 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Resolution Framework for U-Nets with Applications to Hierarchical VAEs
Jan 19, 2023U-Net architectures are ubiquitous in state-of-the-art deep learning, however their regularisation properties and relationship to wavelets are understudied. In this paper, we formulate a multi-resolution framework which identifies U-Nets as finite-dimensional truncations of models on an infinite-dimensional function space. We provide theoretical results which prove that average pooling corresponds to projection within the space of square-integrable functions and show that U-Nets with average pooling implicitly learn a Haar wavelet basis representation of the data. We then leverage our framework to identify state-of-the-art hierarchical VAEs (HVAEs), which have a U-Net architecture, as a type of two-step forward Euler discretisation of multi-resolution diffusion processes which flow from a point mass, introducing sampling instabilities. We also demonstrate that HVAEs learn a representation of time which allows for improved parameter efficiency through weight-sharing. We use this observation to achieve state-of-the-art HVAE performance with half the number of parameters of existing models, exploiting the properties of our continuous-time formulation.
Causal Falsification of Digital Twins
Jan 19, 2023Digital twins hold substantial promise in many applications, but rigorous procedures for assessing their accuracy are essential for their widespread deployment in safety-critical settings. By formulating this task within the framework of causal inference, we show it is not possible to certify that a twin is "correct" using real-world observational data unless potentially tenuous assumptions are made about the data-generating process. To avoid these assumptions, we propose an assessment strategy that instead aims to find cases where the twin is not correct, and present a general-purpose statistical procedure for doing so that may be used across a wide variety of applications and twin models. Our approach yields reliable and actionable information about the twin under only the assumption of an i.i.d. dataset of real-world observations, and in particular remains sound even in the presence of arbitrary unmeasured confounding. We demonstrate the effectiveness of our methodology via a large-scale case study involving sepsis modelling within the Pulse Physiology Engine, which we assess using the MIMIC-III dataset of ICU patients.
Continuous diffusion for categorical data
Dec 15, 2022



Diffusion models have quickly become the go-to paradigm for generative modelling of perceptual signals (such as images and sound) through iterative refinement. Their success hinges on the fact that the underlying physical phenomena are continuous. For inherently discrete and categorical data such as language, various diffusion-inspired alternatives have been proposed. However, the continuous nature of diffusion models conveys many benefits, and in this work we endeavour to preserve it. We propose CDCD, a framework for modelling categorical data with diffusion models that are continuous both in time and input space. We demonstrate its efficacy on several language modelling tasks.
Particle-Based Score Estimation for State Space Model Learning in Autonomous Driving
Dec 14, 2022Multi-object state estimation is a fundamental problem for robotic applications where a robot must interact with other moving objects. Typically, other objects' relevant state features are not directly observable, and must instead be inferred from observations. Particle filtering can perform such inference given approximate transition and observation models. However, these models are often unknown a priori, yielding a difficult parameter estimation problem since observations jointly carry transition and observation noise. In this work, we consider learning maximum-likelihood parameters using particle methods. Recent methods addressing this problem typically differentiate through time in a particle filter, which requires workarounds to the non-differentiable resampling step, that yield biased or high variance gradient estimates. By contrast, we exploit Fisher's identity to obtain a particle-based approximation of the score function (the gradient of the log likelihood) that yields a low variance estimate while only requiring stepwise differentiation through the transition and observation models. We apply our method to real data collected from autonomous vehicles (AVs) and show that it learns better models than existing techniques and is more stable in training, yielding an effective smoother for tracking the trajectories of vehicles around an AV.
From Denoising Diffusions to Denoising Markov Models
Nov 07, 2022



Denoising diffusions are state-of-the-art generative models which exhibit remarkable empirical performance and come with theoretical guarantees. The core idea of these models is to progressively transform the empirical data distribution into a simple Gaussian distribution by adding noise using a diffusion. We obtain new samples whose distribution is close to the data distribution by simulating a "denoising" diffusion approximating the time reversal of this "noising" diffusion. This denoising diffusion relies on approximations of the logarithmic derivatives of the noised data densities, known as scores, obtained using score matching. Such models can be easily extended to perform approximate posterior simulation in high-dimensional scenarios where one can only sample from the prior and simulate synthetic observations from the likelihood. These methods have been primarily developed for data on $\mathbb{R}^d$ while extensions to more general spaces have been developed on a case-by-case basis. We propose here a general framework which not only unifies and generalizes this approach to a wide class of spaces but also leads to an original extension of score matching. We illustrate the resulting class of denoising Markov models on various applications.
Categorical SDEs with Simplex Diffusion
Oct 26, 2022Diffusion models typically operate in the standard framework of generative modelling by producing continuously-valued datapoints. To this end, they rely on a progressive Gaussian smoothing of the original data distribution, which admits an SDE interpretation involving increments of a standard Brownian motion. However, some applications such as text generation or reinforcement learning might naturally be better served by diffusing categorical-valued data, i.e., lifting the diffusion to a space of probability distributions. To this end, this short theoretical note proposes Simplex Diffusion, a means to directly diffuse datapoints located on an n-dimensional probability simplex. We show how this relates to the Dirichlet distribution on the simplex and how the analogous SDE is realized thanks to a multi-dimensional Cox-Ingersoll-Ross process (abbreviated as CIR), previously used in economics and mathematical finance. Finally, we make remarks as to the numerical implementation of trajectories of the CIR process, and discuss some limitations of our approach.
