 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Isolated Tasks: A Framework for Evaluating Coding Agents on Sequential Software Evolution
Apr 03, 2026Existing datasets for coding agents evaluate performance on isolated, single pull request (PR) tasks in a stateless manner, failing to capture the reality of real-world software development where code changes accumulate, technical debt accrues, and test suites grow over time. To bridge this gap, we introduce an automated coding task generation framework, which helps generate our dataset SWE-STEPS, that evaluates coding agents on long-horizon tasks through two realistic settings mirroring actual developer workflows: Conversational coding with iterative requests, and single-shot Project Requirement document (PRD)-based coding. Unlike existing datasets that evaluate agents on disjointed Pull Requests (PRs), our framework assesses performance across chains of dependent PRs, enabling evaluation of sequential execution, regression verification, and long-term repository health. We discover that widely used isolated PR evaluations yield inflated success rates, w.r.t. our settings - overshooting performance by as much as 20 percentage points - because they ignore the ``spillover'' effects of previous inefficient or buggy code. Furthermore, our analysis reveals that even when agents successfully resolve issues, they degrade repository health by generating code with higher cognitive complexity and technical debt compared to human developers, underscoring the necessity for multidimensional evaluation.
EnterpriseLab: A Full-Stack Platform for developing and deploying agents in Enterprises
Mar 23, 2026Deploying AI agents in enterprise environments requires balancing capability with data sovereignty and cost constraints. While small language models offer privacy-preserving alternatives to frontier models, their specialization is hindered by fragmented development pipelines that separate tool integration, data generation, and training. We introduce EnterpriseLab, a full-stack platform that unifies these stages into a closed-loop framework. EnterpriseLab provides (1) a modular environment exposing enterprise applications via Model Context Protocol, enabling seamless integration of proprietary and open-source tools; (2) automated trajectory synthesis that programmatically generates training data from environment schemas; and (3) integrated training pipelines with continuous evaluation. We validate the platform through EnterpriseArena, an instantiation with 15 applications and 140+ tools across IT, HR, sales, and engineering domains. Our results demonstrate that 8B-parameter models trained within EnterpriseLab match GPT-4o's performance on complex enterprise workflows while reducing inference costs by 8-10x, and remain robust across diverse enterprise benchmarks, including EnterpriseBench (+10%) and CRMArena (+10%). EnterpriseLab provides enterprises a practical path to deploying capable, privacy-preserving agents without compromising operational capability.
Can LLMs Help You at Work? A Sandbox for Evaluating LLM Agents in Enterprise Environments
Oct 31, 2025Enterprise systems are crucial for enhancing productivity and decision-making among employees and customers. Integrating LLM based systems into enterprise systems enables intelligent automation, personalized experiences, and efficient information retrieval, driving operational efficiency and strategic growth. However, developing and evaluating such systems is challenging due to the inherent complexity of enterprise environments, where data is fragmented across multiple sources and governed by sophisticated access controls. We present EnterpriseBench, a comprehensive benchmark that simulates enterprise settings, featuring 500 diverse tasks across software engineering, HR, finance, and administrative domains. Our benchmark uniquely captures key enterprise characteristics including data source fragmentation, access control hierarchies, and cross-functional workflows. Additionally, we provide a novel data generation pipeline that creates internally consistent enterprise tasks from organizational metadata. Experiments with state-of-the-art LLM agents demonstrate that even the most capable models achieve only 41.8% task completion, highlighting significant opportunities for improvement in enterprise-focused AI systems.
Adaptive LLM Routing under Budget Constraints
Aug 28, 2025Large Language Models (LLMs) have revolutionized natural language processing, but their varying capabilities and costs pose challenges in practical applications. LLM routing addresses this by dynamically selecting the most suitable LLM for each query/task. Previous approaches treat this as a supervised learning problem, assuming complete knowledge of optimal query-LLM pairings. However, real-world scenarios lack such comprehensive mappings and face evolving user queries. We thus propose to study LLM routing as a contextual bandit problem, enabling adaptive decision-making using bandit feedback without requiring exhaustive inference across all LLMs for all queries (in contrast to supervised routing). To address this problem, we develop a shared embedding space for queries and LLMs, where query and LLM embeddings are aligned to reflect their affinity. This space is initially learned from offline human preference data and refined through online bandit feedback. We instantiate this idea through Preference-prior Informed Linucb fOr adaptive rouTing (PILOT), a novel extension of LinUCB. To handle diverse user budgets for model routing, we introduce an online cost policy modeled as a multi-choice knapsack problem, ensuring resource-efficient routing.
Finding Needles in Images: Can Multimodal LLMs Locate Fine Details?
Aug 07, 2025
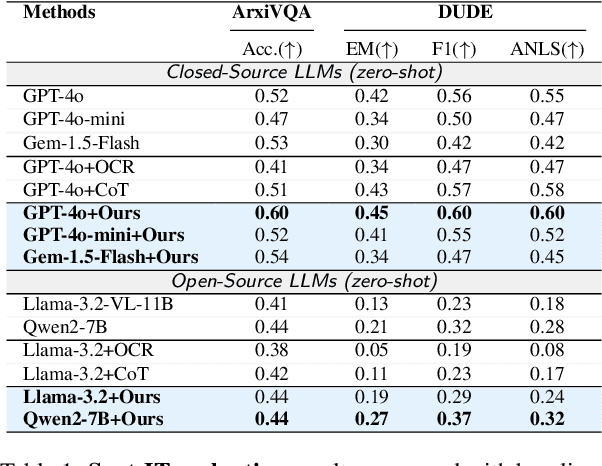

