 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Audio-Visual Segmentation
Nov 04, 2024



Recognizing the sounding objects in scenes is a longstanding objective in embodied AI, with diverse applications in robotics and AR/VR/MR. To that end, Audio-Visual Segmentation (AVS), taking as condition an audio signal to identify the masks of the target sounding objects in an input image with synchronous camera and microphone sensors, has been recently advanced. However, this paradigm is still insufficient for real-world operation, as the mapping from 2D images to 3D scenes is missing. To address this fundamental limitation, we introduce a novel research problem, 3D Audio-Visual Segmentation, extending the existing AVS to the 3D output space. This problem poses more challenges due to variations in camera extrinsics, audio scattering, occlusions, and diverse acoustics across sounding object categories. To facilitate this research, we create the very first simulation based benchmark, 3DAVS-S34-O7, providing photorealistic 3D scene environments with grounded spatial audio under single-instance and multi-instance settings, across 34 scenes and 7 object categories. This is made possible by re-purposing the Habitat simulator to generate comprehensive annotations of sounding object locations and corresponding 3D masks. Subsequently, we propose a new approach, EchoSegnet, characterized by integrating the ready-to-use knowledge from pretrained 2D audio-visual foundation models synergistically with 3D visual scene representation through spatial audio-aware mask alignment and refinement. Extensive experiments demonstrate that EchoSegnet can effectively segment sounding objects in 3D space on our new benchmark, representing a significant advancement in the field of embodied AI. Project page: https://surrey-uplab.github.io/research/3d-audio-visual-segmentation/
Imitating Language via Scalable Inverse Reinforcement Learning
Sep 02, 2024



The majority of language model training builds on imitation learning. It covers pretraining, supervised fine-tuning, and affects the starting conditions for reinforcement learning from human feedback (RLHF). The simplicity and scalability of maximum likelihood estimation (MLE) for next token prediction led to its role as predominant paradigm. However, the broader field of imitation learning can more effectively utilize the sequential structure underlying autoregressive generation. We focus on investigating the inverse reinforcement learning (IRL) perspective to imitation, extracting rewards and directly optimizing sequences instead of individual token likelihoods and evaluate its benefits for fine-tuning large language models. We provide a new angle, reformulating inverse soft-Q-learning as a temporal difference regularized extension of MLE. This creates a principled connection between MLE and IRL and allows trading off added complexity with increased performance and diversity of generations in the supervised fine-tuning (SFT) setting. We find clear advantages for IRL-based imitation, in particular for retaining diversity while maximizing task performance, rendering IRL a strong alternative on fixed SFT datasets even without online data generation. Our analysis of IRL-extracted reward functions further indicates benefits for more robust reward functions via tighter integration of supervised and preference-based LLM post-training.
Improving End-to-End Speech Translation by Imitation-Based Knowledge Distillation with Synthetic Transcripts
Jul 17, 2023



End-to-end automatic speech translation (AST) relies on data that combines audio inputs with text translation outputs. Previous work used existing large parallel corpora of transcriptions and translations in a knowledge distillation (KD) setup to distill a neural machine translation (NMT) into an AST student model. While KD allows using larger pretrained models, the reliance of previous KD approaches on manual audio transcripts in the data pipeline restricts the applicability of this framework to AST. We present an imitation learning approach where a teacher NMT system corrects the errors of an AST student without relying on manual transcripts. We show that the NMT teacher can recover from errors in automatic transcriptions and is able to correct erroneous translations of the AST student, leading to improvements of about 4 BLEU points over the standard AST end-to-end baseline on the English-German CoVoST-2 and MuST-C datasets, respectively. Code and data are publicly available.\footnote{\url{https://github.com/HubReb/imitkd_ast/releases/tag/v1.1}}
* IWSLT 2023, corrected version
Make Every Example Count: On Stability and Utility of Self-Influence for Learning from Noisy NLP Datasets
Feb 27, 2023Increasingly larger datasets have become a standard ingredient to advancing the state of the art in NLP. However, data quality might have already become the bottleneck to unlock further gains. Given the diversity and the sizes of modern datasets, standard data filtering is not straight-forward to apply, because of the multifacetedness of the harmful data and elusiveness of filtering rules that would generalize across multiple tasks. We study the fitness of task-agnostic self-influence scores of training examples for data cleaning, analyze their efficacy in capturing naturally occurring outliers, and investigate to what extent self-influence based data cleaning can improve downstream performance in machine translation, question answering and text classification, building up on recent approaches to self-influence calculation and automated curriculum learning.
