 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Orthogonal Networks and Long-Memory Tasks
Mar 15, 2017
Although RNNs have been shown to be powerful tools for processing sequential data, finding architectures or optimization strategies that allow them to model very long term dependencies is still an active area of research. In this work, we carefully analyze two synthetic datasets originally outlined in (Hochreiter and Schmidhuber, 1997) which are used to evaluate the ability of RNNs to store information over many time steps. We explicitly construct RNN solutions to these problems, and using these constructions, illuminate both the problems themselves and the way in which RNNs store different types of information in their hidden states. These constructions furthermore explain the success of recent methods that specify unitary initializations or constraints on the transition matrices.
Automatic Rule Extraction from Long Short Term Memory Networks
Feb 24, 2017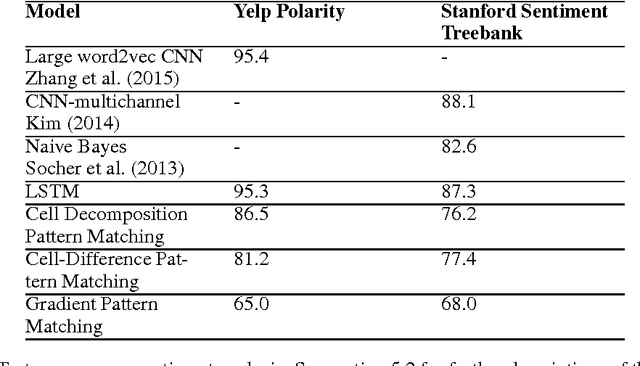
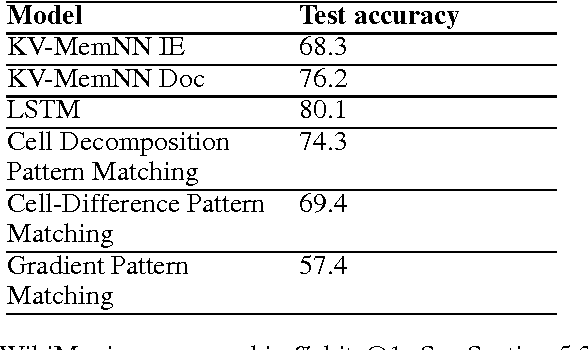
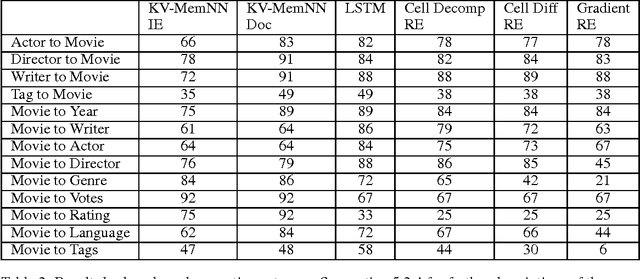

Although deep learning models have proven effective at solving problems in natural language processing, the mechanism by which they come to their conclusions is often unclear. As a result, these models are generally treated as black boxes, yielding no insight of the underlying learned patterns. In this paper we consider Long Short Term Memory networks (LSTMs) and demonstrate a new approach for tracking the importance of a given input to the LSTM for a given output. By identifying consistently important patterns of words, we are able to distill state of the art LSTMs on sentiment analysis and question answering into a set of representative phrases. This representation is then quantitatively validated by using the extracted phrases to construct a simple, rule-based classifier which approximates the output of the LSTM.
Training Language Models Using Target-Propagation
Feb 15, 2017



While Truncated Back-Propagation through Time (BPTT) is the most popular approach to training Recurrent Neural Networks (RNNs), it suffers from being inherently sequential (making parallelization difficult) and from truncating gradient flow between distant time-steps. We investigate whether Target Propagation (TPROP) style approaches can address these shortcomings. Unfortunately, extensive experiments suggest that TPROP generally underperforms BPTT, and we end with an analysis of this phenomenon, and suggestions for future work.