Maximum Likelihood Learning of Energy-Based Models for Simulation-Based Inference
Oct 26, 2022We introduce two synthetic likelihood methods for Simulation-Based Inference (SBI), to conduct either amortized or targeted inference from experimental observations when a high-fidelity simulator is available. Both methods learn a conditional energy-based model (EBM) of the likelihood using synthetic data generated by the simulator, conditioned on parameters drawn from a proposal distribution. The learned likelihood can then be combined with any prior to obtain a posterior estimate, from which samples can be drawn using MCMC. Our methods uniquely combine a flexible Energy-Based Model and the minimization of a KL loss: this is in contrast to other synthetic likelihood methods, which either rely on normalizing flows, or minimize score-based objectives; choices that come with known pitfalls. Our first method, Amortized Unnormalized Neural Likelihood Estimation (AUNLE), introduces a tilting trick during training that allows to significantly lower the computational cost of inference by enabling the use of efficient MCMC techniques. Our second method, Sequential UNLE (SUNLE), employs a robust doubly intractable approach in order to re-use simulation data and improve posterior accuracy on a specific dataset. We demonstrate the properties of both methods on a range of synthetic datasets, and apply them to a neuroscience model of the pyloric network in the crab Cancer Borealis, matching the performance of other synthetic likelihood methods at a fraction of the simulation budget.
Alpha-divergence Variational Inference Meets Importance Weighted Auto-Encoders: Methodology and Asymptotics
Oct 12, 2022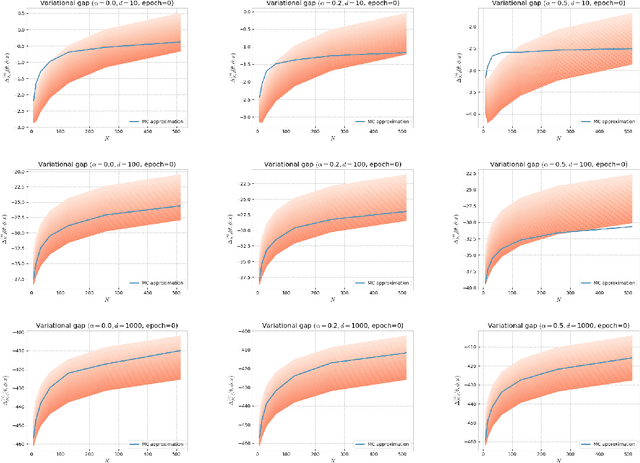
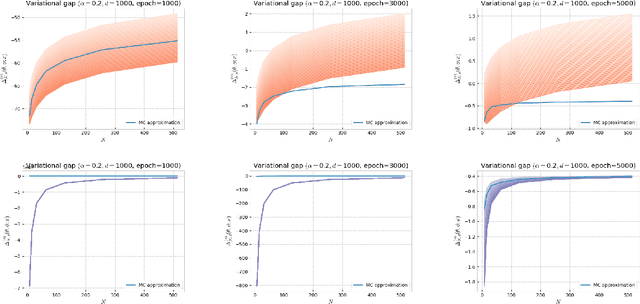
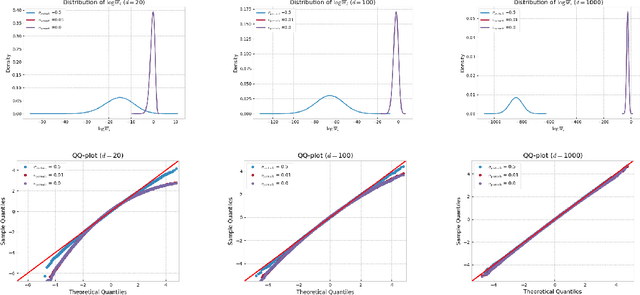
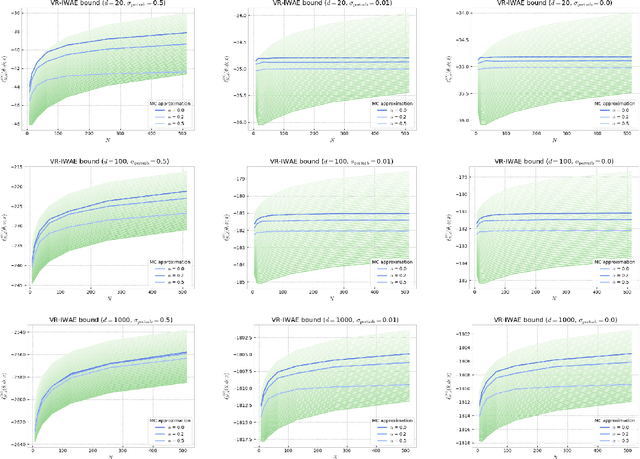
Several algorithms involving the Variational R\'enyi (VR) bound have been proposed to minimize an alpha-divergence between a target posterior distribution and a variational distribution. Despite promising empirical results, those algorithms resort to biased stochastic gradient descent procedures and thus lack theoretical guarantees. In this paper, we formalize and study the VR-IWAE bound, a generalization of the Importance Weighted Auto-Encoder (IWAE) bound. We show that the VR-IWAE bound enjoys several desirable properties and notably leads to the same stochastic gradient descent procedure as the VR bound in the reparameterized case, but this time by relying on unbiased gradient estimators. We then provide two complementary theoretical analyses of the VR-IWAE bound and thus of the standard IWAE bound. Those analyses shed light on the benefits or lack thereof of these bounds. Lastly, we illustrate our theoretical claims over toy and real-data examples.
