 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Embodied AI Reliable: A Community Agenda from Testing to Formal Verification
Jun 02, 2026Embodied AI systems are increasingly deployed in open-world environments, yet ensuring their reliability remains a fundamental challenge. Drawing on discussions from the AAAI'26 Bridge Program on "Making Embodied AI Reliable with Testing and Formal Verification", this article argues that reliability in embodied AI is inherently a lifecycle assurance problem arising from uncertainty, human interaction, and emergent behaviors across tightly coupled system components. We identify three complementary directions toward reliable embodied AI: (1) trustworthy scenario-based testing supported by validated specifications and meaningful coverage metrics, (2) compositional verification enabled by structured symbolic representations of system behavior and environmental context, and (3) runtime assurance mechanisms capable of adapting to uncertainty and distribution shifts during deployment. Rather than treating these approaches independently, we advocate integrated assurance workflows that connect testing, verification, and runtime adaptation through shared neuro-symbolic representations and continuous feedback across the system lifecycle. Such integration provides a foundation for building trustworthy embodied AI systems that can operate safely and reliably in complex real-world environments.
Adaptive Problem Generation via Symbolic Representations
Feb 22, 2026We present a method for generating training data for reinforcement learning with verifiable rewards to improve small open-weights language models on mathematical tasks. Existing data generation approaches rely on open-loop pipelines and fixed modifications that do not adapt to the model's capabilities. Furthermore, they typically operate directly on word problems, limiting control over problem structure. To address this, we perform modifications in a symbolic problem space, representing each problem as a set of symbolic variables and constraints (e.g., via algebraic frameworks such as SymPy or SMT formulations). This representation enables precise control over problem structure, automatic generation of ground-truth solutions, and decouples mathematical reasoning from linguistic realization. We also show that this results in more diverse generations. To adapt the problem difficulty to the model, we introduce a closed-loop framework that learns modification strategies through prompt optimization in symbolic space. Experimental results demonstrate that both adaptive problem generation and symbolic representation modifications contribute to improving the model's math solving ability.
Towards Adaptive Environment Generation for Training Embodied Agents
Feb 06, 2026Embodied agents struggle to generalize to new environments, even when those environments share similar underlying structures to their training settings. Most current approaches to generating these training environments follow an open-loop paradigm, without considering the agent's current performance. While procedural generation methods can produce diverse scenes, diversity without feedback from the agent is inefficient. The generated environments may be trivially easy, providing limited learning signal. To address this, we present a proof-of-concept for closed-loop environment generation that adapts difficulty to the agent's current capabilities. Our system employs a controllable environment representation, extracts fine-grained performance feedback beyond binary success or failure, and implements a closed-loop adaptation mechanism that translates this feedback into environment modifications. This feedback-driven approach generates training environments that more challenging in the ways the agent needs to improve, enabling more efficient learning and better generalization to novel settings.
Inference-Time Gaze Refinement for Micro-Expression Recognition: Enhancing Event-Based Eye Tracking with Motion-Aware Post-Processing