Large Raw Emotional Dataset with Aggregation Mechanism
Dec 23, 2022



We present a new data set for speech emotion recognition (SER) tasks called Dusha. The corpus contains approximately 350 hours of data, more than 300 000 audio recordings with Russian speech and their transcripts. Therefore it is the biggest open bi-modal data collection for SER task nowadays. It is annotated using a crowd-sourcing platform and includes two subsets: acted and real-life. Acted subset has a more balanced class distribution than the unbalanced real-life part consisting of audio podcasts. So the first one is suitable for model pre-training, and the second is elaborated for fine-tuning purposes, model approbation, and validation. This paper describes pre-processing routine, annotation, and experiment with a baseline model to demonstrate some actual metrics which could be obtained with the Dusha data set.
Scaling Up Influence Functions
Dec 06, 2021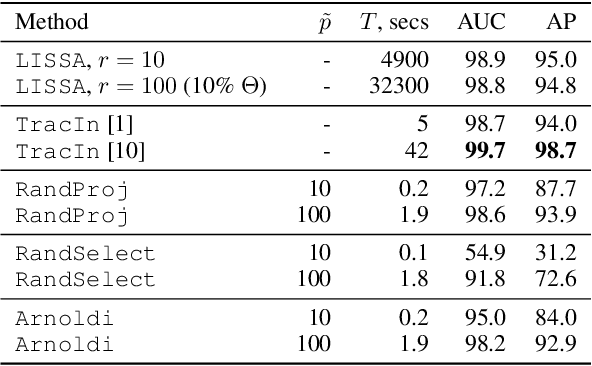
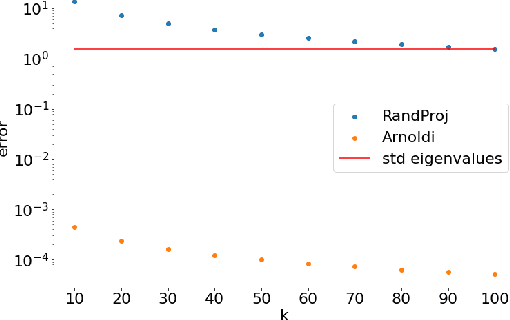
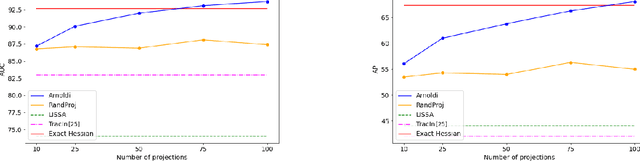
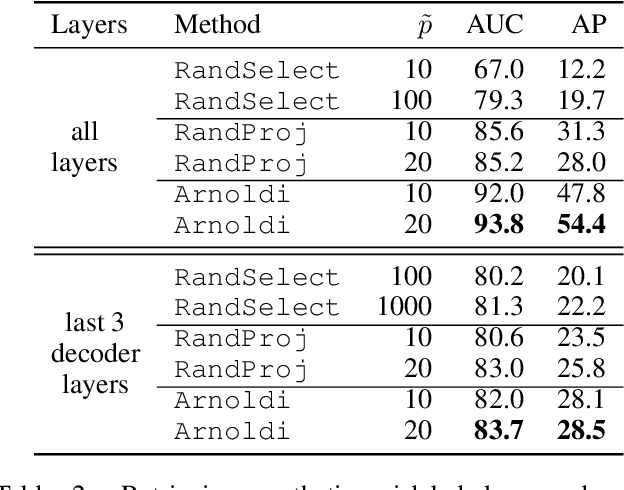
We address efficient calculation of influence functions for tracking predictions back to the training data. We propose and analyze a new approach to speeding up the inverse Hessian calculation based on Arnoldi iteration. With this improvement, we achieve, to the best of our knowledge, the first successful implementation of influence functions that scales to full-size (language and vision) Transformer models with several hundreds of millions of parameters. We evaluate our approach on image classification and sequence-to-sequence tasks with tens to a hundred of millions of training examples. Our code will be available at https://github.com/google-research/jax-influence.
