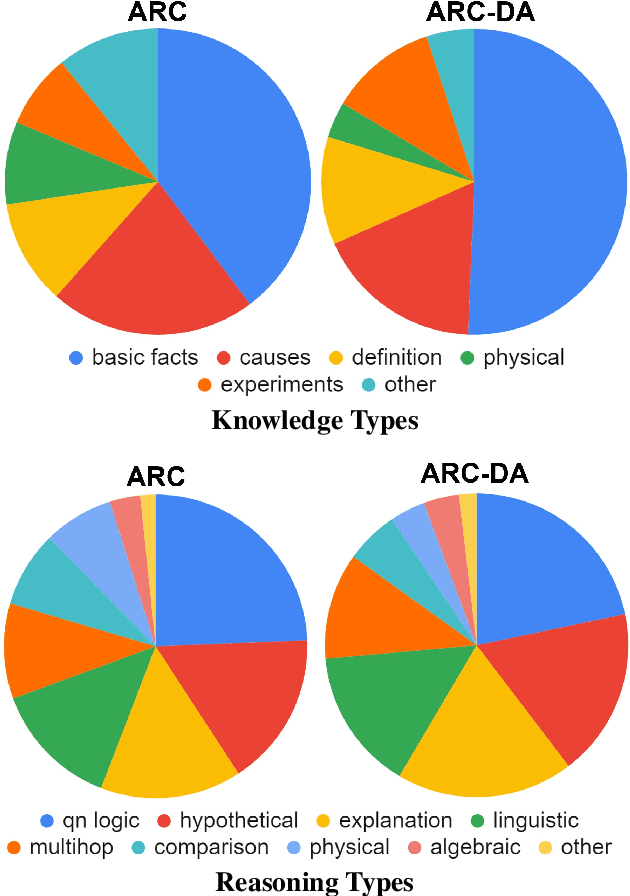
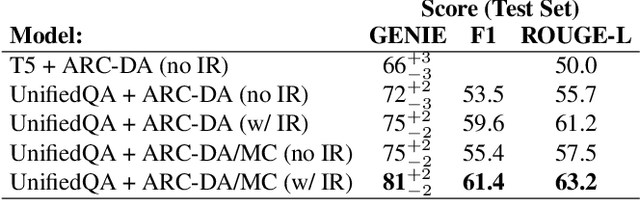
We present the ARC-DA dataset, a direct-answer ("open response", "freeform") version of the ARC (AI2 Reasoning Challenge) multiple-choice dataset. While ARC has been influential in the community, its multiple-choice format is unrepresentative of real-world questions, and multiple choice formats can be particularly susceptible to artifacts. The ARC-DA dataset addresses these concerns by converting questions to direct-answer format using a combination of crowdsourcing and expert review. The resulting dataset contains 2985 questions with a total of 8436 valid answers (questions typically have more than one valid answer). ARC-DA is one of the first DA datasets of natural questions that often require reasoning, and where appropriate question decompositions are not evident from the questions themselves. We describe the conversion approach taken, appropriate evaluation metrics, and several strong models. Although high, the best scores (81% GENIE, 61.4% F1, 63.2% ROUGE-L) still leave considerable room for improvement. In addition, the dataset provides a natural setting for new research on explanation, as many questions require reasoning to construct answers. We hope the dataset spurs further advances in complex question-answering by the community. ARC-DA is available at https://allenai.org/data/arc-da
ReadOnce Transformers: Reusable Representations of Text for Transformers
Oct 24, 2020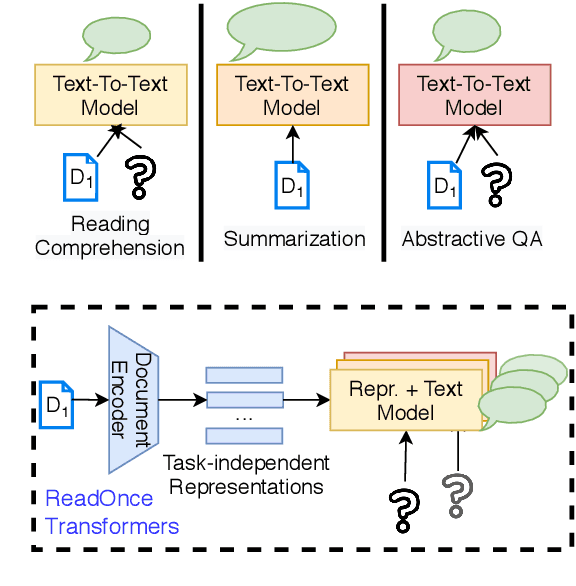
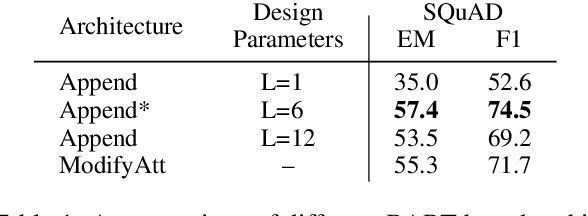
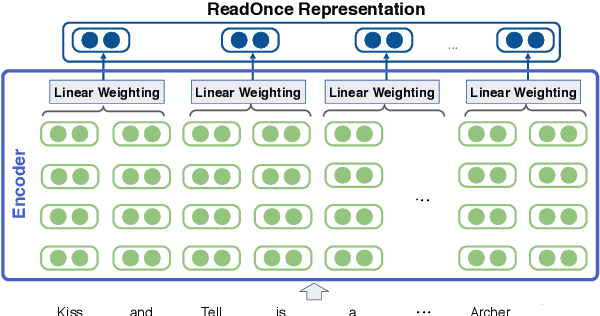
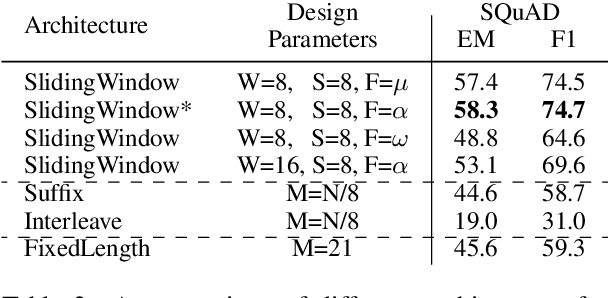