Learning Multiagent Communication with Backpropagation
Oct 31, 2016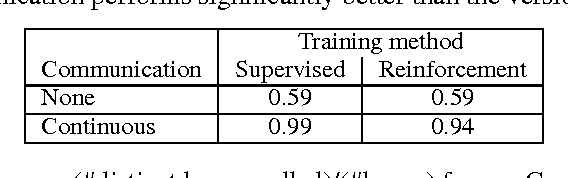
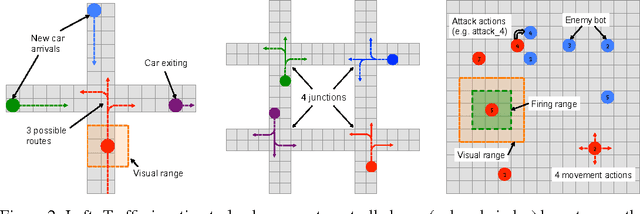

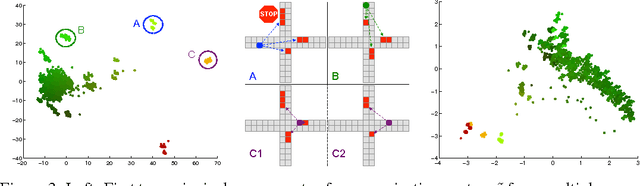
Many tasks in AI require the collaboration of multiple agents. Typically, the communication protocol between agents is manually specified and not altered during training. In this paper we explore a simple neural model, called CommNet, that uses continuous communication for fully cooperative tasks. The model consists of multiple agents and the communication between them is learned alongside their policy. We apply this model to a diverse set of tasks, demonstrating the ability of the agents to learn to communicate amongst themselves, yielding improved performance over non-communicative agents and baselines. In some cases, it is possible to interpret the language devised by the agents, revealing simple but effective strategies for solving the task at hand.
Video (language) modeling: a baseline for generative models of natural videos
May 04, 2016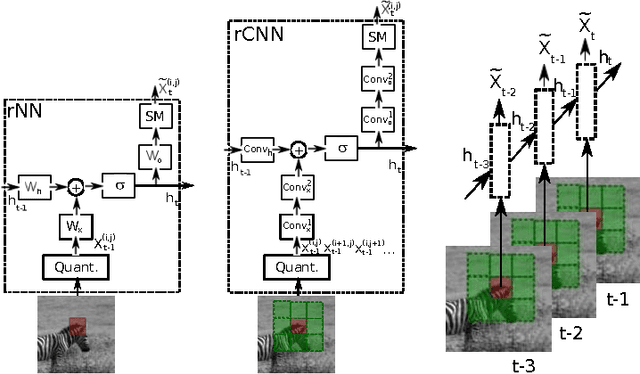



We propose a strong baseline model for unsupervised feature learning using video data. By learning to predict missing frames or extrapolate future frames from an input video sequence, the model discovers both spatial and temporal correlations which are useful to represent complex deformations and motion patterns. The models we propose are largely borrowed from the language modeling literature, and adapted to the vision domain by quantizing the space of image patches into a large dictionary. We demonstrate the approach on both a filling and a generation task. For the first time, we show that, after training on natural videos, such a model can predict non-trivial motions over short video sequences.
Evaluating Prerequisite Qualities for Learning End-to-End Dialog Systems
Apr 19, 2016


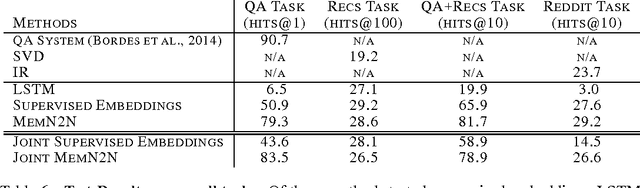
A long-term goal of machine learning is to build intelligent conversational agents. One recent popular approach is to train end-to-end models on a large amount of real dialog transcripts between humans (Sordoni et al., 2015; Vinyals & Le, 2015; Shang et al., 2015). However, this approach leaves many questions unanswered as an understanding of the precise successes and shortcomings of each model is hard to assess. A contrasting recent proposal are the bAbI tasks (Weston et al., 2015b) which are synthetic data that measure the ability of learning machines at various reasoning tasks over toy language. Unfortunately, those tests are very small and hence may encourage methods that do not scale. In this work, we propose a suite of new tasks of a much larger scale that attempt to bridge the gap between the two regimes. Choosing the domain of movies, we provide tasks that test the ability of models to answer factual questions (utilizing OMDB), provide personalization (utilizing MovieLens), carry short conversations about the two, and finally to perform on natural dialogs from Reddit. We provide a dataset covering 75k movie entities and with 3.5M training examples. We present results of various models on these tasks, and evaluate their performance.