Spectral Diffusion Processes
Sep 28, 2022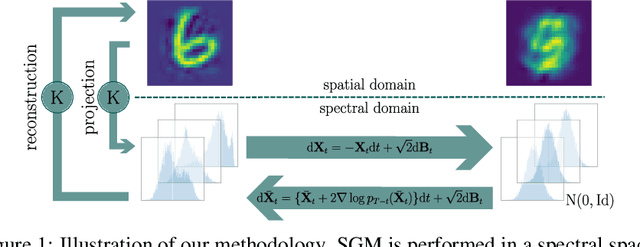

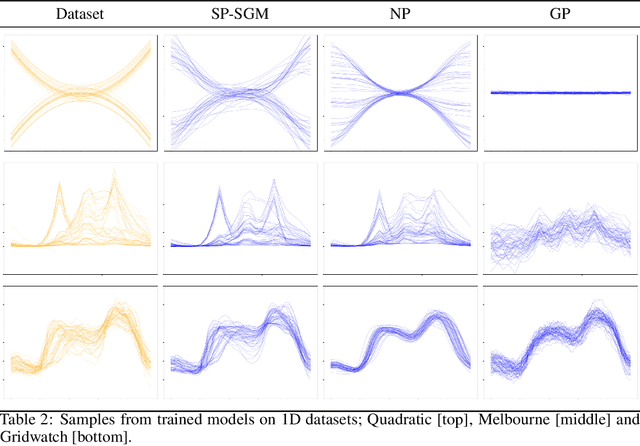

Score-based generative modelling (SGM) has proven to be a very effective method for modelling densities on finite-dimensional spaces. In this work we propose to extend this methodology to learn generative models over functional spaces. To do so, we represent functional data in spectral space to dissociate the stochastic part of the processes from their space-time part. Using dimensionality reduction techniques we then sample from their stochastic component using finite dimensional SGM. We demonstrate our method's effectiveness for modelling various multimodal datasets.
A PAC-Bayes bound for deterministic classifiers
Sep 06, 2022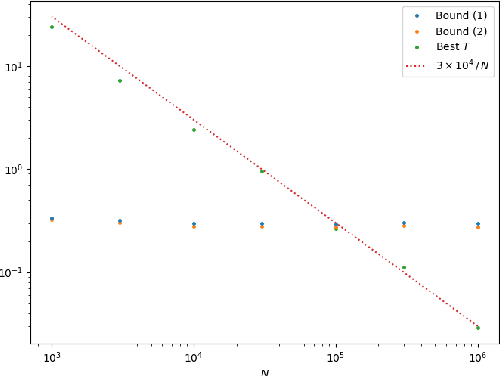
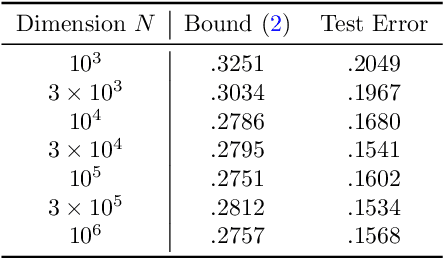
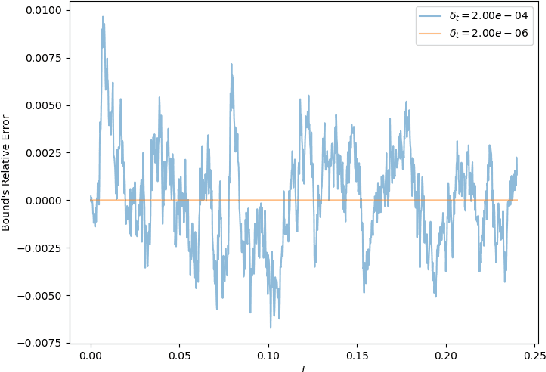
We establish a disintegrated PAC-Bayesian bound, for classifiers that are trained via continuous-time (non-stochastic) gradient descent. Contrarily to what is standard in the PAC-Bayesian setting, our result applies to a training algorithm that is deterministic, conditioned on a random initialisation, without requiring any $\textit{de-randomisation}$ step. We provide a broad discussion of the main features of the bound that we propose, and we study analytically and empirically its behaviour on linear models, finding promising results.