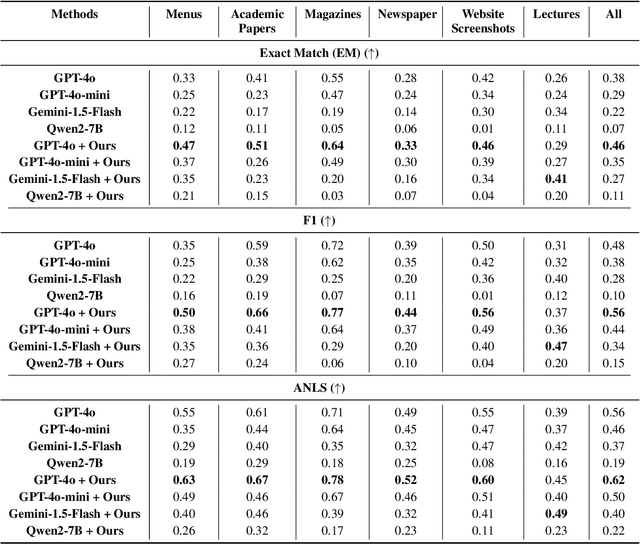
While Multi-modal Large Language Models (MLLMs) have shown impressive capabilities in document understanding tasks, their ability to locate and reason about fine-grained details within complex documents remains understudied. Consider searching a restaurant menu for a specific nutritional detail or identifying a disclaimer in a lengthy newspaper article tasks that demand careful attention to small but significant details within a broader narrative, akin to Finding Needles in Images (NiM). To address this gap, we introduce NiM, a carefully curated benchmark spanning diverse real-world documents including newspapers, menus, and lecture images, specifically designed to evaluate MLLMs' capability in these intricate tasks. Building on this, we further propose Spot-IT, a simple yet effective approach that enhances MLLMs capability through intelligent patch selection and Gaussian attention, motivated from how humans zoom and focus when searching documents. Our extensive experiments reveal both the capabilities and limitations of current MLLMs in handling fine-grained document understanding tasks, while demonstrating the effectiveness of our approach. Spot-IT achieves significant improvements over baseline methods, particularly in scenarios requiring precise detail extraction from complex layouts.
* Accepted at ACL 2025 in the main track
Hybrid Graphs for Table-and-Text based Question Answering using LLMs
Jan 29, 2025



Answering questions that require reasoning and aggregation across both structured (tables) and unstructured (raw text) data sources presents significant challenges. Current methods rely on fine-tuning and high-quality, human-curated data, which is difficult to obtain. Recent advances in Large Language Models (LLMs) have shown promising results for multi-hop question answering (QA) over single-source text data in a zero-shot setting, yet exploration into multi-source Table-Text QA remains limited. In this paper, we present a novel Hybrid Graph-based approach for Table-Text QA that leverages LLMs without fine-tuning. Our method constructs a unified Hybrid Graph from textual and tabular data, pruning information based on the input question to provide the LLM with relevant context concisely. We evaluate our approach on the challenging Hybrid-QA and OTT-QA datasets using state-of-the-art LLMs, including GPT-3.5, GPT-4, and LLaMA-3. Our method achieves the best zero-shot performance on both datasets, improving Exact Match scores by up to 10% on Hybrid-QA and 5.4% on OTT-QA. Moreover, our approach reduces token usage by up to 53% compared to the original context.
Towards a Training Free Approach for 3D Scene Editing
Dec 17, 2024