Jun 14, 2025Event-based eye tracking holds significant promise for fine-grained cognitive state inference, offering high temporal resolution and robustness to motion artifacts, critical features for decoding subtle mental states such as attention, confusion, or fatigue. In this work, we introduce a model-agnostic, inference-time refinement framework designed to enhance the output of existing event-based gaze estimation models without modifying their architecture or requiring retraining. Our method comprises two key post-processing modules: (i) Motion-Aware Median Filtering, which suppresses blink-induced spikes while preserving natural gaze dynamics, and (ii) Optical Flow-Based Local Refinement, which aligns gaze predictions with cumulative event motion to reduce spatial jitter and temporal discontinuities. To complement traditional spatial accuracy metrics, we propose a novel Jitter Metric that captures the temporal smoothness of predicted gaze trajectories based on velocity regularity and local signal complexity. Together, these contributions significantly improve the consistency of event-based gaze signals, making them better suited for downstream tasks such as micro-expression analysis and mind-state decoding. Our results demonstrate consistent improvements across multiple baseline models on controlled datasets, laying the groundwork for future integration with multimodal affect recognition systems in real-world environments.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025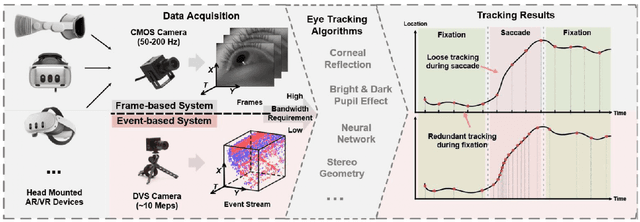
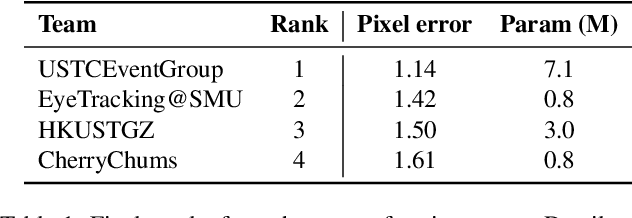
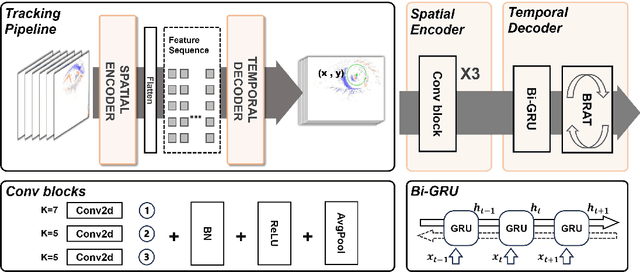

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Ges3ViG: Incorporating Pointing Gestures into Language-Based 3D Visual Grounding for Embodied Reference Understanding
Apr 13, 20253-Dimensional Embodied Reference Understanding (3D-ERU) combines a language description and an accompanying pointing gesture to identify the most relevant target object in a 3D scene. Although prior work has explored pure language-based 3D grounding, there has been limited exploration of 3D-ERU, which also incorporates human pointing gestures. To address this gap, we introduce a data augmentation framework-Imputer, and use it to curate a new benchmark dataset-ImputeRefer for 3D-ERU, by incorporating human pointing gestures into existing 3D scene datasets that only contain language instructions. We also propose Ges3ViG, a novel model for 3D-ERU that achieves ~30% improvement in accuracy as compared to other 3D-ERU models and ~9% compared to other purely language-based 3D grounding models. Our code and dataset are available at https://github.com/AtharvMane/Ges3ViG.
EyeTrAES: Fine-grained, Low-Latency Eye Tracking via Adaptive Event Slicing
Sep 27, 2024



Eye-tracking technology has gained significant attention in recent years due to its wide range of applications in human-computer interaction, virtual and augmented reality, and wearable health. Traditional RGB camera-based eye-tracking systems often struggle with poor temporal resolution and computational constraints, limiting their effectiveness in capturing rapid eye movements. To address these limitations, we propose EyeTrAES, a novel approach using neuromorphic event cameras for high-fidelity tracking of natural pupillary movement that shows significant kinematic variance. One of EyeTrAES's highlights is the use of a novel adaptive windowing/slicing algorithm that ensures just the right amount of descriptive asynchronous event data accumulation within an event frame, across a wide range of eye movement patterns. EyeTrAES then applies lightweight image processing functions over accumulated event frames from just a single eye to perform pupil segmentation and tracking. We show that these methods boost pupil tracking fidelity by 6+%, achieving IoU~=92%, while incurring at least 3x lower latency than competing pure event-based eye tracking alternatives [38]. We additionally demonstrate that the microscopic pupillary motion captured by EyeTrAES exhibits distinctive variations across individuals and can thus serve as a biometric fingerprint. For robust user authentication, we train a lightweight per-user Random Forest classifier using a novel feature vector of short-term pupillary kinematics, comprising a sliding window of pupil (location, velocity, acceleration) triples. Experimental studies with two different datasets demonstrate that the EyeTrAES-based authentication technique can simultaneously achieve high authentication accuracy (~=0.82) and low processing latency (~=12ms), and significantly outperform multiple state-of-the-art competitive baselines.