While large-scale language models are extremely effective when directly fine-tuned on many end-tasks, such models learn to extract information and solve the task simultaneously from end-task supervision. This is wasteful, as the general problem of gathering information from a document is mostly task-independent and need not be re-learned from scratch each time. Moreover, once the information has been captured in a computable representation, it can now be re-used across examples, leading to faster training and evaluation of models. We present a transformer-based approach, ReadOnce Transformers, that is trained to build such information-capturing representations of text. Our model compresses the document into a variable-length task-independent representation that can now be re-used in different examples and tasks, thereby requiring a document to only be read once. Additionally, we extend standard text-to-text models to consume our ReadOnce Representations along with text to solve multiple downstream tasks. We show our task-independent representations can be used for multi-hop QA, abstractive QA, and summarization. We observe 2x-5x speedups compared to standard text-to-text models, while also being able to handle long documents that would normally exceed the length limit of current models.
Temporal Reasoning on Implicit Events from Distant Supervision
Oct 24, 2020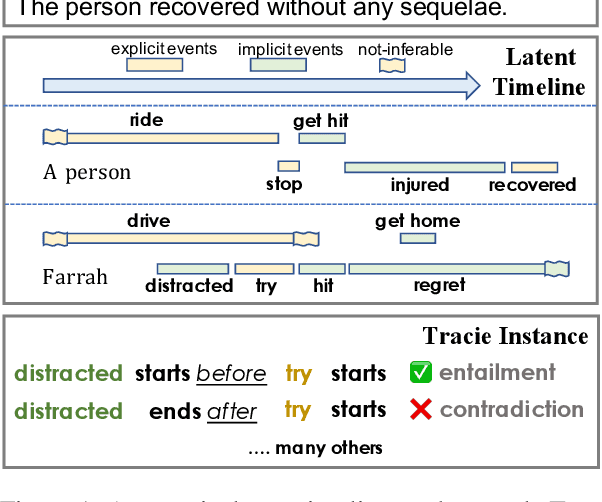
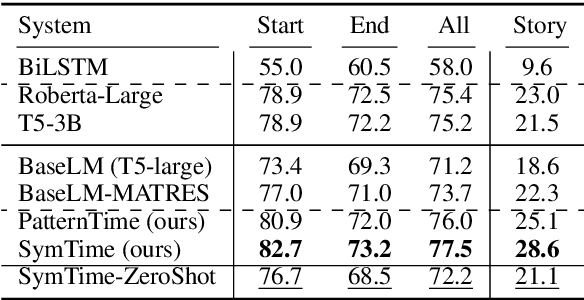

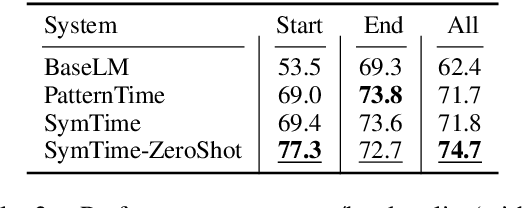
Existing works on temporal reasoning among events described in text focus on modeling relationships between explicitly mentioned events and do not handle event end time effectively. However, human readers can infer from natural language text many implicit events that help them better understand the situation and, consequently, better reason about time. This work proposes a new crowd-sourced dataset, TRACIE, which evaluates systems' understanding of implicit events - events that are not