Text driven diffusion models have shown remarkable capabilities in editing images. However, when editing 3D scenes, existing works mostly rely on training a NeRF for 3D editing. Recent NeRF editing methods leverages edit operations by deploying 2D diffusion models and project these edits into 3D space. They require strong positional priors alongside text prompt to identify the edit location. These methods are operational on small 3D scenes and are more generalized to particular scene. They require training for each specific edit and cannot be exploited in real-time edits. To address these limitations, we propose a novel method, FreeEdit, to make edits in training free manner using mesh representations as a substitute for NeRF. Training-free methods are now a possibility because of the advances in foundation model's space. We leverage these models to bring a training-free alternative and introduce solutions for insertion, replacement and deletion. We consider insertion, replacement and deletion as basic blocks for performing intricate edits with certain combinations of these operations. Given a text prompt and a 3D scene, our model is capable of identifying what object should be inserted/replaced or deleted and location where edit should be performed. We also introduce a novel algorithm as part of FreeEdit to find the optimal location on grounding object for placement. We evaluate our model by comparing it with baseline models on a wide range of scenes using quantitative and qualitative metrics and showcase the merits of our method with respect to others.
Semantic Graph Consistency: Going Beyond Patches for Regularizing Self-Supervised Vision Transformers
Jun 18, 2024



Self-supervised learning (SSL) with vision transformers (ViTs) has proven effective for representation learning as demonstrated by the impressive performance on various downstream tasks. Despite these successes, existing ViT-based SSL architectures do not fully exploit the ViT backbone, particularly the patch tokens of the ViT. In this paper, we introduce a novel Semantic Graph Consistency (SGC) module to regularize ViT-based SSL methods and leverage patch tokens effectively. We reconceptualize images as graphs, with image patches as nodes and infuse relational inductive biases by explicit message passing using Graph Neural Networks into the SSL framework. Our SGC loss acts as a regularizer, leveraging the underexploited patch tokens of ViTs to construct a graph and enforcing consistency between graph features across multiple views of an image. Extensive experiments on various datasets including ImageNet, RESISC and Food-101 show that our approach significantly improves the quality of learned representations, resulting in a 5-10\% increase in performance when limited labeled data is used for linear evaluation. These experiments coupled with a comprehensive set of ablations demonstrate the promise of our approach in various settings.
HOLMES: Hyper-Relational Knowledge Graphs for Multi-hop Question Answering using LLMs
Jun 10, 2024



Given unstructured text, Large Language Models (LLMs) are adept at answering simple (single-hop) questions. However, as the complexity of the questions increase, the performance of LLMs degrade. We believe this is due to the overhead associated with understanding the complex question followed by filtering and aggregating unstructured information in the raw text. Recent methods try to reduce this burden by integrating structured knowledge triples into the raw text, aiming to provide a structured overview that simplifies information processing. However, this simplistic approach is query-agnostic and the extracted facts are ambiguous as they lack context. To address these drawbacks and to enable LLMs to answer complex (multi-hop) questions with ease, we propose to use a knowledge graph (KG) that is context-aware and is distilled to contain query-relevant information. The use of our compressed distilled KG as input to the LLM results in our method utilizing up to $67\%$ fewer tokens to represent the query relevant information present in the supporting documents, compared to the state-of-the-art (SoTA) method. Our experiments show consistent improvements over the SoTA across several metrics (EM, F1, BERTScore, and Human Eval) on two popular benchmark datasets (HotpotQA and MuSiQue).
Synergizing Contrastive Learning and Optimal Transport for 3D Point Cloud Domain Adaptation
Aug 27, 2023



Recently, the fundamental problem of unsupervised domain adaptation (UDA) on 3D point clouds has been motivated by a wide variety of applications in robotics, virtual reality, and scene understanding, to name a few. The point cloud data acquisition procedures manifest themselves as significant domain discrepancies and geometric variations among both similar and dissimilar classes. The standard domain adaptation methods developed for images do not directly translate to point cloud data because of their complex geometric nature. To address this challenge, we leverage the idea of multimodality and alignment between distributions. We propose a new UDA architecture for point cloud classification that benefits from multimodal contrastive learning to get better class separation in both domains individually. Further, the use of optimal transport (OT) aims at learning source and target data distributions jointly to reduce the cross-domain shift and provide a better alignment. We conduct a comprehensive empirical study on PointDA-10 and GraspNetPC-10 and show that our method achieves state-of-the-art performance on GraspNetPC-10 (with approx 4-12% margin) and best average performance on PointDA-10. Our ablation studies and decision boundary analysis also validate the significance of our contrastive learning module and OT alignment.