Convolutional networks and learning invariant to homogeneous multiplicative scalings
Feb 16, 2016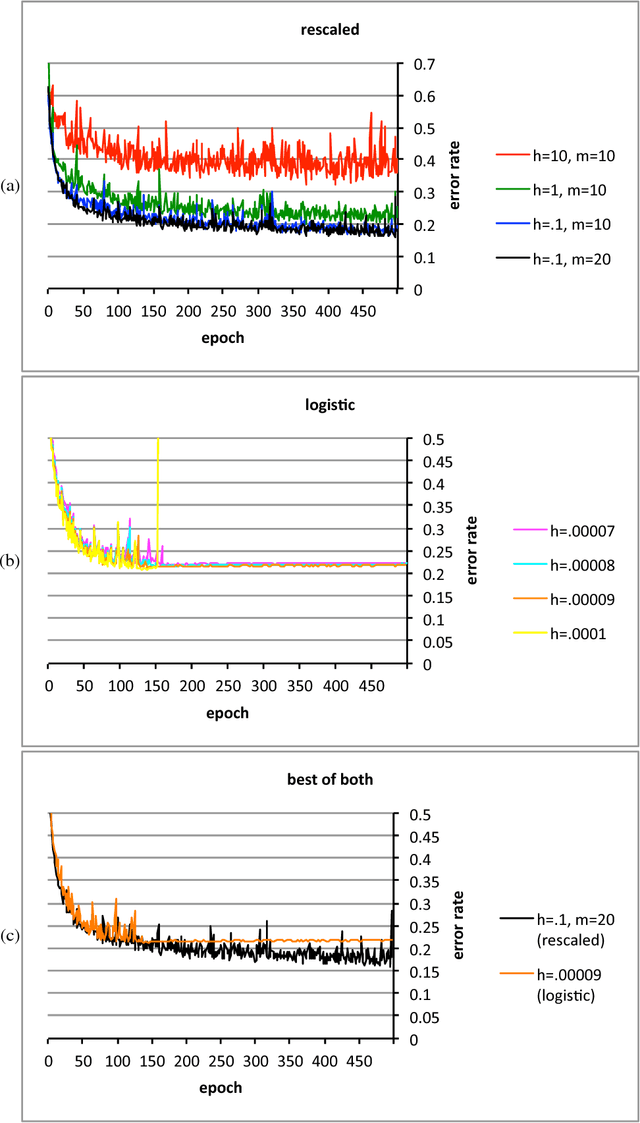
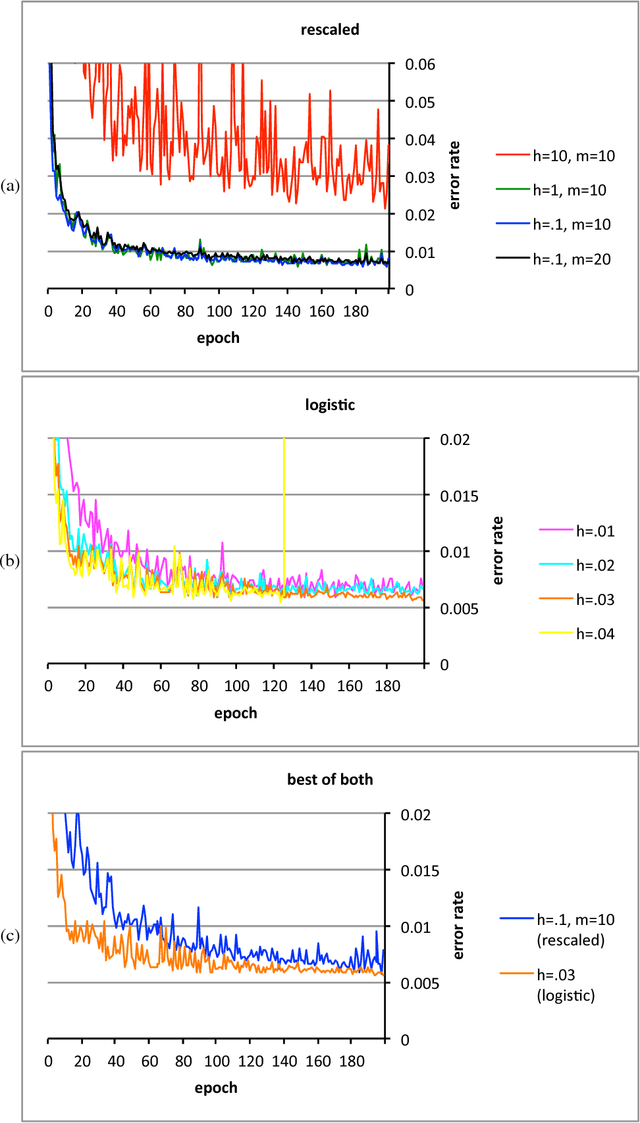
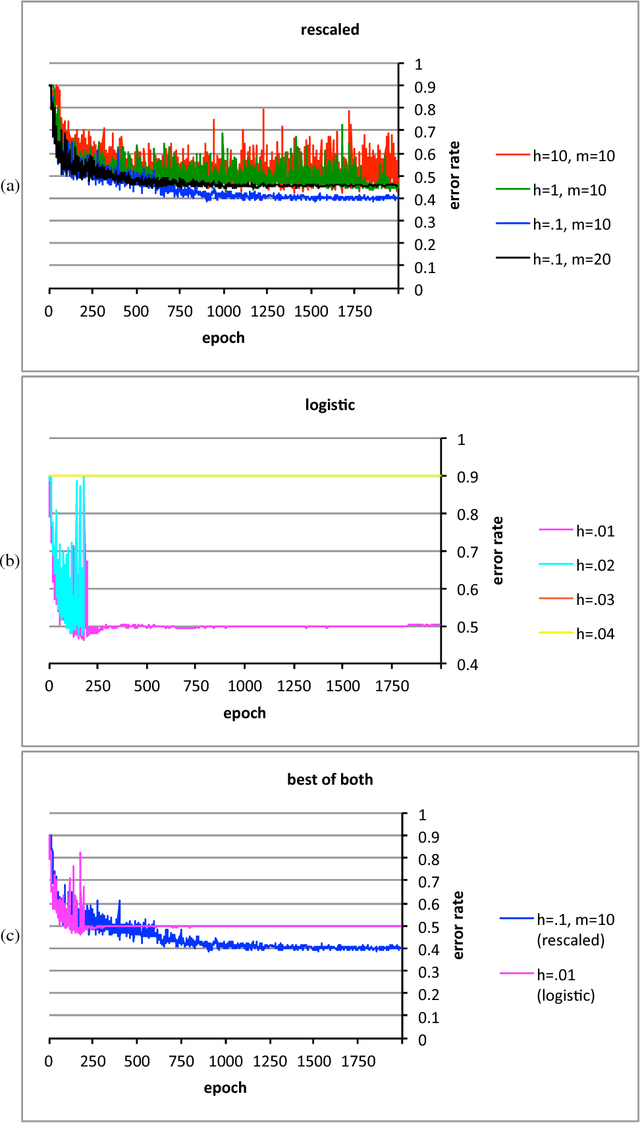
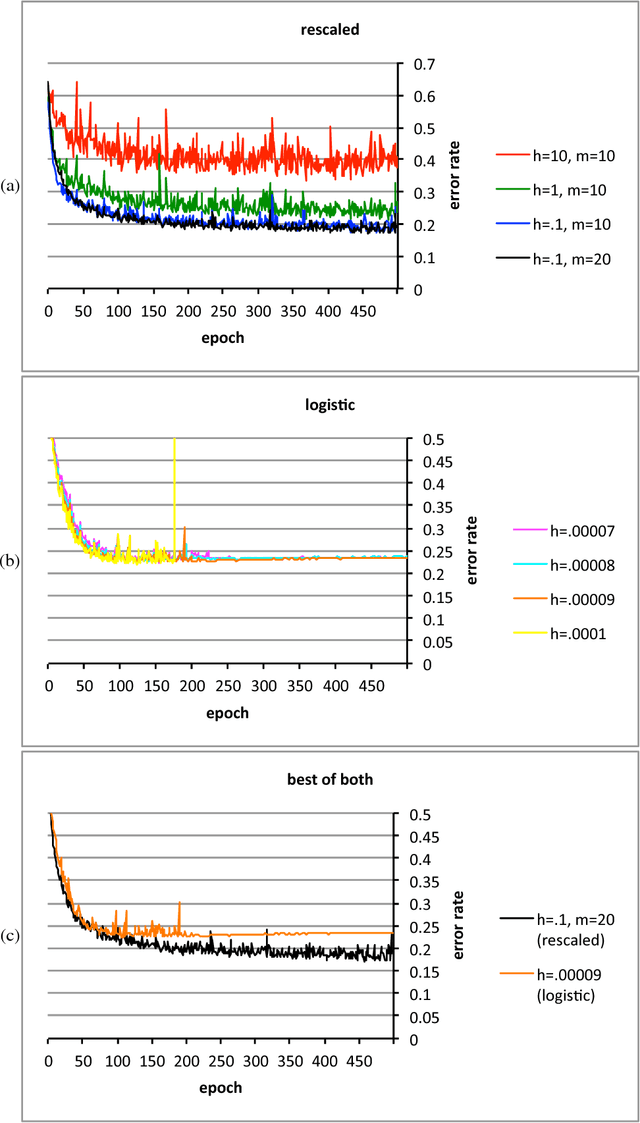
The conventional classification schemes -- notably multinomial logistic regression -- used in conjunction with convolutional networks (convnets) are classical in statistics, designed without consideration for the usual coupling with convnets, stochastic gradient descent, and backpropagation. In the specific application to supervised learning for convnets, a simple scale-invariant classification stage turns out to be more robust