Bandits Don't Follow Rules: Balancing Multi-Facet Machine Translation with Multi-Armed Bandits
Oct 13, 2021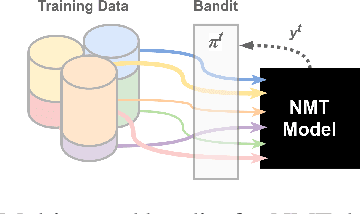
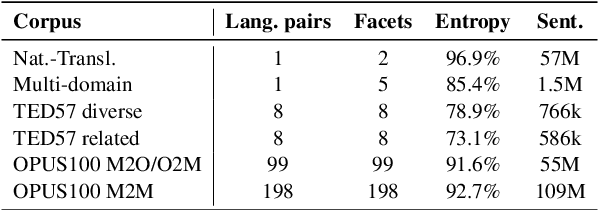
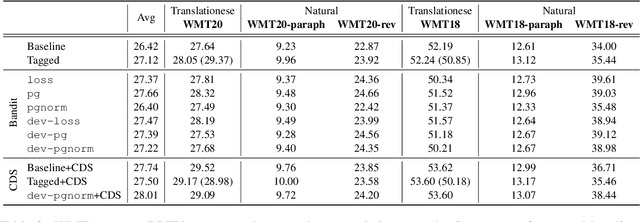
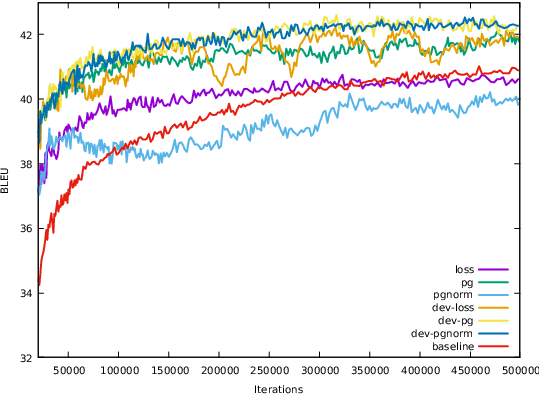
Training data for machine translation (MT) is often sourced from a multitude of large corpora that are multi-faceted in nature, e.g. containing contents from multiple domains or different levels of quality or complexity. Naturally, these facets do not occur with equal frequency, nor are they equally important for the test scenario at hand. In this work, we propose to optimize this balance jointly with MT model parameters to relieve system developers from manual schedule design. A multi-armed bandit is trained to dynamically choose between facets in a way that is most beneficial for the MT system. We evaluate it on three different multi-facet applications: balancing translationese and natural training data, or data from multiple domains or multiple language pairs. We find that bandit learning leads to competitive MT systems across tasks, and our analysis provides insights into its learned strategies and the underlying data sets.
Don't Search for a Search Method -- Simple Heuristics Suffice for Adversarial Text Attacks
Oct 04, 2021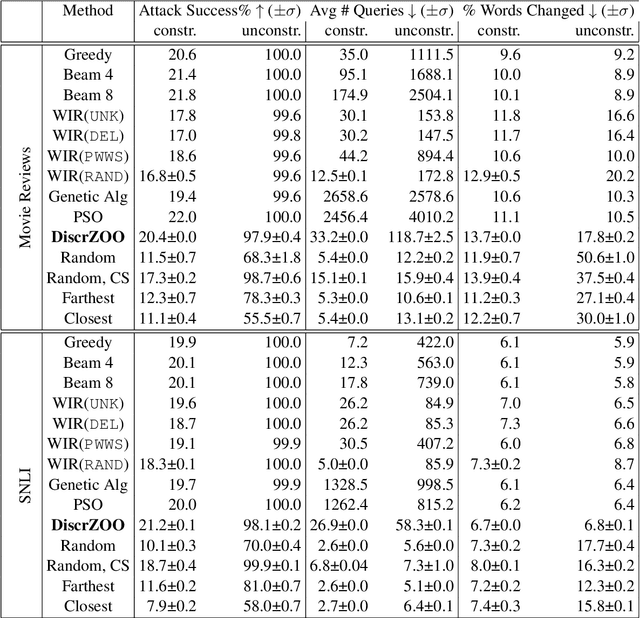
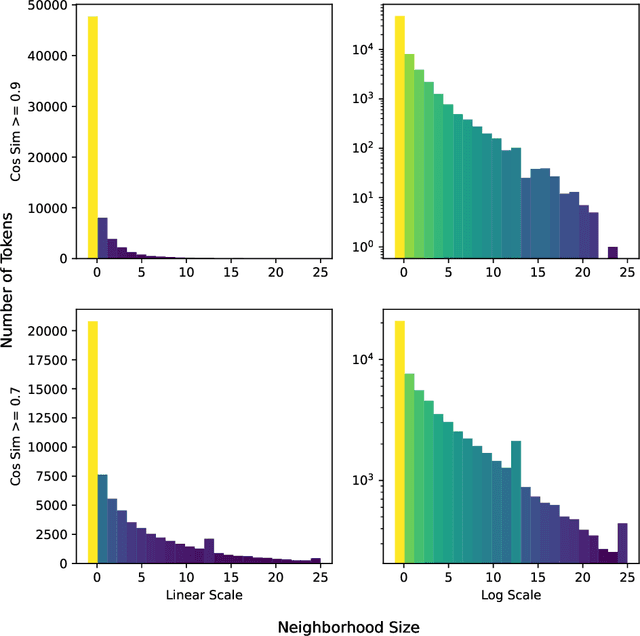
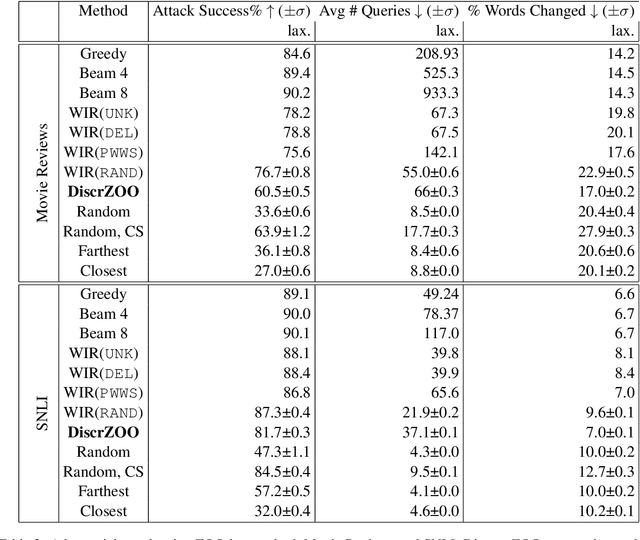