Demo: RhythmEdge: Enabling Contactless Heart Rate Estimation on the Edge
Aug 13, 2022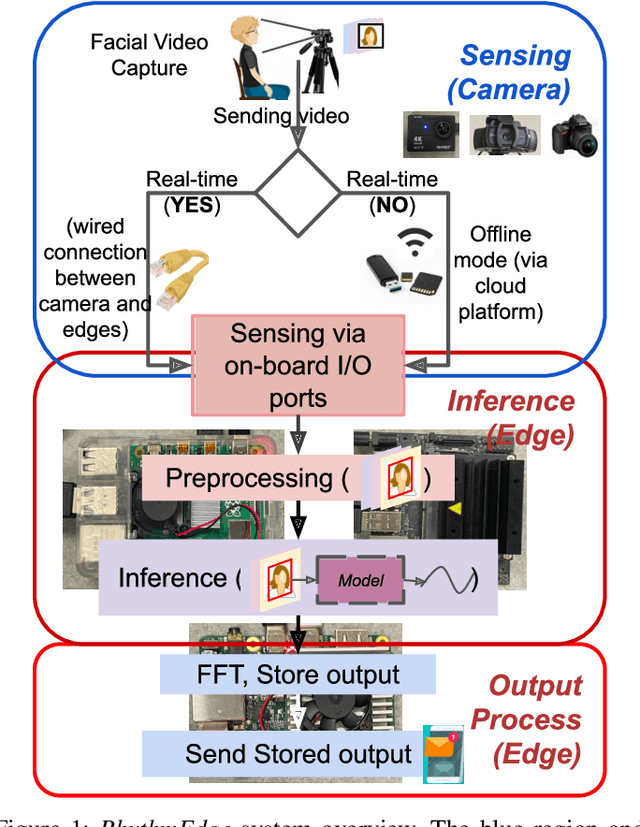

In this demo paper, we design and prototype RhythmEdge, a low-cost, deep-learning-based contact-less system for regular HR monitoring applications. RhythmEdge benefits over existing approaches by facilitating contact-less nature, real-time/offline operation, inexpensive and available sensing components, and computing devices. Our RhythmEdge system is portable and easily deployable for reliable HR estimation in moderately controlled indoor or outdoor environments. RhythmEdge measures HR via detecting changes in blood volume from facial videos (Remote Photoplethysmography; rPPG) and provides instant assessment using off-the-shelf commercially available resource-constrained edge platforms and video cameras. We demonstrate the scalability, flexibility, and compatibility of the RhythmEdge by deploying it on three resource-constrained platforms of differing architectures (NVIDIA Jetson Nano, Google Coral Development Board, Raspberry Pi) and three heterogeneous cameras of differing sensitivity, resolution, properties (web camera, action camera, and DSLR). RhythmEdge further stores longitudinal cardiovascular information and provides instant notification to the users. We thoroughly test the prototype stability, latency, and feasibility for three edge computing platforms by profiling their runtime, memory, and power usage.
DeepLight: Robust & Unobtrusive Real-time Screen-Camera Communication for Real-World Displays
May 11, 2021
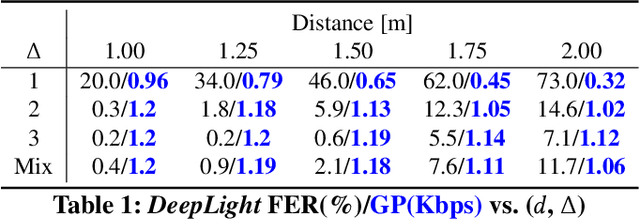

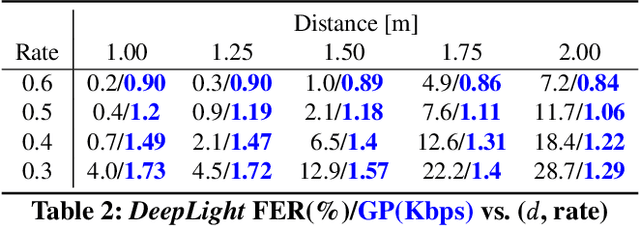
The paper introduces a novel, holistic approach for robust Screen-Camera Communication (SCC), where video content on a screen is visually encoded in a human-imperceptible fashion and decoded by a camera capturing images of such screen content. We first show that state-of-the-art SCC techniques have two key limitations for in-the-wild deployment: (a) the decoding accuracy drops rapidly under even modest screen extraction errors from the captured images, and (b) they generate perceptible flickers on common refresh rate screens even with minimal modulation of pixel intensity. To overcome these challenges, we introduce DeepLight, a system that incorporates machine learning (ML) models in the decoding pipeline to achieve humanly-imperceptible, moderately high SCC rates under diverse real-world conditions. Deep-Light's key innovation is the design of a Deep Neural Network (DNN) based decoder that collectively decodes all the bits spatially encoded in a display frame, without attempting to precisely isolate the pixels associated with each encoded bit. In addition, DeepLight supports imperceptible encoding by selectively modulating the intensity of only the Blue channel, and provides reasonably accurate screen extraction (IoU values >= 83%) by using state-of-the-art object detection DNN pipelines. We show that a fully functional DeepLight system is able to robustly achieve high decoding accuracy (frame error rate < 0.2) and moderately-high data goodput (>=0.95Kbps) using a human-held smartphone camera, even over larger screen-camera distances (approx =2m).