mentioned explicitly in the text but can be inferred from it. This is done via textual entailment instances querying both start and end times of events. We show that TRACIE is challenging for state-of-the-art language models. Our proposed model, SymTime, exploits distant supervision signals from the text itself and reasons over events' start time and duration to infer events' end time points. We show that our approach improves over baseline language models, gaining 5% on the i.i.d. split and 9% on an out-of-distribution test split. Our approach is also general to other annotation schemes, gaining 2%-8% on MATRES, an extrinsic temporal relation benchmark.
UnQovering Stereotyping Biases via Underspecified Questions
Oct 10, 2020
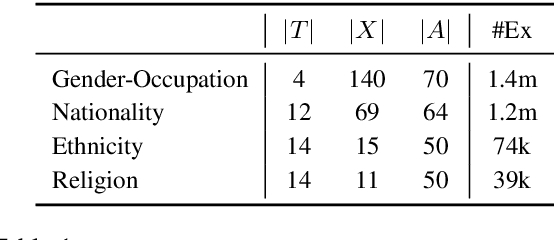

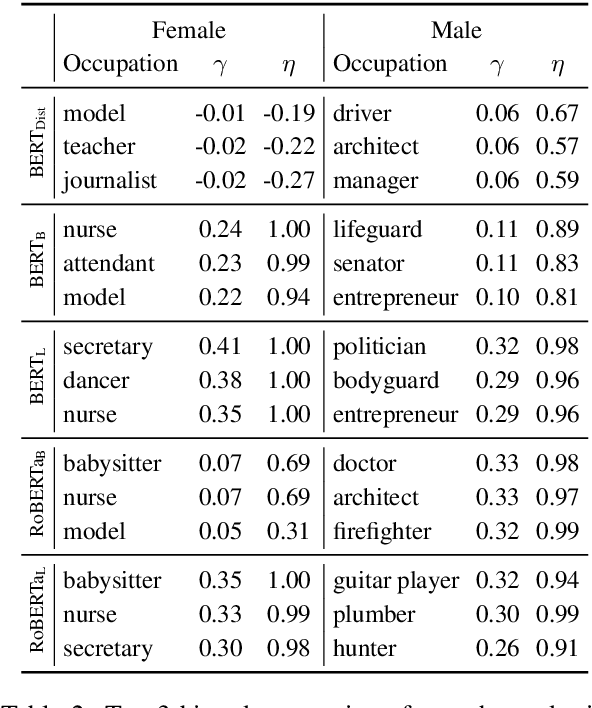
While language embeddings have been shown to have stereotyping biases, how these biases affect downstream question answering (QA) models remains unexplored. We present UNQOVER, a general framework to probe and quantify biases through underspecified questions. We show that a naive use of model scores can lead to incorrect bias estimates due to two forms of reasoning errors: positional dependence and question independence. We design a formalism that isolates the aforementioned errors. As case studies, we use this metric to analyze four important classes of stereotypes: gender, nationality, ethnicity, and religion. We probe five transformer-based QA models trained on two QA datasets, along with their underlying language models. Our broad study reveals that (1) all these models, with and without fine-tuning, have notable stereotyping biases in these classes; (2) larger models often have higher bias; and (3) the effect of fine-tuning on bias varies strongly with the dataset and the model size.