Recently more attention has been given to adversarial attacks on neural networks for natural language processing (NLP). A central research topic has been the investigation of search algorithms and search constraints, accompanied by benchmark algorithms and tasks. We implement an algorithm inspired by zeroth order optimization-based attacks and compare with the benchmark results in the TextAttack framework. Surprisingly, we find that optimization-based methods do not yield any improvement in a constrained setup and slightly benefit from approximate gradient information only in unconstrained setups where search spaces are larger. In contrast, simple heuristics exploiting nearest neighbors without querying the target function yield substantial success rates in constrained setups, and nearly full success rate in unconstrained setups, at an order of magnitude fewer queries. We conclude from these results that current TextAttack benchmark tasks are too easy and constraints are too strict, preventing meaningful research on black-box adversarial text attacks.
Fixing exposure bias with imitation learning needs powerful oracles
Sep 17, 2021
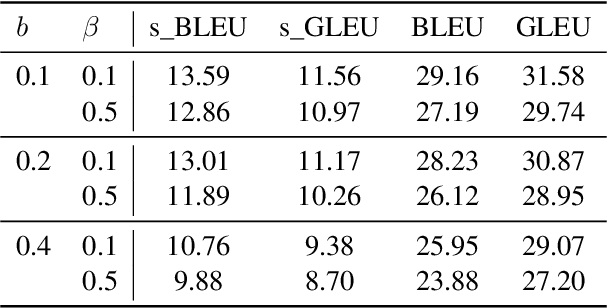
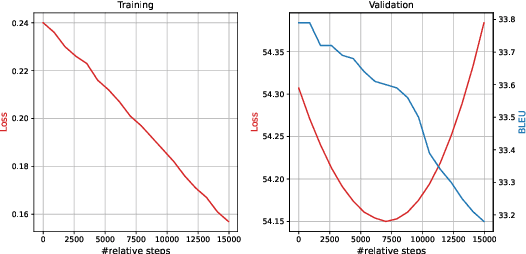
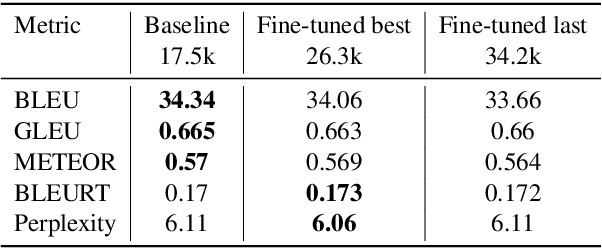
We apply imitation learning (IL) to tackle the NMT exposure bias problem with error-correcting oracles, and evaluate an SMT lattice-based oracle which, despite its excellent performance in an unconstrained oracle translation task, turned out to be too pruned and idiosyncratic to serve as the oracle for IL.