than multinomial logistic regression, appears to result in slightly lower errors on several standard test sets, has similar computational costs, and features precise control over the actual rate of learning. "Scale-invariant" means that multiplying the input values by any nonzero scalar leaves the output unchanged.
* 12 pages, 6 figures, 4 tables
MazeBase: A Sandbox for Learning from Games
Jan 07, 2016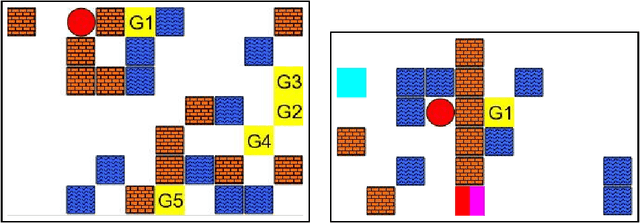
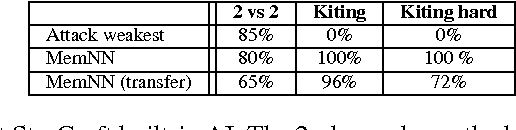
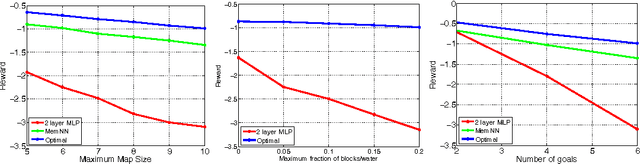
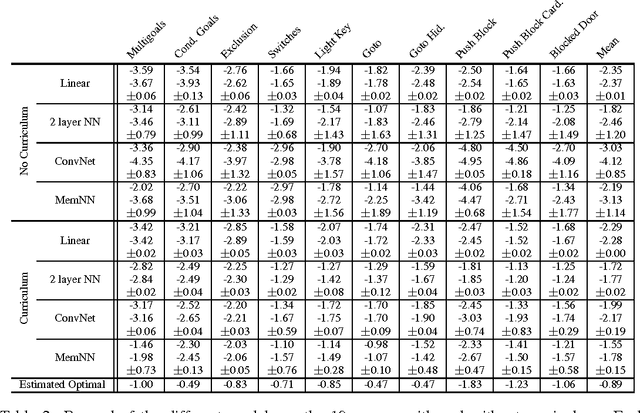
This paper introduces MazeBase: an environment for simple 2D games, designed as a sandbox for machine learning approaches to reasoning and planning. Within it, we create 10 simple games embodying a range of algorithmic tasks (e.g. if-then statements or set negation). A variety of neural models (fully connected, convolutional network, memory network) are deployed via reinforcement learning on these games, with and without a procedurally generated curriculum. Despite the tasks' simplicity, the performance of the models is far from optimal, suggesting directions for future development. We also demonstrate the versatility of MazeBase by using it to emulate small combat scenarios from StarCraft. Models trained on the MazeBase version can be directly applied to StarCraft, where they consistently beat the in-game AI.