MITI Minimum Information guidelines for highly multiplexed tissue images
Aug 21, 2021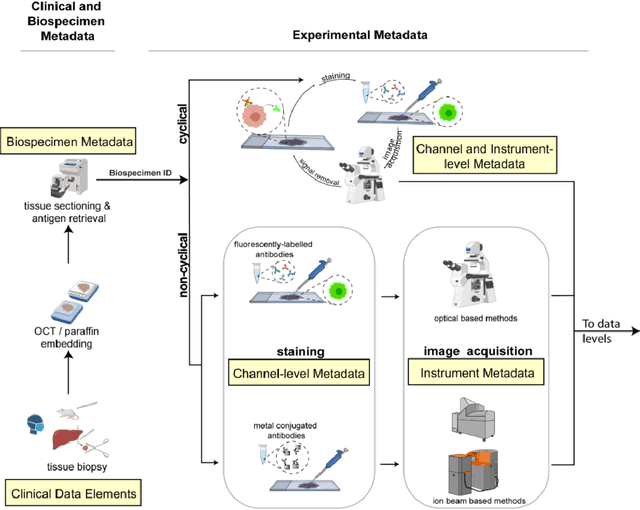
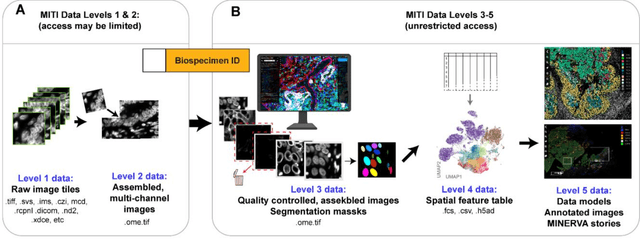
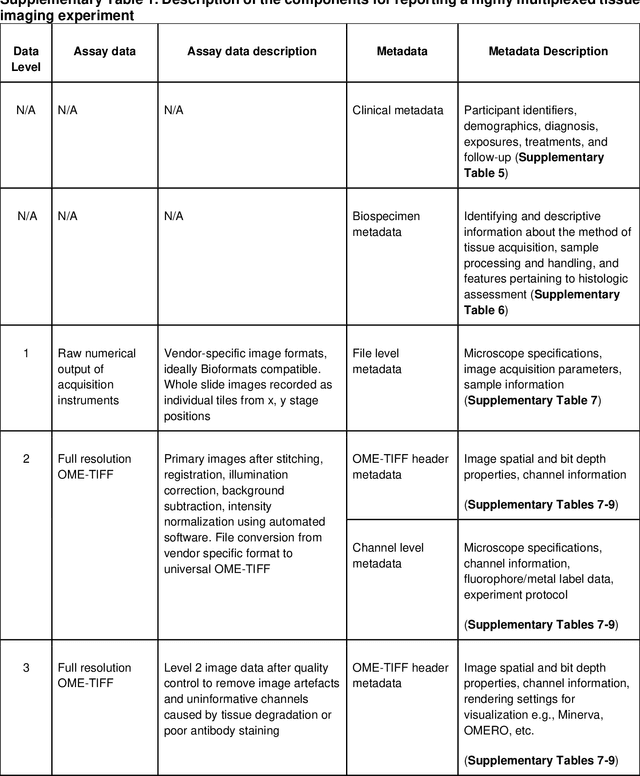
The imminent release of atlases combining highly multiplexed tissue imaging with single cell sequencing and other omics data from human tissues and tumors creates an urgent need for data and metadata standards compliant with emerging and traditional approaches to histology. We describe the development of a Minimum Information about highly multiplexed Tissue Imaging (MITI) standard that draws on best practices from genomics and microscopy of cultured cells and model organisms.