Simple Baseline for Visual Question Answering
Dec 15, 2015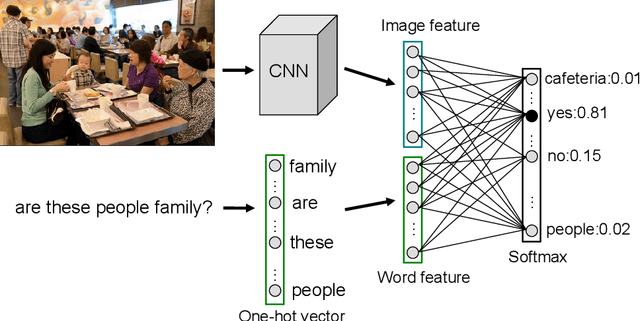
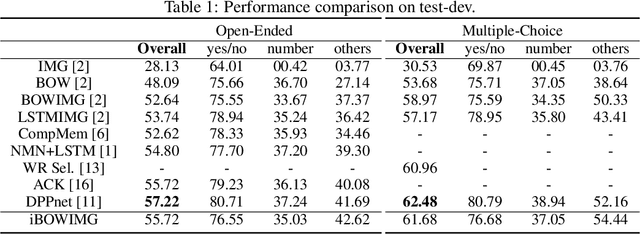
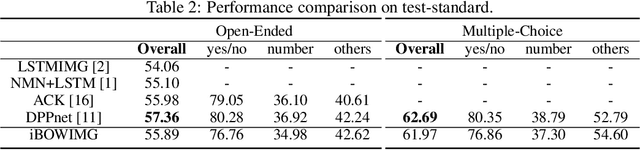

We describe a very simple bag-of-words baseline for visual question answering. This baseline concatenates the word features from the question and CNN features from the image to predict the answer. When evaluated on the challenging VQA dataset [2], it shows comparable performance to many recent approaches using recurrent neural networks. To explore the strength and weakness of the trained model, we also provide an interactive web demo and open-source code. .
A mathematical motivation for complex-valued convolutional networks
Dec 12, 2015A complex-valued convolutional network (convnet) implements the repeated application of the following composition of three operations, recursively applying the composition to an input vector of nonnegative real numbers: (1) convolution with complex-valued vectors followed by (2) taking the absolute value of every entry of the resulting vectors followed by (3) local averaging. For processing real-valued random vectors, complex-valued convnets can be viewed as "data-driven multiscale windowed power spectra," "data-driven multiscale windowed absolute spectra," "data-driven multiwavelet absolute values," or (in their most general configuration) "data-driven nonlinear multiwavelet packets." Indeed, complex-valued convnets can calculate multiscale windowed spectra when the convnet filters are windowed complex-valued exponentials. Standard real-valued convnets, using rectified linear units (ReLUs), sigmoidal (for example, logistic or tanh) nonlinearities, max. pooling, etc., do not obviously exhibit the same exact correspondence with data-driven wavelets (whereas for complex-valued convnets, the correspondence is much more than just a vague analogy). Courtesy of the exact correspondence, the remarkably rich and rigorous body of mathematical analysis for wavelets applies directly to (complex-valued) convnets.
* 11 pages, 3 figures; this is the retitled version submitted to the journal, "Neural Computation"